Dear author,
Thanks for developing this package for calling sub-compartments. I was trying to run it on GM12878 dataset but met problems as described below. Maybe you can help with the setting.
My pipeline:
- dump inter-chr matrix at 100Kb:
hic_source='https://hicfiles.s3.amazonaws.com/hiseq/gm12878/in-situ/combined.hic'
hic2sci.sh $hic_source $dir_main/inter_100kb.txt 100000
- run sci
python2.7 -m sci.sci -n GM12878_100kb -f $dir_main/inter_1000kb.txt -r 100000 -g chromosome_sizes/hg19.chrom.sizes -o both -s 1 -k 5
Then I got this error (using a server with 500Gb memory):
Reading inter_100kb_new.txt: 0%| | 149529/577250954 [00:00<57:29, 167287.38it/s]
Traceback (most recent call last):
File "/usr/lib64/python2.7/runpy.py", line 162, in _run_module_as_main
"main", fname, loader, pkg_name)
File "/usr/lib64/python2.7/runpy.py", line 72, in _run_code
exec code in run_globals
File "3.Packages/sci/sci/sci.py", line 112, in
run_sci()
File "/3.Packages/sci/sci/sci.py", line 97, in run_sci
myobject.load_interaction_data(oArgs.infile)
File "sci/hic.py", line 68, in load_interaction_data
start2, end2, count) = line.strip().split()
ValueError: too many values to unpack
Then I dumped the matrix at 1000kb and tried to do the analysis at 1Mb resolution:
python2.7 -m sci.sci -n GM12878_1000kb -f $dir_main/inter_1000kb.txt -r 1000000 -g chromosome_sizes/hg19.chrom.sizes -o both -s 1 -k 5
The compartments I obtained seems to mix up randomly with the one in predictions/GM12878_SCI_sub_compartments.bed
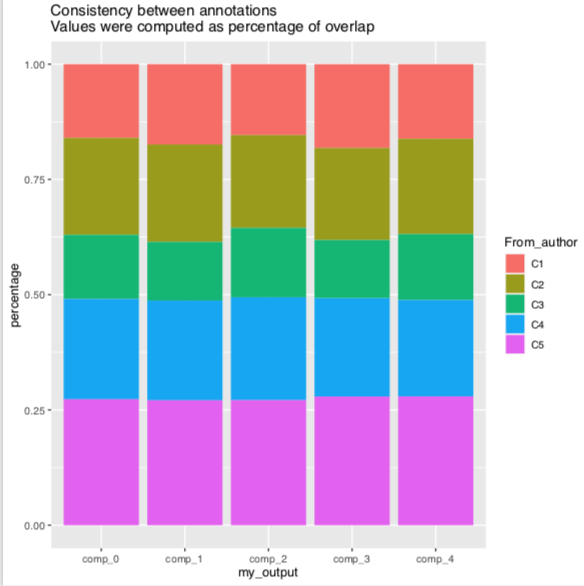
I also tried to find only two compartments, i.e. A and B:
python2.7 -m sci.sci -n GM12878_1000kb -f $dir_main/inter_1000kb.txt -r 1000000 -g chromosome_sizes/hg19.chrom.sizes -o both -s 1 -k 2
Still, the compartments I obtained seems to mix up randomly with the one in predictions/GM12878_SCI_sub_compartments.bed
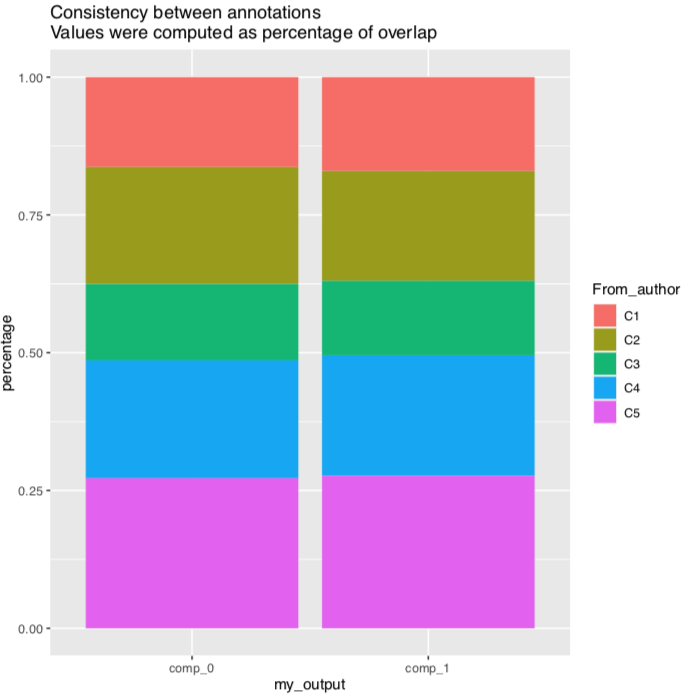
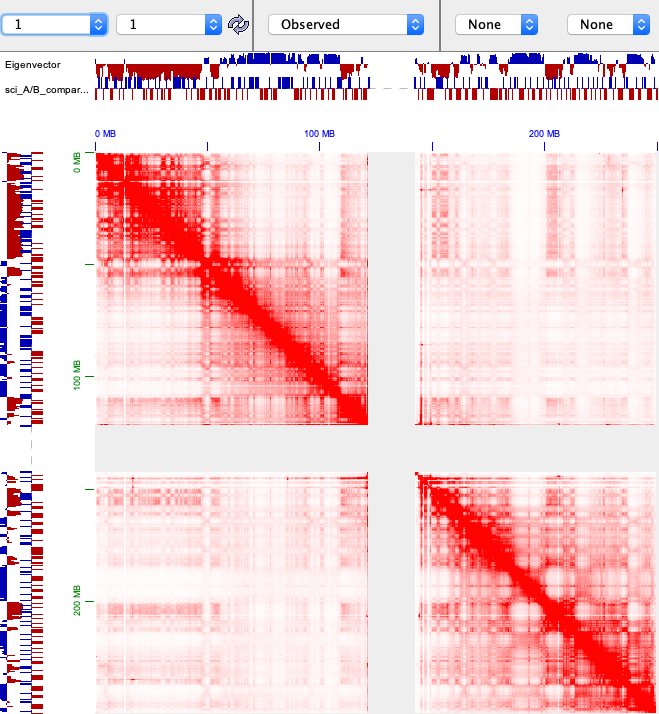
And it is not consistent with the A/B compartment annotated by the eigenvector
Thanks for your help!
Dear author,
Thanks for developing this package for calling sub-compartments. I was trying to run it on GM12878 dataset but met problems as described below. Maybe you can help with the setting.
My pipeline:
Then I got this error (using a server with 500Gb memory):
Then I dumped the matrix at 1000kb and tried to do the analysis at 1Mb resolution:
The compartments I obtained seems to mix up randomly with the one in predictions/GM12878_SCI_sub_compartments.bed
I also tried to find only two compartments, i.e. A and B:
Still, the compartments I obtained seems to mix up randomly with the one in predictions/GM12878_SCI_sub_compartments.bed
And it is not consistent with the A/B compartment annotated by the eigenvector
Thanks for your help!