diff --git a/README.md b/README.md
index 02bb83311..d18d93f72 100644
--- a/README.md
+++ b/README.md
@@ -58,11 +58,12 @@ swa start _site
2. **Generates language manifest** - Creates `metadata/languages.json` for runtime language switching
3. **Syncs content** - Copies English source to `localizedContent/en/`. For other languages, only shared directories (assets, api) are synced by default since Crowdin manages translations. Use `--sync` to enable full English fallback for missing/outdated translations (useful for local development).
4. **Normalizes DocFX alerts** - Runs `normalize-localized-alerts.py` on each non-English language to repair Crowdin-collapsed Note/Tip/etc. alerts before building (see [DocFX Alerts and Translations](#docfx-alerts-and-translations))
-5. **Builds documentation** - Runs DocFX for each requested language
-6. **Fixes API docs** - Patches xref links in generated API documentation
-7. **Copies API docs** - Shares English API docs with localized sites
-8. **Injects SEO tags** - Adds hreflang and canonical tags to HTML files
-9. **Generates SWA config** - Creates `staticwebapp.config.json` for Azure Static Web Apps routing
+5. **Stabilizes heading anchors** - Runs `normalize-localized-heading-anchors.py` on each non-English language to inject English-slug bookmark anchors before translated headings, so `#anchor` cross-references resolve even when the heading text is translated (see [Bookmark Links and Translations](#bookmark-links-and-translations))
+6. **Builds documentation** - Runs DocFX for each requested language
+7. **Fixes API docs** - Patches xref links in generated API documentation
+8. **Copies API docs** - Shares English API docs with localized sites
+9. **Injects SEO tags** - Adds hreflang and canonical tags to HTML files
+10. **Generates SWA config** - Creates `staticwebapp.config.json` for Azure Static Web Apps routing
# Project Structure
@@ -75,7 +76,8 @@ TEDoc/
│ ├── gen_staticwebapp_config.py
│ ├── inject_seo_tags.py
│ ├── sync-localized-content.py
-│ └── normalize-localized-alerts.py # Repairs Crowdin-collapsed DocFX alerts
+│ ├── normalize-localized-alerts.py # Repairs Crowdin-collapsed DocFX alerts
+│ └── normalize-localized-heading-anchors.py # Injects English-slug bookmark anchors into translations
├── content/ # English source content (tracked in git)
│ └── _ui-strings.json # English UI strings (header, footer, banners)
├── localizedContent/ # Build directories for all languages
@@ -108,16 +110,37 @@ TEDoc/
# Bookmark Links and Translations
-When linking to a specific heading within a page (e.g., `#my-heading`), the anchor ID is auto-generated from the heading text. When headings are translated by Crowdin, the anchor changes, breaking bookmark links.
+When linking to a specific heading within a page (e.g., `#my-heading`), DocFX auto-generates the anchor ID from the heading **text**. Because Crowdin translates that text, the generated anchor changes per language (`#model-io` becomes `#es-del-modelo`, etc.), so a hardcoded English `#anchor` link breaks in every translated page and DocFX logs an `InvalidBookmark` warning. English builds stay clean because the anchors match there.
-To prevent this, add an `` tag above any heading that is referenced by a bookmark link:
+## Automatic anchor stabilization (the build handles this)
+
+`build_scripts/normalize-localized-heading-anchors.py` neutralizes this whole class of warning automatically. For each localized page it reads the matching English source, computes each heading's English slug, and injects a hidden bookmark anchor carrying that slug immediately before the corresponding translated heading:
```markdown
-
-## My Heading
+
+## E/S del modelo
+```
+
+DocFX accepts the injected `id` as a valid bookmark, so `#model-io` resolves and the link lands on the right section while the heading keeps its translated text. Headings are aligned to the English source positionally (Crowdin preserves heading structure); if the heading counts differ, the file is skipped and reported rather than risk a misaligned anchor. The script is idempotent (it strips its own `data-loc-xref` anchors before recomputing) and never modifies English.
+
+The build runs it automatically for each non-English language before DocFX (step 5 of [What the Build Script Does](#what-the-build-script-does)). You can also run it manually after a Crowdin pull:
+
+```bash
+python build_scripts/normalize-localized-heading-anchors.py # all languages
+python build_scripts/normalize-localized-heading-anchors.py --dry-run # preview without writing
+python build_scripts/normalize-localized-heading-anchors.py --check # exit 1 if changes are needed (CI)
+python build_scripts/normalize-localized-heading-anchors.py es # a single language
```
-Crowdin does not translate HTML `name` attributes, so the anchor remains stable across all languages. Only add these to headings that are actually linked to — there is no need to add them to every heading.
+## Authoring guidance
+
+- **Prefer the bracketed link form** `[text](xref:uid#anchor)` over the bare `@uid#anchor` autolink. The closing `)` delimits the anchor, so trailing punctuation in any language can never leak into it.
+- **For a rename-proof anchor**, add an explicit `` tag above the heading. Crowdin does not translate HTML `name` attributes, so the anchor stays stable across all languages *and* survives English heading renames — unlike an auto-generated slug. Only add these to headings actually linked to; there is no need to add them everywhere.
+
+ ```markdown
+
+ ## My Heading
+ ```
# DocFX Alerts and Translations
diff --git a/build-docs.py b/build-docs.py
index 87dd2b6b7..7140892c9 100644
--- a/build-docs.py
+++ b/build-docs.py
@@ -135,10 +135,20 @@ def prepare_localized_content(lang: str, sync: bool = False) -> int:
# Repair Crowdin-collapsed DocFX alerts (e.g. "> [!NOTE]> text") before docfx
# builds this language, so alerts render as styled boxes instead of plain quotes.
- return run_command(
+ result = run_command(
[sys.executable, "build_scripts/normalize-localized-alerts.py", lang],
f"Normalizing DocFX alerts for {lang}"
)
+ if result != 0:
+ return result
+
+ # Stabilize heading anchors: inject English-slug bookmark anchors before
+ # translated headings so cross-reference links (#anchor) resolve even though
+ # the heading text is translated. Prevents InvalidBookmark warnings.
+ return run_command(
+ [sys.executable, "build_scripts/normalize-localized-heading-anchors.py", lang],
+ f"Stabilizing heading anchors for {lang}"
+ )
def build_language(lang: str, sync: bool = False) -> int:
diff --git a/build_scripts/normalize-localized-heading-anchors.py b/build_scripts/normalize-localized-heading-anchors.py
new file mode 100644
index 000000000..0e247e02d
--- /dev/null
+++ b/build_scripts/normalize-localized-heading-anchors.py
@@ -0,0 +1,263 @@
+#!/usr/bin/env python
+# -*- coding: utf-8 -*-
+"""
+Stabilize DocFX heading anchors across translated content.
+
+DocFX derives a heading's anchor (its HTML id) from the heading *text*. Cross
+references hardcode the English anchor, e.g. `[..](xref:te-cli-commands#model-io)`
+or ``. When a heading is translated the generated
+slug changes ("Model I/O" -> "model-io" becomes "E/S del modelo" ->
+"es-del-modelo"), so every English `#anchor` link breaks in es/zh and DocFX emits
+an `InvalidBookmark` warning. English builds stay clean because the anchors match
+there.
+
+This script makes the *English* anchor resolvable in every translated page. For
+each localized page it reads the matching English source file, computes each
+heading's English DocFX slug, and injects a hidden bookmark anchor carrying that
+slug immediately before the corresponding translated heading:
+
+
+ ## E/S del modelo
+
+DocFX accepts the injected `id` as a valid bookmark, so `#model-io` resolves and
+the link lands on the right section, while the heading keeps its translated text.
+This neutralizes the whole class of warning for current and future pages without
+touching translations.
+
+Headings are aligned to the English source positionally (Crowdin preserves
+heading structure). If the heading count differs (a translation added/removed a
+heading, or is stale), the file is skipped and reported rather than risk a
+misaligned anchor. Frontmatter and fenced code blocks are skipped. Injected
+anchors are tagged `data-loc-xref` so the script is idempotent: it strips its own
+prior anchors before recomputing.
+
+English (`en`) is never modified - it is the source of the slugs.
+
+Usage:
+ python normalize-localized-heading-anchors.py # all languages (except en)
+ python normalize-localized-heading-anchors.py --dry-run # preview only
+ python normalize-localized-heading-anchors.py --check # exit 1 if changes needed (CI)
+ python normalize-localized-heading-anchors.py es # only Spanish
+"""
+
+import argparse
+import re
+import sys
+from pathlib import Path
+
+TEDOC_ROOT = Path(__file__).resolve().parent.parent
+LOCALIZED_DIR = TEDOC_ROOT / "localizedContent"
+
+FENCE_RE = re.compile(r"^\s*(`{3,}|~{3,})(.*)$")
+HEADING_RE = re.compile(r"^(#{1,6})\s+(.*?)\s*#*\s*$")
+# A bookmark anchor this script previously injected.
+INJECTED_RE = re.compile(r'^$')
+# Inline markdown to strip from heading text before slugifying.
+MD_LINK_RE = re.compile(r"\[([^\]]*)\]\([^)]*\)")
+
+
+def slugify(text: str) -> str:
+ """Replicate DocFX/markdig heading-id generation.
+
+ Verified against DocFX 2.78 output: lowercase; drop every character that is
+ not a Unicode letter/digit/hyphen/underscore; turn each space into a single
+ hyphen (consecutive spaces are NOT collapsed, e.g. "Connection & Auth" ->
+ "connection--auth"); Unicode letters (incl. CJK) are preserved verbatim.
+ """
+ # Strip inline markdown so the text matches what DocFX renders.
+ text = MD_LINK_RE.sub(r"\1", text)
+ text = text.replace("`", "")
+ text = re.sub(r"(\*\*|__|\*|~~)", "", text)
+ text = text.strip().lower()
+ out = []
+ for ch in text:
+ if ch == " " or ch == "\t":
+ out.append("-")
+ elif ch.isalnum() or ch in "-_":
+ out.append(ch)
+ # everything else (punctuation, symbols) is dropped
+ return "".join(out)
+
+
+def parse_headings(text: str):
+ """Return (heading_texts, heading_line_indices, heading_levels) for ATX
+ headings, skipping YAML frontmatter and fenced code blocks. Indices refer to
+ `text.split(nl)`; levels are the heading depth (1 for '#', 2 for '##', ...)."""
+ lines = text.split("\n")
+ texts, indices, levels = [], [], []
+ fence_char, fence_len = "", 0
+ in_frontmatter = False
+ for i, raw in enumerate(lines):
+ line = raw.rstrip("\r")
+ # YAML frontmatter delimited by leading '---' on the very first line.
+ if i == 0 and line.strip() == "---":
+ in_frontmatter = True
+ continue
+ if in_frontmatter:
+ if line.strip() in ("---", "..."):
+ in_frontmatter = False
+ continue
+ fence = FENCE_RE.match(line)
+ if fence:
+ run, tail = fence.group(1), fence.group(2)
+ char, length = run[0], len(run)
+ if not fence_char:
+ fence_char, fence_len = char, length
+ elif char == fence_char and length >= fence_len and not tail.strip():
+ fence_char, fence_len = "", 0
+ continue
+ if fence_char:
+ continue
+ m = HEADING_RE.match(line)
+ if m:
+ texts.append(m.group(2))
+ indices.append(i)
+ levels.append(len(m.group(1)))
+ return texts, indices, levels
+
+
+def dedup_slugs(texts):
+ """Compute slugs with DocFX-style collision suffixes (-1, -2, ...)."""
+ seen = {}
+ slugs = []
+ for t in texts:
+ s = slugify(t)
+ if s in seen:
+ seen[s] += 1
+ s = f"{s}-{seen[s]}"
+ else:
+ seen[s] = 0
+ slugs.append(s)
+ return slugs
+
+
+def english_source_for(loc_path: Path, lang: str) -> Path:
+ """Map localizedContent//content/.../x.md -> content/.../x.md."""
+ rel = loc_path.relative_to(LOCALIZED_DIR / lang) # e.g. content/features/x.md
+ return TEDOC_ROOT / rel
+
+
+def process_file(loc_path: Path, lang: str, dry_run: bool):
+ """Inject English-slug anchors before translated headings. Returns one of:
+ ('ok', n_injected) | ('skip-no-source', 0) | ('skip-mismatch', (en, loc))."""
+ with open(loc_path, "r", encoding="utf-8", newline="") as f:
+ text = f.read()
+ newline = "\r\n" if "\r\n" in text else "\n"
+ norm = text.replace("\r\n", "\n")
+ had_bom = norm.startswith("\ufeff")
+ if had_bom:
+ norm = norm[1:]
+
+ # Idempotency: drop previously injected anchors before recomputing.
+ cleaned_lines = [ln for ln in norm.split("\n") if not INJECTED_RE.match(ln)]
+
+ en_path = english_source_for(loc_path, lang)
+ if not en_path.exists():
+ return ("skip-no-source", 0)
+
+ with open(en_path, "r", encoding="utf-8-sig", newline="") as f:
+ en_text = f.read().replace("\r\n", "\n")
+ en_texts, _, _ = parse_headings(en_text)
+ loc_texts, loc_indices, loc_levels = parse_headings("\n".join(cleaned_lines))
+
+ if len(en_texts) != len(loc_texts):
+ # Still write back the cleaned file (stale anchors removed) so we never
+ # leave a misaligned anchor behind, but inject nothing.
+ rebuilt = newline.join(cleaned_lines)
+ if had_bom:
+ rebuilt = "\ufeff" + rebuilt
+ if rebuilt != text and not dry_run:
+ with open(loc_path, "w", encoding="utf-8", newline="") as f:
+ f.write(rebuilt)
+ return ("skip-mismatch", (len(en_texts), len(loc_texts)))
+
+ en_slugs = dedup_slugs(en_texts)
+ # Skip level-1 headings: DocFX lifts the first into the page title
+ # (rawTitle) only when the is the leading element. An injected anchor
+ # renders as a
ahead of the
, so DocFX no longer treats it as the
+ # title and the heading drops below the metadata block. The page title's own
+ # anchor is never cross-referenced (callers use the uid), so dropping it is
+ # safe. Positional slug alignment is unaffected; we only omit the injection.
+ inject_at = {
+ idx: slug
+ for idx, slug, level in zip(loc_indices, en_slugs, loc_levels)
+ if level != 1
+ }
+
+ out = []
+ for i, ln in enumerate(cleaned_lines):
+ if i in inject_at:
+ out.append(f'')
+ out.append(ln)
+ rebuilt = newline.join(out)
+ if had_bom:
+ rebuilt = "\ufeff" + rebuilt
+
+ changed = rebuilt != text
+ if changed and not dry_run:
+ with open(loc_path, "w", encoding="utf-8", newline="") as f:
+ f.write(rebuilt)
+ return ("ok", len(inject_at) if changed else 0)
+
+
+def iter_languages(lang):
+ if lang:
+ return [lang] if lang != "en" else []
+ if not LOCALIZED_DIR.exists():
+ return []
+ return sorted(
+ d.name for d in LOCALIZED_DIR.iterdir()
+ if d.is_dir() and d.name != "en"
+ )
+
+
+def main() -> int:
+ ap = argparse.ArgumentParser(
+ description="Inject English heading-slug bookmark anchors into translated pages."
+ )
+ ap.add_argument("lang", nargs="?", help="Language code (default: all except en)")
+ ap.add_argument("--dry-run", action="store_true", help="Preview without writing")
+ ap.add_argument("--check", action="store_true",
+ help="Exit 1 if any file needs changes (implies --dry-run). For CI.")
+ args = ap.parse_args()
+ dry_run = args.dry_run or args.check
+
+ if not LOCALIZED_DIR.exists():
+ print(f"Error: {LOCALIZED_DIR} not found.")
+ return 1
+
+ total_files = total_anchors = changed_files = mismatches = 0
+ for lang in iter_languages(args.lang):
+ base = LOCALIZED_DIR / lang
+ if not base.exists():
+ continue
+ for path in sorted(base.rglob("*.md")):
+ if path.name == "toc.md":
+ continue # navigation files use '## @uid' lines, not real headings
+ status, info = process_file(path, lang, dry_run)
+ total_files += 1
+ rel = path.relative_to(LOCALIZED_DIR)
+ if status == "skip-mismatch":
+ mismatches += 1
+ en_n, loc_n = info
+ print(f" SKIP (heading count {en_n} en vs {loc_n} loc): {rel}")
+ elif status == "ok" and info:
+ changed_files += 1
+ total_anchors += info
+
+ verb = "Would inject" if dry_run else "Injected"
+ print(f"\n{verb} {total_anchors} heading anchor(s) across {changed_files} file(s); "
+ f"{mismatches} file(s) skipped on heading-count mismatch; "
+ f"{total_files} file(s) scanned.")
+
+ if args.check and (changed_files or mismatches):
+ return 1
+ return 0
+
+
+if __name__ == "__main__":
+ try:
+ sys.exit(main())
+ except KeyboardInterrupt:
+ print("\nInterrupted.")
+ sys.exit(1)
diff --git a/content/features/Semantic-Model/direct-query-over-as.md b/content/features/Semantic-Model/direct-query-over-as.md
index f7a779282..9f0d50abd 100644
--- a/content/features/Semantic-Model/direct-query-over-as.md
+++ b/content/features/Semantic-Model/direct-query-over-as.md
@@ -17,6 +17,8 @@ applies_to:
full: true
---
+# Direct Query over Analysis Services
+
## Overview
Tabular Editor 3 can **connect** to composite models that leverage **DirectQuery over Analysis Services (DQ‑over‑AS)**, but full modeling support is **not yet available**. Most authoring tasks work as expected; however, operations that rely on synchronising metadata with the remote semantic model—such as *Update table schema*—are currently limited.
diff --git a/content/features/Workspace-Database.md b/content/features/Workspace-Database.md
index 4bed36533..1a66769bc 100644
--- a/content/features/Workspace-Database.md
+++ b/content/features/Workspace-Database.md
@@ -16,7 +16,7 @@ applies_to:
- edition: Enterprise
full: true
---
-## Introducing Workspace Databases
+# Introducing Workspace Databases
Tabular Editor 3.0 supports editing model metadata loaded from disk with a simultaneous connection to a database deployed to an instance of Analysis Services. We call this database the _workspace database_. Going forward, this is the recommended approach to tabular modeling within Tabular Editor.
This makes the development workflow a lot simpler, since you only need to hit Save (Ctrl+S) once, to simultaneously save your changes to the disk **and** update the metadata in the workspace database. This also has the advantage, that any error messages returned from Analysis Services, are immediately visible in Tabular Editor upon hitting Save. In a sense, this is similar to the way SSDT / Visual Studio or Power BI Desktop does, except that you are in control of when the workspace database is updated.
diff --git a/content/features/code-actions.md b/content/features/code-actions.md
index a531b54b5..a7d72c1a7 100644
--- a/content/features/code-actions.md
+++ b/content/features/code-actions.md
@@ -74,7 +74,6 @@ In the screenshot below, for example, the **Prefix variable with '_'** action ca

-
## List of Code Actions
The table below lists all currently available Code Actions. You can toggle off Code Actions in the **Tools > Preferences** dialog under **Text Editors > DAX Editor > Code Actions** (a future update will let you toggle individual actions for a more customized experience). Some Code Actions also have additional configuration options, such as which prefix to use for variable names.
diff --git a/content/features/csharp-scripts.md b/content/features/csharp-scripts.md
index dc66612b3..539c3ddea 100644
--- a/content/features/csharp-scripts.md
+++ b/content/features/csharp-scripts.md
@@ -284,7 +284,6 @@ In addition, the following .NET Framework assemblies are loaded by default:
- TabularEditor.Exe
- Microsoft.AnalysisServices.Tabular.Dll
-
## Accessing Environment Variables
When running C# scripts via the Tabular Editor CLI (especially in CI/CD pipelines), you can pass parameters to your scripts using environment variables. This is the recommended approach, as C# scripts executed by Tabular Editor CLI don't support traditional command-line arguments.
@@ -365,7 +364,6 @@ foreach(var table in Model.Tables)
Info($"Configured model for {environment} environment");
```
-
## Compatibility
The scripting APIs for Tabular Editor 2, Tabular Editor 3 (Desktop), and the Tabular Editor CLI are mostly compatible, but there are cases where you want to conditionally compile code depending on which host is running. The CLI host defines a `TECLI` preprocessor symbol; TE3 Desktop defines `TE3` (and version-bracketed symbols like `TE3_3_15_OR_GREATER` for the active minor); TE2 defines neither. Preprocessor directives were introduced in Tabular Editor 3.10.0. Use them to write portable scripts:
diff --git a/content/features/dax-debugger.md b/content/features/dax-debugger.md
index 1d00323de..6815748fb 100644
--- a/content/features/dax-debugger.md
+++ b/content/features/dax-debugger.md
@@ -79,7 +79,6 @@ The debugger provides the following views (if they are hidden, they can be acces
- Evaluation Context
- Call Tree
-
## Locals
This view lists the columns, measures and variables within the current scope of execution and displays their values. It also displays the value of the current subexpression being debugged. Values in this list are updated automatically when stepping to a different subexpression, or when the evaluation context is changed. **Local values are always evaluated at the currently selected item of the call tree**.
@@ -145,7 +144,6 @@ Notice how the values in the **Locals** view are updated as the tree is navigate

-
## Scalar predicates
Scalar predicates used in filter arguments of the [`CALCULATE`](https://dax.guide/calculate) or [`CALCULATETABLE`](https://dax.guide/calculatetable) functions are handled in a special way, in the **Locals** view.
diff --git a/content/features/dax-editor.md b/content/features/dax-editor.md
index a4b5cdd6e..b078c22f7 100644
--- a/content/features/dax-editor.md
+++ b/content/features/dax-editor.md
@@ -28,7 +28,6 @@ It comes in three different *flavours*:
All three flavours support the same operations in terms of [keyboard shortcuts](xref:shortcuts3#dax-code), syntax highlighting, code assist, etc.
-
## Code Assist features
The main enabler of productivity in Tabular Editor 3's DAX Editor, is its **Parameter Info** and **Auto-Complete** features. Collectively, these are known as **Code Assist** features (other vendors use the term "IntelliSense").
diff --git a/content/features/deployment.md b/content/features/deployment.md
index ff5654f12..ba61ddad6 100644
--- a/content/features/deployment.md
+++ b/content/features/deployment.md
@@ -15,7 +15,7 @@ applies_to:
full: true
---
-## Model deployment
+# Model deployment
Tabular Editor 3 (Business and Enterprise Edition) can take a copy of the currently loaded semantic model metadata, and deploy it to an Analysis Services instance, or the Power BI / Fabric XMLA endpoint.
diff --git a/content/features/hierarchical-display.md b/content/features/hierarchical-display.md
index 49198341b..4b952dcd5 100644
--- a/content/features/hierarchical-display.md
+++ b/content/features/hierarchical-display.md
@@ -14,7 +14,7 @@ applies_to:
- edition: Enterprise
full: true
---
-## Hierarchical display
+# Hierarchical display
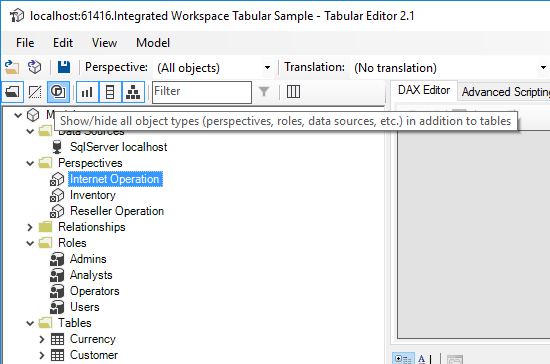
Objects of the loaded model are shown in the TOM Explorer Tree. By default, all object types (visible tables, roles, relationships, etc.) are shown. If you only want to see tables, measures, columns and hierarchies, go to the "View" menu and toggle off "Show all object types".
diff --git a/content/features/import-tables.partial.md b/content/features/import-tables.partial.md
index 21d0193a1..046331c7b 100644
--- a/content/features/import-tables.partial.md
+++ b/content/features/import-tables.partial.md
@@ -29,7 +29,6 @@ Depending on your version of Analysis Services, there are different ways of defi
> [!NOTE]
> The Table Import Wizard and Update Table Schema feature of Tabular Editor 2.x only supports Legacy data sources with SQL partitions. In other words, there is no support for Power Query partitions. For this reason, Legacy data sources are usually recommended, as they provide the highest level of interoperability between the developer tools.
-
## Importing new tables
When importing tables (Model menu > Import tables...), Tabular Editor presents you with the options mentioned above (for creating a new data source), as well as a list of data sources already present in the model. Avoid creating new data sources if the tables you want to import are available in one of the data sources already specified in the model.
@@ -105,7 +104,6 @@ At this point, you should see your tables imported with all columns, data types,

-
# Updating table schema
If columns are added/changed in the source, or if you recently modified a partition expression or query, you can use Tabular Editor's **Update table schema** feature to update the column metadata in your model.
@@ -131,7 +129,6 @@ If you do not want the name change to be propagated to the imported column (but

-
## Updating table schema through Analysis Services
By default, Tabular Editor 3 attempts to connect directly to the data source for the purposes of updating the imported table schema. Naturally, this only works when the data source is supported by Tabular Editor 3. If you need to update the schema of a table imported from a data source that is not supported by Tabular Editor 3, you can enable the **Use Analysis Services for change detection** option under **Tools > Preferences > Schema Compare**. This also applies when the M expression of a partition or shared expression is too complex for Tabular Editor 3's built-in schema detection feature. For example, the built-in schema detection does not support certain M functions.
diff --git a/content/features/semantic-bridge-metric-view-object-model.md b/content/features/semantic-bridge-metric-view-object-model.md
index b1b5ce1be..62ec8efc7 100644
--- a/content/features/semantic-bridge-metric-view-object-model.md
+++ b/content/features/semantic-bridge-metric-view-object-model.md
@@ -35,7 +35,6 @@ This allows you to work with Metric Views programmatically through C# scripts, s
Other than the [import GUI](xref:semantic-bridge#interface), all access to and interaction with a Metric View is through C# scripts.
All content in this document is referring to C# code that you will use in a [C# script](xref:csharp-scripts).
-
## Loading and accessing the Metric View
You can load a Metric view with [`SemanticBridge.MetricView.Load`](xref:TabularEditor.SemanticBridge.Platforms.Databricks.DatabricksMetricViewService#TabularEditor_SemanticBridge_Platforms_Databricks_DatabricksMetricViewService_Load_System_String_) or [`SemanticBridge.MetricView.Deserialize`](xref:TabularEditor.SemanticBridge.Platforms.Databricks.DatabricksMetricViewService#TabularEditor_SemanticBridge_Platforms_Databricks_DatabricksMetricViewService_Deserialize_System_String_).
diff --git a/content/features/semantic-bridge.md b/content/features/semantic-bridge.md
index 77a4df52c..01cc47c1b 100644
--- a/content/features/semantic-bridge.md
+++ b/content/features/semantic-bridge.md
@@ -30,7 +30,6 @@ The Semantic Bridge is a semantic model compiler, with the capability to transla
This allows you to reuse business logic on multiple data platforms, supporting end users and meeting them where they consume the data.
It also allows for migrations from one platform to another.
-
## Interface
### Import Metric View YAML
@@ -119,7 +118,6 @@ Specifically, you can
- import a Metric View to Tabular with [`SemanticBridge.MetricView.ImportToTabularFromFile`](/api/TabularEditor.SemanticBridge.Platforms.Databricks.DatabricksMetricViewService.html#TabularEditor_SemanticBridge_Platforms_Databricks_DatabricksMetricViewService_ImportToTabularFromFile_System_String_TabularEditor_TOMWrapper_Model_System_String_System_String_System_Collections_Generic_List_TabularEditor_SemanticBridge_Orchestration_DiagnosticMessage___System_Boolean_), which does the exact same as the GUI shown above, or [`SemanticBridge.MetricView.ImportToTabular`](/api/TabularEditor.SemanticBridge.Platforms.Databricks.DatabricksMetricViewService.html#TabularEditor_SemanticBridge_Platforms_Databricks_DatabricksMetricViewService_ImportToTabular_TabularEditor_TOMWrapper_Model_System_String_System_String_System_Collections_Generic_List_TabularEditor_SemanticBridge_Orchestration_DiagnosticMessage___System_Boolean_), which is similar, but operates on the currently loaded Metric View, rather than reading one from disk.
-
## Public Preview Limitations
### Supported platforms
diff --git a/content/features/te-cli/te-cli-auth.md b/content/features/te-cli/te-cli-auth.md
index 472afcb45..864496074 100644
--- a/content/features/te-cli/te-cli-auth.md
+++ b/content/features/te-cli/te-cli-auth.md
@@ -130,7 +130,7 @@ te connect Finance "Revenue Model" -w ./revenue-model
te connect ./revenue-model -w Finance "Revenue Model"
```
-Save order is always **local first, then remote**, so the on-disk copy reflects the latest user change even if the server push fails. See @te-cli-commands#workspace-mode--w----workspace for `--workspace-format`, overwrite semantics, and clearing the mirror.
+Save order is always **local first, then remote**, so the on-disk copy reflects the latest user change even if the server push fails. See [Workspace mode](xref:te-cli-commands#workspace-mode--w----workspace) for `--workspace-format`, overwrite semantics, and clearing the mirror.
## Connecting to different clouds
diff --git a/content/features/views/find-replace.md b/content/features/views/find-replace.md
index c5f328b42..e8ea54689 100644
--- a/content/features/views/find-replace.md
+++ b/content/features/views/find-replace.md
@@ -17,7 +17,6 @@ applies_to:
- edition: Enterprise
full: true
---
-
# Find
In Tabular Editor, you can use the advanced Find functionality to search for specific expressions throughout your open documents and dataset. The Find dialog box is accessible through the keyboard shortcut Ctrl+F.
@@ -47,7 +46,6 @@ Additionally, you can specify where to Look in, different areas of your Tabular
> [!TIP]
> You can also use the search field in the TOM Explorer to search your dataset instead of the Find dialog
-
## Replace
The Replace dialog allows you in the same way as Find to search for an expression and then replace it with a different expression.
diff --git a/content/features/views/user-interface.md b/content/features/views/user-interface.md
index 61ed317ce..9554d323f 100644
--- a/content/features/views/user-interface.md
+++ b/content/features/views/user-interface.md
@@ -41,7 +41,6 @@ There are a number of additional views available, serving various purposes. More
All UI elements may be resized and/or rearranged to fit your needs. You can even drag individual views out of the main view, thus splitting up an instance of Tabular Editor 3 across multiple monitors. Tabular Editor 3 will save the customization when the application is closed, and reload it automatically upon next launch.
-
### Choosing a different layout
To reset the application to the default layout, choose the **Window > Default layout** option. Users of Tabular Editor 2.x may prefer the **Window > Classic layout** option which places the TOM Explorer on the left side of the screen, and the Properties view below the Expression Editor.
@@ -50,7 +49,6 @@ Use the **Window > Capture current layout..." option to save a customized layout

-
### Window docking options
When rearranging views and documents in Tabular Editor 3, you can choose to dock windows in different areas of the interface. When dragging a window to a new position, docking indicators will appear showing you the available docking locations.
@@ -84,7 +82,6 @@ For the vector based themes (Basic and Bezier), use the **Window > Palette** men

-
# Menus
The following section describes the menus in Tabular Editor 3 in more details.
@@ -159,7 +156,6 @@ The **Edit** menu contains standard Windows application menu items for editing a
- **Select all**: Selects all text in the currently active document, or all objects belonging to the same parent within the TOM Explorer.
- **Code assist**: This option is available when editing DAX code. It provides a shortcut to various code assist features relevant for editing DAX code. See [DAX editor](xref:dax-editor#code-assist-features) for more information.
-
## View
The **View** menu lets you navigate between the different views of the Tabular Editor 3 UI. If a view has been hidden, click on the view title in this menu will unhide the view and bring it into focus. Note that documents are not shown in the View menu. To navigate between documents, use the [Window menu](#window).
@@ -186,7 +182,7 @@ The **Model** menu displays actions that can be performed at the level of the Mo
> The **Deploy** option is not available in Tabular Editor 3 Desktop Edition. For more information see @editions.
- **Import tables...** Launches the Tabular Editor 3 Import Table Wizard. For more information, see @importing-tables.
-- **Update table schema...** Detects schema changes in the data source(s) for the currently selected table(s) or partition(s) compared to the currently imported columns. See @importing-tables#updating-table-schema for more information.
+- **Update table schema...** Detects schema changes in the data source(s) for the currently selected table(s) or partition(s) compared to the currently imported columns. See [Updating table schema](xref:importing-tables#updating-table-schema) for more information.
- **Script DAX**: Generates a DAX script for the currently selected object(s) (or all DAX objects in the model, if nothing is selected). See @dax-scripts for more information.
- **Refresh model**: When Tabular Editor is connected to an instance of Analysis Services, this submenu contains options for starting a background refresh operation at the model level. The submenu has the options below. For more information, see [Refresh command (TMSL)](https://docs.microsoft.com/en-us/analysis-services/tmsl/refresh-command-tmsl?view=asallproducts-allversions#request).
- **Automatic (model)**: Analysis Services determines which objects to refresh (only objects that are not in the "Ready" state).
@@ -203,7 +199,6 @@ The **Tools** menu contains options for controlling Tabular Editor 3 preferences
- **Customize...** Launches the Tabular Editor 3 User Interface Layout customization dialog, which lets you create new toolbars, rearrange and edit menus and toolbar buttons, etc.
- **Preferences...** Launches the Tabular Editor 3 Preferences dialog, which is a central hub for managing all other aspects of Tabular Editor and its features, such as update checks, proxy settings, query row limits, request timeouts, etc. See @preferences for more information.
-
## Window
The **Window** menu provides shortcuts for managing and navigating between the various views and documents (collectively known as *windows*) of the application. It also has menu items for controlling the theming and color palettes as described [above](#changing-themes-and-palettes).
diff --git a/content/getting-started/desktop-limitations.md b/content/getting-started/desktop-limitations.md
index 1c0866e45..1b9504d5a 100644
--- a/content/getting-started/desktop-limitations.md
+++ b/content/getting-started/desktop-limitations.md
@@ -29,7 +29,6 @@ As of the June 2025 Power BI Desktop update, there are no longer any unsupported
More information in [the official blog post](https://powerbi.microsoft.com/en-us/blog/open-and-edit-any-semantic-model-with-power-bi-tools/).
-
## Power BI file types
When using Power BI, you will encounter three different file types commonly used:
@@ -61,7 +60,6 @@ External tools may connect to the instance of Analysis Services managed by Power
Once connected to the instance of Analysis Services, an external tool can obtain information about the model metadata, execute DAX or MDX queries against the data model, an even apply changes to the model metadata through [Microsoft-provided client libraries](https://docs.microsoft.com/en-us/analysis-services/client-libraries?view=asallproducts-allversions). In this regard, the Analysis Services instance managed by Power BI Desktop is no different from any other type of Analysis Services instance.
-
## Data modeling operations
However, due to the way Power BI Desktop interoperates with Analysis Services, there are a few important limitations to the type of changes external tools may apply to the model metadata. These are listed [in the official documentation for External Tools](https://docs.microsoft.com/en-us/power-bi/transform-model/desktop-external-tools#data-modeling-operations) and repeated here for convenience:
diff --git a/content/getting-started/importing-tables-data-modeling.md b/content/getting-started/importing-tables-data-modeling.md
index a711004ff..372d6d5f7 100644
--- a/content/getting-started/importing-tables-data-modeling.md
+++ b/content/getting-started/importing-tables-data-modeling.md
@@ -20,12 +20,10 @@ applies_to:
This article describes how to use the [Table Import Wizard](#table-import-wizard) of Tabular Editor 3, to add new tables to the model. There is also a section on how to [update the table schema](#updating-table-schema) of an existing table. Lastly, we cover how to use the [diagram tool](#working-with-diagrams) to define and edit relationships between tables.
-
## Table Import Wizard
[!include[importing-tables1](../features/import-tables.partial.md)]
-
# Working with diagrams
In Tabular Editor 3, **diagrams** are documents that can be used to visualize and edit the relationships between tables in the model. You can create as many diagrams as you want to visualize certain areas of your model. A diagram can be saved as a standalone file. See for more information.
@@ -51,7 +49,6 @@ To add additional tables to the diagram, use the technique above again, or right
Before proceeding, rearrange and resize the tables in the diagram to suit your preferences, or use the **Diagram > Auto-arrange** feature to have Tabular Editor 3 lay out the tables automatically.
-
## Modifying relationships using the diagram
To add a new relationship between two tables, locate the column on the fact table (many-side) of the relationship, and drag that column over to the corresponding column on the dimension table (one-side). Confirm the settings for the relationship and hit **OK**.
diff --git a/content/getting-started/installation.md b/content/getting-started/installation.md
index 7b21a078e..3d521ea92 100644
--- a/content/getting-started/installation.md
+++ b/content/getting-started/installation.md
@@ -17,13 +17,14 @@ applies_to:
full: true
---
+# Advanced installation and activation
+
## Overview
This page covers advanced installation and activation scenarios for Tabular Editor 3: manual (offline) activation, registry-based license management, silent deployment, and Enterprise seat administration.
For the standard activation flow, see @getting-started.
-
## Manual activation (no internet)
If you do not have access to the internet, for example due to a proxy, Tabular Editor prompts you to do a manual activation.
@@ -49,7 +50,6 @@ To change an Enterprise seat, deregister the existing user from the seat through
> [!NOTE]
> Changing a user is only possible on the Enterprise Edition.
-
## Registry details
Tabular Editor 3 uses the Windows Registry to store activation details.
diff --git a/content/getting-started/migrate-from-te2.md b/content/getting-started/migrate-from-te2.md
index 5733b4f56..487a4e16f 100644
--- a/content/getting-started/migrate-from-te2.md
+++ b/content/getting-started/migrate-from-te2.md
@@ -67,7 +67,6 @@ The schema compare dialog itself also has a number of improvements, for example
To learn more, see .
-
### Workspace mode
Tabular Editor 3 introduces the concept of **workspace mode**, in which model metadata is loaded from disk (Model.bim or Database.json), and then immediately deployed to an Analysis Services instance of your choice. Whenever you hit Save (CTRL+S), the workspace database is synchronized and updated model metadata is saved back to the disk. The advantage of this approach, is that Tabular Editor is connected to Analysis Services, thus enabling the [connected features](#connected-features) listed below, while also making it easy to update the source files on disk. With Tabular Editor 2.x, you had to open a model from a database, and then remember to manually save to disk once in a while.
@@ -76,7 +75,6 @@ This approach is ideal to enable [parallel development](xref:parallel-developmen
For more information, see .
-
### Connected features
Tabular Editor 3 includes a number of new connected features, allowing you to use it as a client tool for Analysis Services. These features are enabled whenever Tabular Editor 3 is connected to Analysis Services, either directly or when using the [workspace mode](#workspace-mode) feature.
diff --git a/content/getting-started/parallel-development.md b/content/getting-started/parallel-development.md
index aee3700e4..452cc79df 100644
--- a/content/getting-started/parallel-development.md
+++ b/content/getting-started/parallel-development.md
@@ -47,7 +47,6 @@ Power BI dataset developers have it much worse, since they do not even have acce
Tabular Editor aims to simplify this process by providing an easy way to extract only the semantically meaningful metadata from the Tabular Object Model, regardless of whether that model is an Analysis Services tabular model or a Power BI dataset. Moreover, Tabular Editor can split up this metadata into several smaller files using its Save to Folder feature.
-
## What is Save to Folder?
As mentioned above, the model metadata for a tabular model is traditionally stored in a single, monolithic JSON file, typically named **Model.bim**, which is not well suited for version control integration. Since the JSON in this file represents the [Tabular Object Model (TOM)](https://docs.microsoft.com/en-us/analysis-services/tom/introduction-to-the-tabular-object-model-tom-in-analysis-services-amo?view=asallproducts-allversions), it turns out that there is a straightforward way to break the file down into smaller pieces: The TOM contains arrays of objects at almost all levels, such as the list of tables within a model, the list of measures within a table, the list of annotations within a measure, etc. When using Tabular Editor's **Save to Folder** feature, these arrays are simply removed from the JSON, and instead, a subfolder is generated containing one file for each object in the original array. This process can be nested. The result is a folder structure, where each folder contains a set of smaller JSON files and subfolders, which semantically contains exactly the same information as the original Model.bim file:
diff --git a/content/getting-started/personalizing-te3.md b/content/getting-started/personalizing-te3.md
index 5bddaf7a2..2c6c30480 100644
--- a/content/getting-started/personalizing-te3.md
+++ b/content/getting-started/personalizing-te3.md
@@ -110,7 +110,6 @@ When this is checked, a tab character (`\t`) is inserted whenever the TAB button
DAX supports line comments that use slashes (`//`) or hyphens (`--`). This setting determines which style of comment is used when Tabular Editor 3 generates DAX code, such as when using the DAX script feature.
-
## DAX Settings
These settings determine certain behavior of the DAX code analyzer. The *Locale* setting is simply a matter of preference. All other settings are relevant only when Tabular Editor 3 cannot determine the version of Analysis Services used, as is the case for example when a Model.bim file is loaded directly. In this case, Tabular Editor tries to guess which version the model will be deployed to, based on the compatibility level specified in the model, but depending on the actual version of the deployment target, there may be various DAX language differences, which Tabular Editor cannot determine. If Tabular Editor reports incorrect semantic/syntax errors, you may need to tweak these settings.
diff --git a/content/getting-started/refresh-preview-query.md b/content/getting-started/refresh-preview-query.md
index 219b9c2b7..e3d809908 100644
--- a/content/getting-started/refresh-preview-query.md
+++ b/content/getting-started/refresh-preview-query.md
@@ -35,7 +35,6 @@ In summary, these connected features are:
- DAX Querying
- VertiPaq Analyzer
-
# Refreshing data
Tabular Editor does not automatically trigger refresh operations in Analysis Services when changes are made to the data model. This is by design, to ensure that saving metadata changes to Analysis Services does not take too long. Potentially, a refresh operation can take a long time to complete, during which no additional metadata may be updated on the server. Of course, the drawback of this, is that you can make changes using Tabular Editor, which causes the model to enter a state where it is only partly queryable or not queryable at all. Depending on what type of data model change was made, different levels of refresh may be needed.
@@ -79,7 +78,6 @@ Tabular Editor 3 supports refresh operations on different object types. The supp
See [Refresh Types](https://docs.microsoft.com/en-us/analysis-services/tmsl/refresh-command-tmsl?view=asallproducts-allversions#request) for more information about the types of refresh operations supported by Analysis Services / Power BI.
-
# Previewing table data
At certain points during DAX authoring and data model development, you may need to inspect the contents of your tables on a row-by-row basis. Of course, you could write a DAX query to achieve this, but Tabular Editor 3 makes that even easier by allowing you to preview table data directly. To do this, right-click on a table and choose the **Preview data** option.
@@ -92,7 +90,6 @@ If one or more calculated columns are in an invalid state, those columns contain

-
# Pivot Grids
After adding or editing DAX measures in a model, it is common for model developers to test these measures. Traditionally, this was typically done using client tools such as Excel or Power BI. With Tabular Editor 3, you can now use **Pivot Grids** which behave much like the famous PivotTables of Excel. The Pivot Grid lets you quickly create summarized views of the data in your model, allowing you test the behavior of your DAX measures when filtering and slicing by various columns and hierarchies.
@@ -107,7 +104,6 @@ As fields are dragged into the Pivot Grid, Tabular Editor generates MDX queries
The Pivot Grid is automatically refreshed when a change is made to the model or a refresh operation finishes. You can toggle this auto-refresh capability within the **Pivot Grid** menu.
-
# DAX Queries
A more direct way to query the data in your model, is to write a DAX query. Use the **File > New > DAX Query** menu option to create a new DAX query document. You can have multiple DAX query documents open at the same time.
diff --git a/content/how-tos/Advanced-Scripting.md b/content/how-tos/Advanced-Scripting.md
index bd756bcb2..30c30f39e 100644
--- a/content/how-tos/Advanced-Scripting.md
+++ b/content/how-tos/Advanced-Scripting.md
@@ -122,7 +122,6 @@ Selected.Measures
.ForEach(m => m.Name += " DEPRECATED");
```
-
## Helper methods
To make debugging scripts easier, Tabular Editor provides a set of special helper methods. Internally, these are static methods decorated with the `[ScriptMethod]`-attribute. This attribute allows scripts to call the methods directly, without the need to specify a namespace or class name. Plugins may also use the `[ScriptMethod]` attribute to expose public static methods for scripting in a similar way.
diff --git a/content/how-tos/Importing-Tables.md b/content/how-tos/Importing-Tables.md
index 0b11221d2..48f98e1f5 100644
--- a/content/how-tos/Importing-Tables.md
+++ b/content/how-tos/Importing-Tables.md
@@ -65,7 +65,6 @@ The "Identifier quotes"-dropdown lets you specify how object names (column, tabl
Another way to bring up the import page, is to right-click on an existing table (that uses a Legacy Data Source), and choose "Select Columns...". If that table was previously imported using the UI, the import page should show up with the source table/view and imported columns pre-selected. You may add/remove columns or even choose an entirely different table to be imported in place of the table you selected in your model. Keep in mind that any columns in your table, that were deselected or no longer exists in your source table/view will be removed from your model. You can always undo operations such as this using CTRL+Z.
-
## Refreshing Table Metadata
As of version 2.8, Tabular Editor has a new UI feature that lets you easily check for schema drift. That is, detecting columns that had their data type changed, or were added or removed to source tables and views. This check may be invoked at the Model level (again, this only applies to Legacy Data Sources), at the Data Source level, at the Table level or at the Partition level. This is done by right-clicking the object and choosing "Refresh Table Metadata..."
@@ -80,7 +79,6 @@ This mechanism (as well as the Import Table UI) uses the FormatOnly-flag, when q
You can perform a schema check at the model level from the command line by using the `-SC` flag. Note that the schema check, when executed through the CLI, will only report mapping issues. It will not make any changes to your model. This is useful if you're using Tabular Editor within CI/CD pipelines, as mapping issues could potentially cause problems after deploying your model to a test/production environment.
-
### Ignoring objects
As of Tabular Editor 2.9.8, you can exclude objects from schema checks / metadata refresh. This is controlled by setting an annotation on the objects that you wish to leave out. As the annotation name, use the codes listed below. You can leave the annotation value blank or set it to "1", "true" or "yes". Setting the annotation value to "0", "false" or "no" will effectively disable the annotation, as if it didn't exist:
diff --git a/content/how-tos/connect-ssas.md b/content/how-tos/connect-ssas.md
index 83f3c6b1d..9b52ac530 100644
--- a/content/how-tos/connect-ssas.md
+++ b/content/how-tos/connect-ssas.md
@@ -9,7 +9,7 @@ applies_to:
full: true
---
-## Connect/deploy to SSAS Tabular Databases
+# Connect/deploy to SSAS Tabular Databases
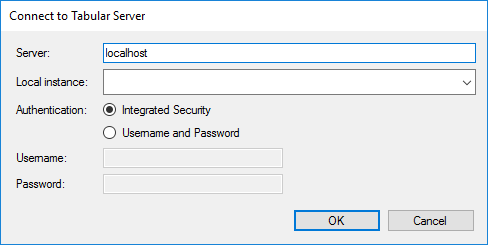
Hitting CTRL+SHIFT+O lets you open a Tabular Model directly from a Tabular Database that has already been deployed. Enter the server address and (optionally) provide a username and password. After hitting "OK", you will be prompted with a list of databases and the server. Select the one you want to load, and click "OK" again.
diff --git a/content/how-tos/deploy-current-model.md b/content/how-tos/deploy-current-model.md
index 1b9e5a888..08d126723 100644
--- a/content/how-tos/deploy-current-model.md
+++ b/content/how-tos/deploy-current-model.md
@@ -8,6 +8,8 @@ applies_to:
- product: Tabular Editor 3
full: true
---
+# Deploy Current Loaded Model
+
## Deployment
If you want to deploy the currently loaded model to a new database, or overwrite an existing database with the model changes (for example when loading from a Model.bim file), use the Deployment Wizard under "Model" > "Deploy...".
diff --git a/content/how-tos/drag-drop.md b/content/how-tos/drag-drop.md
index d1c60855c..3efdbd9df 100644
--- a/content/how-tos/drag-drop.md
+++ b/content/how-tos/drag-drop.md
@@ -9,7 +9,7 @@ applies_to:
full: true
---
-## Drag and drop objects
+# Drag and drop objects
By far the most useful feature of Tabular Editor, when working on models with many measures/columns organised in display folders. Check out the animation below:

diff --git a/content/how-tos/duplicate-batchrename.md b/content/how-tos/duplicate-batchrename.md
index 05e68e99b..abf6295ec 100644
--- a/content/how-tos/duplicate-batchrename.md
+++ b/content/how-tos/duplicate-batchrename.md
@@ -9,7 +9,7 @@ applies_to:
full: true
---
-## Duplicate objects and batch renamings
+# Duplicate objects and batch renamings
The right-click context menu in the Explorer Tree lets you duplicate measures and columns. The duplicated objects will have their names suffixed by "copy". Furthermore, you can perform batch renames by selecting multiple objects and right-clicking in the Explorer Tree.

diff --git a/content/how-tos/edit-properties.md b/content/how-tos/edit-properties.md
index 0293b29d8..84734a92e 100644
--- a/content/how-tos/edit-properties.md
+++ b/content/how-tos/edit-properties.md
@@ -9,7 +9,7 @@ applies_to:
full: true
---
-## Editing properties
+# Editing properties
The Property Grid on the lower right side of the screen, shows most of the properties for the object(s) selected in the Explorer Tree. If you select multiple objects at once, the Property Grid lets you simultaneously edit properties for the selected objects. This is useful for example when setting the Format String property. Examples of properties you can set through the Property Grid:
* Name (you can rename objects directly in the Explorer Tree by hitting F2)
diff --git a/content/how-tos/folder-serialization.md b/content/how-tos/folder-serialization.md
index abfc3c4a8..7dba95884 100644
--- a/content/how-tos/folder-serialization.md
+++ b/content/how-tos/folder-serialization.md
@@ -8,7 +8,7 @@ applies_to:
- product: Tabular Editor 3
full: true
---
-## Folder Serialization
+# Folder Serialization
This feature allows you to more easily integrate your SSAS Tabular Models in a file-based source control environment such as TFS, SubVersion or Git. By choosing "File" > "Save to Folder...", Tabular Editor will deconstruct the Model.bim file and save its content as separate files in a folder structure similar to the structure of the JSON within the Model.bim. When subsequently saving the model, only files with changed metadata will be touched, meaning most version control systems can easily detect which changes have been done to the model, making source merging and conflict handling a lot easier, than when working with a single Model.bim file.

diff --git a/content/how-tos/formula-fixup-dependencies.md b/content/how-tos/formula-fixup-dependencies.md
index 84a2aaa65..71afbd20d 100644
--- a/content/how-tos/formula-fixup-dependencies.md
+++ b/content/how-tos/formula-fixup-dependencies.md
@@ -9,7 +9,7 @@ applies_to:
full: true
---
-## Formula Fix-up and Formula Dependencies
+# Formula Fix-up and Formula Dependencies
Tabular Editor continuously parses the DAX expressions of all measures, calculated columns and calculated tables in your model, to construct a dependency tree of these objects. This dependency tree is used for the Formula Fix-up functionality, which may be enabled under "File" > "Preferences". Formula Fix-up automatically updates the DAX expression of any measure, calculated column or calculated table, whenever an object that was referenced in the expression is renamed.
To visualize the dependency tree, right-click the object in the explorer tree and choose "Show dependencies..."
diff --git a/content/how-tos/import-export-translations.md b/content/how-tos/import-export-translations.md
index d4847c3cd..cf804376d 100644
--- a/content/how-tos/import-export-translations.md
+++ b/content/how-tos/import-export-translations.md
@@ -9,5 +9,5 @@ applies_to:
full: true
---
-## Import/Export Translations
+# Import/Export Translations
Select one or more cultures in the Explorer Tree, right-click and choose "Export Translations..." to generate a .json file that can be imported later in either Tabular Editor or Visual Studio. Choose "Import Translations..." to import a corresponding .json file. You can choose whether to overwrite existing translations. If you don't, translations defined in the .json file will only be applied to objects that do not already have a translation for the given culture.
\ No newline at end of file
diff --git a/content/how-tos/load-save.md b/content/how-tos/load-save.md
index 83cb647d2..dffd3f1f3 100644
--- a/content/how-tos/load-save.md
+++ b/content/how-tos/load-save.md
@@ -9,5 +9,5 @@ applies_to:
full: true
---
-## Load/save Model.bim files
+# Load/save Model.bim files
Hitting CTRL+O shows an Open File dialog, which lets you select a Model.bim file to load in Tabular Editor. The file must be of Compatibility Level 1200 or newer (JSON format). CTRL+S saves any changes you make in Tabular Editor back to the file (we recommend backing up your Model.bim files before using Tabular Editor). If you want to deploy the loaded model to an Analysis Services server instance, see [Deployment](../features/deployment.md).
\ No newline at end of file
diff --git a/content/how-tos/metadata-backup.md b/content/how-tos/metadata-backup.md
index 2eeeccff8..de410d29f 100644
--- a/content/how-tos/metadata-backup.md
+++ b/content/how-tos/metadata-backup.md
@@ -8,7 +8,7 @@ applies_to:
- product: Tabular Editor 3
full: true
---
-## Metadata Backup
+# Metadata Backup
If you wish, Tabular Editor can automatically save a backup copy of the existing model metadata, prior to each save (when connected to an existing database) or deployment. This is useful if you're not using a version control system, but still need to rollback to a previous version of your model.
To enable this setting, go to "File" > "Preferences", enable the checkbox and choose a folder to place the metadata backups:
diff --git a/content/how-tos/perspectives-translations.md b/content/how-tos/perspectives-translations.md
index de735fdc1..615b16d46 100644
--- a/content/how-tos/perspectives-translations.md
+++ b/content/how-tos/perspectives-translations.md
@@ -10,7 +10,7 @@ applies_to:
note: Includes dedicated Perspective and Translation Editors
---
-## Working with Perspectives and Translations
+# Working with Perspectives and Translations
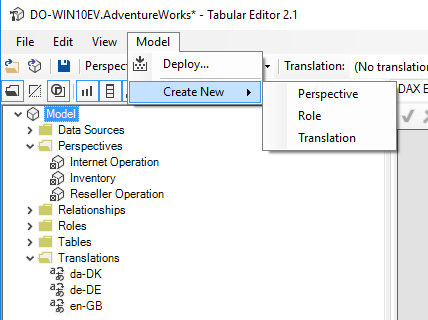
You can add/edit existing perspectives and translations (cultures), by clicking the Model node in the Explorer Tree, and locating the relevant properties at the bottom of the property grid. Alternatively, when your Explorer Tree is [showing all object types](../features/hierarchical-display.md), you can view and edit perspectives, cultures and roles directly in the tree.
diff --git a/content/how-tos/replace-tables.md b/content/how-tos/replace-tables.md
index 3516522a1..0bdf9fc7e 100644
--- a/content/how-tos/replace-tables.md
+++ b/content/how-tos/replace-tables.md
@@ -8,7 +8,7 @@ applies_to:
- product: Tabular Editor 3
full: true
---
-## Replace tables
+# Replace tables
You can replace a table simply by copying (CTRL+C) one table - even from another instance of Tabular Editor - and then selecting the table you want to replace, before hitting paste (CTRL+V). A prompt will ask you to confirm whether you really want to replace the table ("Yes"), insert as a new table ("No") or cancel the operation entirely:

diff --git a/content/how-tos/roles-rls.md b/content/how-tos/roles-rls.md
index 19b8912e6..9b1df4d88 100644
--- a/content/how-tos/roles-rls.md
+++ b/content/how-tos/roles-rls.md
@@ -8,7 +8,7 @@ applies_to:
- product: Tabular Editor 3
full: true
---
-## Roles and Row-Level Security
+# Roles and Row-Level Security
Roles are visible in the Explorer Tree. You can right-click the tree to create new roles, delete or duplicate existing roles. You can view and edit the members of each role, by locating the role in the Explorer Tree, and navigating to the "Role Members" property in the Property Grid. Note that when deploying, the [Deployment Wizard](../features/deployment.md) does not deploy role members by default.
diff --git a/content/how-tos/script-reference-objects.md b/content/how-tos/script-reference-objects.md
index 64362b6ca..433ae78ee 100644
--- a/content/how-tos/script-reference-objects.md
+++ b/content/how-tos/script-reference-objects.md
@@ -9,7 +9,7 @@ applies_to:
full: true
---
-## Scripting/referencing objects
+# Scripting/referencing objects
You can use drag-and-drop functionality, to script out objects in the following ways:
* Drag one or more objects to another Windows application (text editor or SSMS)
diff --git a/content/how-tos/undo-redo.md b/content/how-tos/undo-redo.md
index 016f02011..019a8bdc9 100644
--- a/content/how-tos/undo-redo.md
+++ b/content/how-tos/undo-redo.md
@@ -8,7 +8,7 @@ applies_to:
- product: Tabular Editor 3
full: true
---
-## Undo/Redo support
+# Undo/Redo support
Any change you make in Tabular Editor can be undone using CTRL+Z and subsequently redone using CTRL+Y. There is no limit to the number of operations that can be undone, but the stack is reset when you open a Model.bim file or load a model from a database.
When deleting objects from the model, all translations, perspectives and relationships that reference the deleted objects are also automatically deleted (whereas Visual Studio normally shows an error message that the object cannot be deleted). If you make a mistake, you can use the Undo functionality to restore the deleted object, which will also restore any translations, perspectives or relationships that were deleted. Note that even though Tabular Editor can detect [DAX formula dependencies](xref:formula-fix-up-dependencies), Tabular Editor will not warn you in case you delete a measure or column which is used in the DAX expression of another measure or calculated column.
\ No newline at end of file
diff --git a/content/how-tos/xmla-as-connectivity.md b/content/how-tos/xmla-as-connectivity.md
index 087b11cba..7050c8370 100644
--- a/content/how-tos/xmla-as-connectivity.md
+++ b/content/how-tos/xmla-as-connectivity.md
@@ -136,7 +136,6 @@ In Fabric, the default semantic model of a lakehouse or warehouse can be opened/
## Troubleshooting XMLA connections
-
### Testing a simple connection
These steps show how to most reliably connect to a Fabric/Power BI semantic model from Tabular Editor.
diff --git a/content/references/preferences.md b/content/references/preferences.md
index ad1d36755..fef7dda3f 100644
--- a/content/references/preferences.md
+++ b/content/references/preferences.md
@@ -213,7 +213,6 @@ When saving a model loaded from a PBIX file, use the PBIX filename as the defaul
Automatically create .tmuo (Tabular Model User Options) files for new models. These files store user-specific settings like diagram layouts and window positions.
-
## Tabular Editor > Keyboard

@@ -537,7 +536,6 @@ Specify the locale for DAX functions and formatting.
These settings are relevant only when Tabular Editor 3 cannot determine the version of Analysis Services used, as is the case when a Model.bim file is loaded directly. In this case, Tabular Editor tries to guess which version the model will be deployed to, based on the compatibility level. If Tabular Editor reports incorrect semantic/syntax errors, you may need to tweak these settings.
-
## DAX Editor > Auto Formatting

@@ -663,7 +661,6 @@ Referencing certain table names do not require surrounding single quotes in DAX.
Extension columns can be defined without a table name. When checked, the DAX editor will always add the table prefix to an extension column.
-
## DAX Editor > Code Assist
![Placeholder: Screenshot of DAX Editor Code Assist preferences page]
diff --git a/content/references/supported-files.md b/content/references/supported-files.md
index 1c140bb82..2e08bcd10 100644
--- a/content/references/supported-files.md
+++ b/content/references/supported-files.md
@@ -17,7 +17,6 @@ applies_to:
- edition: Enterprise
full: true
---
-
# Supported file types
Tabular Editor 3 uses a number of different file formats and document types, some of which are not used by Analysis Services or Power BI. This article provides an overview and a description of each of these file types.
@@ -186,7 +185,6 @@ Supporting files are files which are not used by Analysis Services or Power BI.
All supporting files can be saved individually using either Ctrl+S or 'File > Save' while having the corresponding document or window open and focused.
-
### Diagram file (.te3diag)
A .te3diag file is a file format that stores the diagram of a model created with TE3.
diff --git a/content/references/user-settings-files-te2.md b/content/references/user-settings-files-te2.md
index 6dac5434b..74cf282fb 100644
--- a/content/references/user-settings-files-te2.md
+++ b/content/references/user-settings-files-te2.md
@@ -9,7 +9,7 @@ applies_to:
none: true
---
-## User Settings Files Tabular Editor 2
+# User Settings Files Tabular Editor 2
When Tabular Editor 2 is started, it writes some additional files to the disk at various locations. What follows is a description of these files and their content:
diff --git a/content/troubleshooting/licensing-activation.md b/content/troubleshooting/licensing-activation.md
index 6925c48b6..180332656 100644
--- a/content/troubleshooting/licensing-activation.md
+++ b/content/troubleshooting/licensing-activation.md
@@ -30,7 +30,6 @@ Confirm the machine meets the requirements before further troubleshooting:
Use the matching MSI for your architecture from the [downloads page](xref:downloads). An installer or architecture mismatch is a frequent cause of failed installs and missing-dependency errors at first launch.
-
## Inspect the activated license
Tabular Editor 3 stores activation details in the Windows Registry under `HKEY_CURRENT_USER\SOFTWARE\Kapacity\Tabular Editor 3`.
@@ -55,7 +54,6 @@ If activation prompts persist:
2. Configure proxy settings under **Tools > Preferences > Proxy Settings**. See @proxy-settings for proxy-specific troubleshooting, including the **AnalysisServices.AppSettings.json** override that enables external MSAL proxy support.
3. If the network blocks outbound traffic to the activation endpoint, use [Manual activation](#manual-activation-no-internet) below.
-
## Manual activation (no internet)
If the machine running Tabular Editor cannot reach the activation endpoint, the activation prompt offers a manual flow.
diff --git a/content/tutorials/calendars.md b/content/tutorials/calendars.md
index e9dab3f7f..dbf139ed2 100644
--- a/content/tutorials/calendars.md
+++ b/content/tutorials/calendars.md
@@ -163,7 +163,6 @@ When a Primary time unit column has a **Sort By** column defined, the Sort By co
For example, if you map a `MonthName` column to "Month of Year" and `MonthName` is sorted by a `MonthNumber` column, the `MonthNumber` column is automatically associated with the time unit. You don't need to manually add the Sort By column to the Associated Columns panel—the Calendar Editor handles this automatically.
-
### Time-Related Columns
In addition to mapping columns to specific time unit categories, you can mark columns as **time-related**. Time-related columns are columns in your Date table that don't fit into a specific time unit category but should still receive special treatment during time intelligence calculations.
diff --git a/content/tutorials/direct-lake-guidance.md b/content/tutorials/direct-lake-guidance.md
index db8c41484..760e3ee5c 100644
--- a/content/tutorials/direct-lake-guidance.md
+++ b/content/tutorials/direct-lake-guidance.md
@@ -61,7 +61,6 @@ Direct Lake on OneLake also supports combining with DirectQuery tables through X
> [!NOTE]
> Direct Lake on SQL does not support composite models. You cannot combine Direct Lake on SQL tables with Import, DirectQuery or Dual storage mode tables in the same semantic model. However, you can use Power BI Desktop to create a composite model *on top of* a Direct Lake on SQL semantic model and extend it with new tables. See [Build a composite model on a semantic model](https://learn.microsoft.com/en-us/power-bi/transform-model/desktop-composite-models#building-a-composite-model-on-a-semantic-model-or-model) for more information.
-
## Collation
When using **Direct Lake on OneLake**, the collation of the model is the same as for an Import model, which is case-insensitive by default.
diff --git a/content/tutorials/incremental-refresh/incremental-refresh-about.md b/content/tutorials/incremental-refresh/incremental-refresh-about.md
index 8313503c8..87a1ac423 100644
--- a/content/tutorials/incremental-refresh/incremental-refresh-about.md
+++ b/content/tutorials/incremental-refresh/incremental-refresh-about.md
@@ -199,7 +199,6 @@ in
***
-
#### Overview of all properties
_Below is an overview of the TOM Properties in a data model used to configure Incremental Refresh:_
diff --git a/content/tutorials/udfs.md b/content/tutorials/udfs.md
index 776847d80..216e7afe0 100644
--- a/content/tutorials/udfs.md
+++ b/content/tutorials/udfs.md
@@ -200,7 +200,6 @@ UDFs appear in the **DAX Dependencies** (Shift+F12) view, showing both:
When you select multiple UDFs in the TOM Explorer, you can use the **Batch Rename** (F2) option from the right-click context menu to rename them all at once, using search-and-replace patterns, and optionally regular expressions.
-
### Namespaces
The concept of "namespace" doesn't exist in DAX, yet the recommendation is to name UDFs in such a way that ambiguities are avoided and that the origin of the UDF is clear. For example `DaxLib.Convert.CelsiusToFahrenheit` (using '.' as namespace separators). When a UDF is named this way, the TOM Explorer will display the UDF in a hierarchy based on the names. You can toggle the display of UDFs by namespace using the **Group User-Defined Functions by namespace** toggle button in the toolbar above the TOM Explorer (note, this button is only visible when working with a model using Compatibility Level 1702 or higher).