|
24 | 24 |
|
25 | 25 | ## Agent 的记忆系统是如何设计的? |
26 | 26 |
|
| 27 | + |
| 28 | + |
27 | 29 | 工业界通常将记忆系统划分为两个物理与逻辑隔离的层级:**短期记忆(Session 级)与长期记忆(跨 Session 级)**。 |
28 | 30 |
|
29 | 31 | 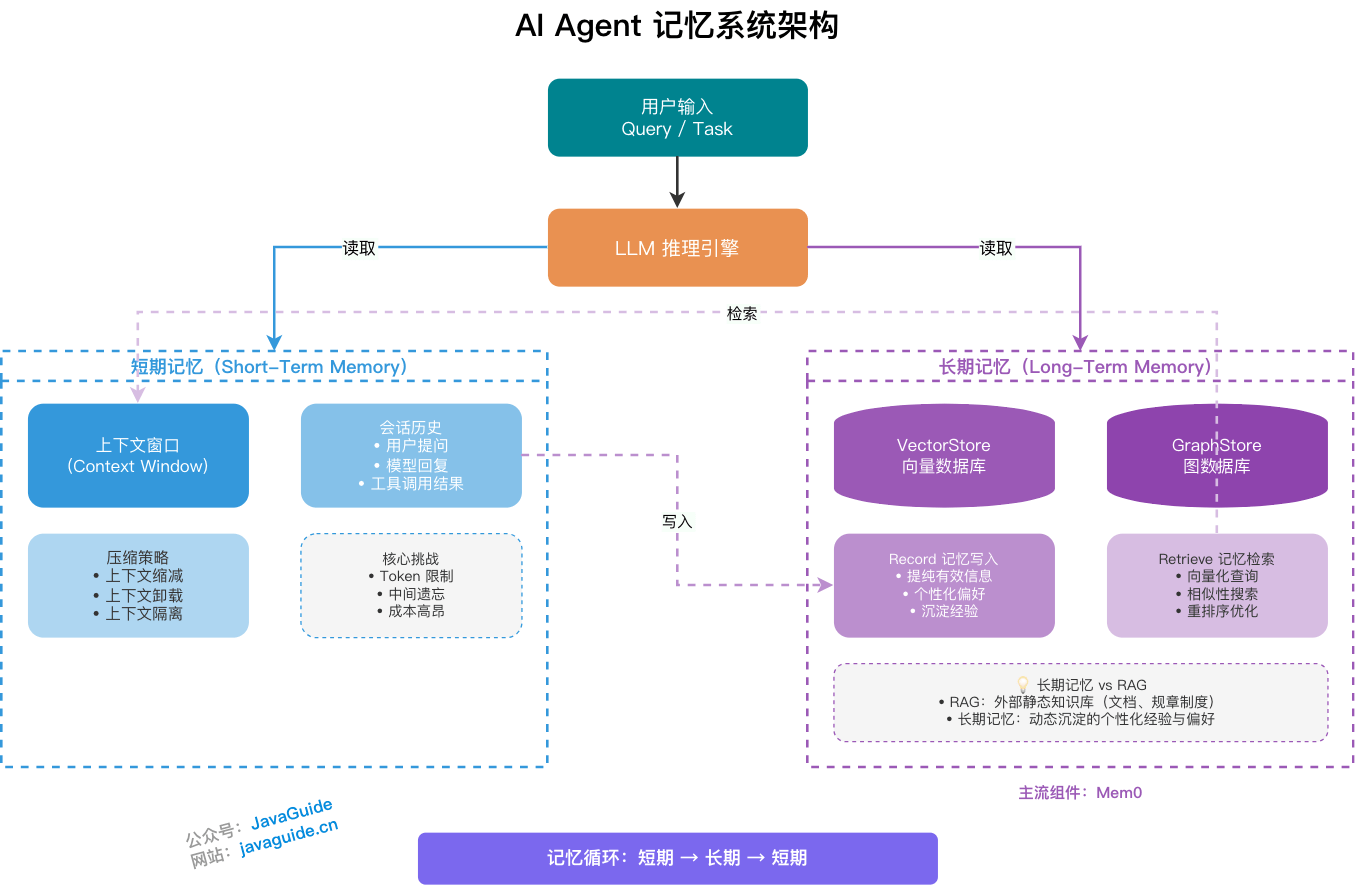 |
@@ -106,6 +108,8 @@ head: |
106 | 108 |
|
107 | 109 | **长期记忆与 RAG(检索增强生成)的区别:** |
108 | 110 |
|
| 111 | + |
| 112 | + |
109 | 113 | 两者底层技术高度相似(均依赖向量库和语义检索),但服务对象不同: |
110 | 114 |
|
111 | 115 | - **RAG** 挂载的是**共享知识源**——公司规章、产品文档、实时数据库查询结果等,与“谁在使用”无关,对所有用户返回同一知识库的内容。其核心特征是**非个性化**,而非一定是静态的。 |
@@ -262,3 +266,218 @@ Agent 不仅仅是被动地记录原始对话,还需要像人类“睡觉” |
262 | 266 | 3. **智能体当前思考什么?**(工作记忆 → 上下文管理) |
263 | 267 |
|
264 | 268 | 这三种能力的协同,使 Agent 从“即时反应”进化为“经验驱动的智能体”——通过结构化的多源信息融合,实现 Prompt + 当前输入 + 历史可用信息的有机组合。 |
| 269 | + |
| 270 | +## ⭐️ Markdown 如何存储 Agent 记忆 |
| 271 | + |
| 272 | +说了这么多向量库、知识图谱、记忆框架,你可能会问:有没有更轻量的方案? |
| 273 | + |
| 274 | +还真有。当你认真审视 Agent 记忆的本质需求时,会发现一个反直觉的答案——**Markdown 文件可能就是最务实的长期记忆载体**。 |
| 275 | + |
| 276 | +### 为什么 Markdown 可以作为 Agent 记忆 |
| 277 | + |
| 278 | +Markdown 本质上是一种人和 Agent 都能读写的“显式长期记忆”。它不依赖数据库、不需要向量引擎、不用配置检索管道。 |
| 279 | + |
| 280 | +核心优势在于**透明、可审查、可版本化、低成本**: |
| 281 | + |
| 282 | +- **透明可审计**:随时打开文件,看得到 Agent 记住了什么、写入了什么。没有任何黑盒。 |
| 283 | +- **持久化**:文件存活于磁盘,不依赖进程生命周期。进程崩溃、重启、换机器,记忆都在。 |
| 284 | +- **版本控制**:记忆可以提交到 Git,回滚、分支、Code Review 随心所欲。 |
| 285 | +- **零迁移成本**:标准格式,无供应商锁定。换模型、换框架,只需迁移文件。 |
| 286 | +- **成本极低**:如果使用托管向量数据库和完整 RAG pipeline,成本和运维复杂度很容易上来;而 Markdown 文件在本地几乎没有额外成本。 |
| 287 | + |
| 288 | +Manus 把文件系统视为结构化的外部记忆;Claude Code 则把 `CLAUDE.md` 和 Auto Memory 明确产品化;OpenClaw 等 Agent 项目/社区实践中,也能看到类似的文件化记忆思路。它们共同说明:在很多 Agent 场景里,文件系统 + Markdown 已经是一个足够务实的长期记忆方案。 |
| 289 | + |
| 290 | +### Claude Code 的 `CLAUDE.md` 机制 |
| 291 | + |
| 292 | +Claude Code 的记忆系统采用双轨制:`CLAUDE.md`(人工编写) 和 **Auto Memory(自动积累)**。 |
| 293 | + |
| 294 | +#### `CLAUDE.md`:该写什么、不该写什么 |
| 295 | + |
| 296 | +> ⚠️ **官方建议**:每个 `CLAUDE.md` 控制在 200 行以内。超过此限制会降低 Claude 的指令遵守率。通过 `@` 引用拆分文件可改善可维护性,但不会减少上下文消耗——被引用文件在启动时全量加载。如果指令超长,应优先使用 `.claude/rules/` 目录的 path-scoped rules,只在编辑匹配路径时才加载对应规则。 |
| 297 | +
|
| 298 | +`CLAUDE.md` 本质上是给 AI 新人写的 onboarding 文档。写得不好还不如不写——一份臃肿的 `CLAUDE.md` 会让真正重要的规则被噪音淹没。 |
| 299 | + |
| 300 | +**该写的东西:** |
| 301 | + |
| 302 | +- **技术栈和版本信息**:框架版本差异往往是 AI 犯错的源头。你不标注 Spring Boot 版本,它会倾向于生成训练数据中更常见的版本用法。 |
| 303 | +- **常用命令**:构建、测试、lint、启动——全部放在代码块里。代码块里的命令 Claude 倾向于照着跑,写在自然语言里的命令它可能根据自己的理解改写。 |
| 304 | +- **架构决策和背后的理由**:光写规则不够,写清楚“为什么”能让 Claude 举一反三。比如“不要直接写 SQL,使用 QueryWrapper”——加上“因为 SQL 审计系统依赖 Wrapper 解析来记录操作日志”之后,Claude 在其他需要生成查询的地方也自觉用 Wrapper。 |
| 305 | +- **团队约定和项目特有的坑**:提交信息格式、分支命名规范、环境变量依赖。这些 Claude 从代码里读不出来,但一个新入职的工程师一定会问。 |
| 306 | + |
| 307 | +**不该写的东西:** |
| 308 | + |
| 309 | +- 代码风格规则(交给格式化工具) |
| 310 | +- 语言或框架的默认行为(现代 Python 用 f-string 这种事写下来是噪音) |
| 311 | +- 大段参考文档(给链接就行,Claude 需要时会自己去读) |
| 312 | + |
| 313 | +> **一句话判断标准**:逐行过一遍 `CLAUDE.md`,每条规则问自己——“如果没有这行,Claude 最近是不是真的犯过这个错”。如果答案是“好像没犯过”,那行就可以删。 |
| 314 | +
|
| 315 | +#### 怎么写才能让 Claude 真正遵守 |
| 316 | + |
| 317 | +**规则要具体可验证**。“注意代码可读性”没法验证;“函数名使用动词开头、单个函数不超过 40 行”可以验证。规则写得越具体,Claude 遵守的概率越高。 |
| 318 | + |
| 319 | +**禁令要搭配替代方案**。只说“不要做 X”会让 Claude 在遇到相关场景时卡住。更好的方式是“不要做 X,遇到这种情况应该做 Y”。实战例子: |
| 320 | + |
| 321 | +```markdown |
| 322 | +# 依赖注入 |
| 323 | + |
| 324 | +- 不要使用 @Autowired 字段注入 |
| 325 | +- 使用构造器注入,配合 Lombok 的 @RequiredArgsConstructor |
| 326 | +- 参考示例:UserController.java 中的写法 |
| 327 | +``` |
| 328 | + |
| 329 | +**善用标记词但别滥用**。如果某条规则 Claude 反复违反,加 `IMPORTANT:` 或 `YOU MUST:` 能引起它的注意。但这招不能经常用——到处标“重要”的文件,等于什么都不重要。 |
| 330 | + |
| 331 | +> **工程提示**:如果 Claude 反复忽略某条规则,不要急着加感叹号。更大的可能是文件太长了,规则被其他内容稀释了。解决方案是精简文件,不是加强调。 |
| 332 | +
|
| 333 | +**标题用常规名字**。用 Commands、Structure、Conventions、Testing 这类在 README 里常见的标题。Claude 训练数据里有大量标准结构的 README,它对“这个标题下面通常写什么”有稳定的预期。 |
| 334 | + |
| 335 | +#### `CLAUDE.md` 文件的层级结构 |
| 336 | + |
| 337 | +| 层级 | 位置 | 作用范围 | 适用场景 | |
| 338 | +| ---------- | ------------------------------------------- | ------------ | -------------------------------------------------------------------------- | |
| 339 | +| **组织级** | 系统目录(如 `/etc/claude-code/CLAUDE.md`) | 所有用户 | 公司编码规范、安全策略,任何设置都无法排除 | |
| 340 | +| **用户级** | `~/.claude/CLAUDE.md` | 个人所有项目 | 代码风格偏好、个人工具习惯 | |
| 341 | +| **项目级** | `./CLAUDE.md` 或 `./.claude/CLAUDE.md` | 团队共享 | 项目架构、编码标准、工作流,提交至 Git | |
| 342 | +| **本地级** | `./CLAUDE.local.md` | 个人当前项目 | 沙箱 URL、测试数据偏好,需手动加入 `.gitignore`(运行 `/init` 可自动添加) | |
| 343 | + |
| 344 | +文件加载遵循目录树向上查找规则——从当前工作目录逐级向上,同一目录内 `CLAUDE.local.md` 追加在 `CLAUDE.md` 之后,越靠近工作目录的规则优先级越高。 |
| 345 | + |
| 346 | +**`CLAUDE.md` 不适合存什么:** |
| 347 | + |
| 348 | +- 大段日志和完整对话记录 |
| 349 | +- 敏感密钥、Token、账号信息 |
| 350 | +- 高频变化的运行时数据 |
| 351 | +- 可以实时查询的动态信息 |
| 352 | + |
| 353 | +**分层管理:项目大了怎么组织** |
| 354 | + |
| 355 | +一个人的项目,一份 `CLAUDE.md` 够用。项目一大、团队一介入,就需要分层: |
| 356 | + |
| 357 | +```markdown |
| 358 | +# `CLAUDE.md`(项目根目录) |
| 359 | + |
| 360 | +## Project |
| 361 | + |
| 362 | +Spring Boot 3.2 + MyBatis-Plus + MySQL 8.0 的订单管理服务。 |
| 363 | + |
| 364 | +## Commands |
| 365 | + |
| 366 | +- 构建:`mvn clean package` |
| 367 | +- 测试:`mvn test` |
| 368 | + |
| 369 | +## Rules |
| 370 | + |
| 371 | +- API 约定:@docs/api-conventions.md |
| 372 | +- 数据库规范:@docs/database-rules.md |
| 373 | +``` |
| 374 | + |
| 375 | +用 `@path/to/file` 引用外部文件。 |
| 376 | + |
| 377 | +> ⚠️ **使用注意**:`@` 引用支持最多 **5 层递归深度**。首次在项目中使用外部引用时,Claude Code 会弹出审批对话框——如果误拒,引用将被永久禁用(需手动重置)。`@` 引用会把整个文件内容嵌入上下文,被引用文件在启动时全量加载,不会减少上下文消耗。 |
| 378 | +
|
| 379 | +对于更细粒度的控制,可以用 `.claude/rules/` 目录组织 **path-scoped rules**。这是与 `@` 引用的本质区别:rules 仅在匹配到指定路径时才加载(按需加载),而 `@` 引用在启动时全量加载。适用场景:当规则只针对特定文件或目录时(如后端 API 规范、测试配置),优先使用 rules 而非在 CLAUDE.md 中堆砌。 |
| 380 | + |
| 381 | +```yaml |
| 382 | +--- |
| 383 | +paths: |
| 384 | + - "src/main/java/**/controller/**/*.java" |
| 385 | +--- |
| 386 | +# Controller 规范 |
| 387 | +- 统一使用 Result<T> 包装返回值 |
| 388 | +- 所有接口必须添加 Swagger 注解 |
| 389 | +``` |
| 390 | +
|
| 391 | +这样编辑 Controller 时只加载 Controller 的规则,编辑 Service 时只加载 Service 的规则。 |
| 392 | +
|
| 393 | +> **AGENTS.md 与 CLAUDE.md 的关系**:Claude Code 读取 `CLAUDE.md` 而非 `AGENTS.md`(跨工具开放标准,被 OpenAI Codex、Cursor 等采用)。如果仓库已使用 AGENTS.md 供其他编码 Agent 使用,可以创建导入 AGENTS.md 的 `CLAUDE.md`,让两个工具读取相同指令而无需重复维护: |
| 394 | +> |
| 395 | +> ```markdown |
| 396 | +> @AGENTS.md |
| 397 | +> |
| 398 | +> ## Claude Code 特定指令 |
| 399 | +> |
| 400 | +> - 使用 plan mode 处理 `src/billing/` 下的改动 |
| 401 | +> ``` |
| 402 | + |
| 403 | +**Auto Memory(自动积累)**:Claude 根据对话自动写入的笔记,包括调试模式、代码习惯、工作流偏好。它存在 `~/.claude/projects/<project>/memory/` 目录下,`MEMORY.md` 是入口文件,细节笔记在子文件中。 |
| 404 | + |
| 405 | +> ⚠️ **使用注意**: |
| 406 | +> |
| 407 | +> 1. **MEMORY.md 加载限制**:仅加载前 200 行或 25KB 的内容,超出部分不会被读取。Claude 会将详细内容拆分到 Topic 文件中。 |
| 408 | +> 2. **退化问题**:经过 20-30 个会话后,Auto Memory 笔记质量可能下降(矛盾条目、过时信息累积)。社区有 dream-skill 等工具可执行记忆整合(4 阶段:Orient → Gather Signal → Consolidate → Prune),但这非官方正式功能。 |
| 409 | +> 3. **禁用方式**:除了 `/memory` 切换和 `autoMemoryEnabled` 配置,还可通过环境变量 `CLAUDE_CODE_DISABLE_AUTO_MEMORY=1` 禁用。**CI/CD 场景推荐使用此方式**,因为自动化管线不需要 Claude 积累构建环境的笔记。 |
| 410 | + |
| 411 | +注意:Auto Memory 需要 Claude Code v2.1.59+,默认开启。 |
| 412 | + |
| 413 | +### Markdown 记忆的层级设计 |
| 414 | + |
| 415 | +一个完整的 Markdown 记忆体系通常包含多个层级: |
| 416 | + |
| 417 | +- **用户级记忆**:存个人偏好和长期习惯,放在 `~/.claude/CLAUDE.md`。比如你偏好用 2-space 缩进、习惯先写测试再写代码、不喜欢用 emoji。 |
| 418 | +- **项目级记忆**:存项目规范、技术栈、目录结构,放在仓库根目录的 `CLAUDE.md`。团队成员共享,通过 Git 同步。 |
| 419 | +- **子目录级记忆**:存局部模块的专属规则,放在子目录的 `CLAUDE.md`。比如 `backend/` 下的 API 设计规范、`docs/` 下的写作风格要求。 |
| 420 | +- **团队共享记忆**:需要提交到仓库的共同约定。项目级的 `CLAUDE.md` 和 `.claude/rules/` 目录下可版本化的规则文件。 |
| 421 | +- **私有记忆**:不应该提交的个人工作流。`CLAUDE.local.md` 这类文件加入 `.gitignore`,只存在本地。 |
| 422 | + |
| 423 | +### Markdown 记忆和传统长期记忆的适用边界 |
| 424 | + |
| 425 | + |
| 426 | + |
| 427 | +不是所有场景都适合 Markdown,也不是所有场景都适合向量库。关键在于理解各自的适用边界: |
| 428 | + |
| 429 | +| 维度 | Markdown 记忆 | 向量库记忆 | RAG 知识库 | 数据库型框架(Mem0等) | |
| 430 | +| -------------- | ---------------------------------------- | -------------------- | -------------------- | ---------------------- | |
| 431 | +| **检索精度** | 全量注入(无检索机制,启动时全部加载) | 高(语义相似度) | 高(语义检索) | 高(混合策略) | |
| 432 | +| **上下文成本** | 与文件大小线性相关,大文件会挤占工作空间 | 按需检索,上下文高效 | 按需检索,上下文高效 | 按需检索,上下文高效 | |
| 433 | +| **调试体验** | **极佳**:直接读写文件 | 中等:需向量查询工具 | 中等:需检索日志 | 复杂:需理解框架逻辑 | |
| 434 | +| **部署成本** | **极低**:只需文件读写 | 高:需维护向量服务 | 高:需 RAG pipeline | 高:需框架运行时 | |
| 435 | +| **版本控制** | **原生集成** Git | 需额外同步机制 | 需额外同步机制 | 需额外同步机制 | |
| 436 | +| **迁移成本** | **零**:复制文件即可 | 高:锁定专有格式 | 高:锁定 pipeline | 极高:绑定框架 | |
| 437 | +| **适用场景** | 偏好、约定、踩坑记录 | 多样化记忆检索 | 共享知识查询 | 复杂多源记忆管理 | |
| 438 | + |
| 439 | +Markdown 的局限性也很明确:当你需要从海量非结构化文本中检索特定片段时,人工组织的 Markdown 会成为瓶颈。此时向量库的语义检索能力不可替代。 |
| 440 | + |
| 441 | +反过来,当你的记忆需求是“记住这个项目的编码规范”、“记住用户的报告偏好”这类明确、可结构化的信息时,Markdown 的简洁和可维护性完胜复杂系统。 |
| 442 | + |
| 443 | +### Markdown 记忆的维护策略 |
| 444 | + |
| 445 | +这里以 `CLAUDE.md` 为例。 |
| 446 | + |
| 447 | +`CLAUDE.md`不是写完就完事的。项目在演进,规则也会过时。 |
| 448 | + |
| 449 | +- **添加规则要慢**:一条新规则只有在 Claude 确实犯了一个错误、且这条规则能防止同类错误再次发生时,才值得写进去。为还没发生过的事预设规则,往往是在浪费空间。 |
| 450 | +- **删规则要果断**:如果某条规则存在很久了,但删掉后 Claude 的行为没有变化,说明这条规则从一开始就没起作用——Claude 本来就会这么做。果断移除,把空间留给真正需要的规则。 |
| 451 | +- **错误驱动的持续进化**:每次纠正 Claude 的错误后,追加一句“更新 `CLAUDE.md`,确保下次不再犯”。累积几次同类错误后归纳为一条精炼的规则,避免文件快速膨胀。 |
| 452 | + |
| 453 | +**两个预警信号:** |
| 454 | + |
| 455 | +- **信号一**:Claude 为已经写在文件里的规则道歉(比如“抱歉,我刚才忽略了 XX 规则”)。这说明这条规则的措辞有问题——换个更直接的表述。 |
| 456 | +- **信号二**:同一条规则在不同会话中反复被违反。这通常不是措辞问题,而是整份文件太长了,规则被稀释了。解决方案不是改措辞,而是压缩整份文件。 |
| 457 | + |
| 458 | +**两个实用的维护习惯:** |
| 459 | + |
| 460 | +- **对话式审查**:每隔几周,找几个 `CLAUDE.md` 里的规则问 Claude:”如果我删掉这条规则,你会改变行为吗?”如果它说不会,那这条规则可能就可以删。 |
| 461 | + |
| 462 | + > 这种对话式审查可作为粗略的启发式方法,但不要完全依赖 Claude 的自我评估。Claude 无法准确预测在缺少某条规则时自己是否会改变行为。更可靠的做法是:先备份规则,实际删除后在几个真实任务上观察行为是否变化。 |
| 463 | + |
| 464 | +- **用 `/init` 但别直接用**:自动生成的 `CLAUDE.md` 是一个合理的起点,但里面可能包含对项目不准确的描述。按原则逐条审查,删掉冗余、补上遗漏。 |
| 465 | + |
| 466 | +**Git 做版本追踪 + Code Review**:每一次重要记忆更新都 commit,遇到问题可以回滚,code review 可以追溯修改原因。团队共享内容的修改应该走 PR 流程。 |
| 467 | + |
| 468 | +## 总结 |
| 469 | + |
| 470 | +Agent 记忆系统解决的核心问题是:**让 Agent 从无状态的“一次性工具”进化为有上下文的“长期协作伙伴”**。 |
| 471 | + |
| 472 | +短期记忆依托上下文窗口,通过**上下文缩减、卸载、隔离**三类工程策略控制膨胀。长期记忆则通过“写入-检索”的双向机制,在新的 Session 中恢复历史沉淀的个性化经验。 |
| 473 | + |
| 474 | +**本文的核心要点回顾:** |
| 475 | + |
| 476 | +1. **记忆的两个层级**:短期记忆(Session 级,利用上下文窗口)和长期记忆(跨 Session 级,通过向量库或文件持久化) |
| 477 | +2. **记忆的生命周期**:编码 → 存储 → 提取 → 巩固 → 反思 → 遗忘。记忆系统不是只写不删,而是需要主动的代谢机制 |
| 478 | +3. **技术选型看场景**:向量库适合海量非结构化检索,Markdown 适合偏好、约定、踩坑这类明确可结构化的信息。两者不是替代关系,而是协作关系 |
| 479 | +4. **Claude Code 的双轨记忆**:`CLAUDE.md`(人工编写)和 Auto Memory(自动积累)各司其职,前者是你主动的指令,后者是 Claude 自学的笔记 |
| 480 | +5. **`CLAUDE.md` 的核心原则**:写什么比怎么写更重要——只记录“Claude 真的犯过这个错”的规则;怎么写比写什么更重要——具体可验证、禁令搭配替代方案、别滥用标记词 |
| 481 | +6. **维护是持续的过程**:添加要慢、删除要果断、错误驱动进化。定期用对话式审查检验规则的有效性 |
| 482 | + |
| 483 | +一个设计良好的记忆系统,能让 Agent 回答三个核心问题:**智能体知道什么(事实记忆)、智能体如何改进(经验记忆)、智能体当前思考什么(工作记忆)**。这三种能力的协同,才是“记忆”的完整含义。 |
0 commit comments