-2.按F12键打开Chrome开发者工具;
-3.点开“Network”,将“Preserve log”选中,输入微博的用户名、密码,登录,如图所示: -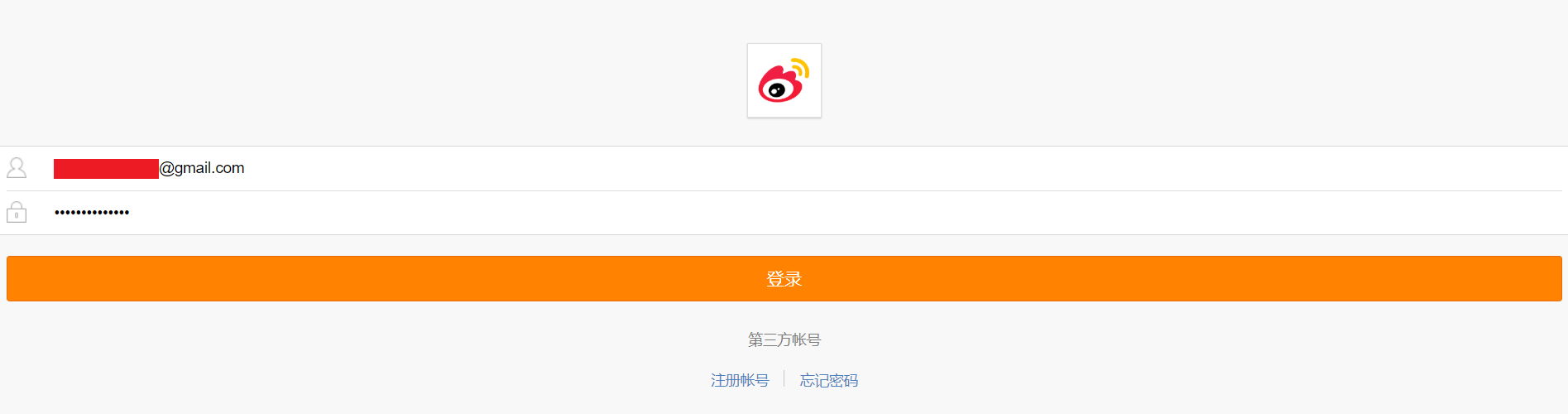 -4.点击Chrome开发者工具“Name"列表中的"m.weibo.cn",点击"Headers",其中"Request Headers"下,"Cookie"后的值即为我们要找的cookie值,复制即可,如图所示: -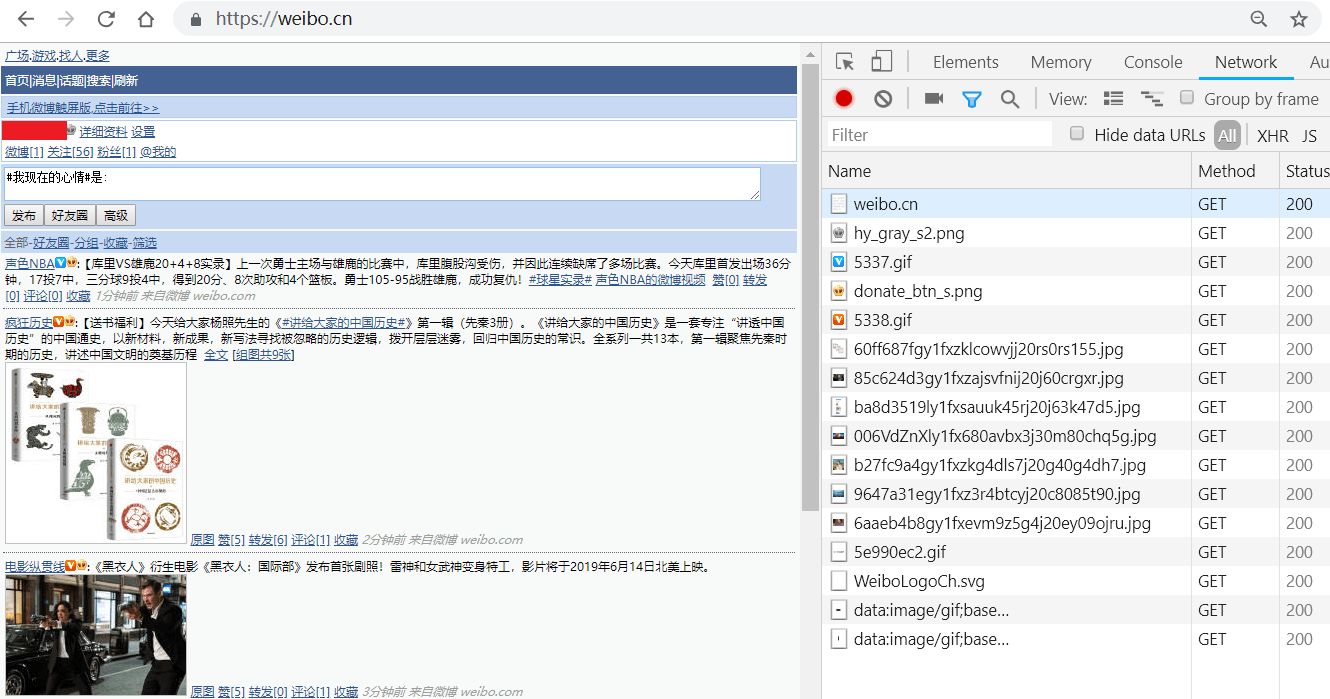 - -# 如何获取user_id -1.打开网址
-2.大部分情况下,在用户主页的地址栏里就包含了user_id,如”郭碧婷“的地址栏地址为"
-2.cookie有期限限制,大约有几天的有效期,超过有效期需重新更新cookie。 +程序会获取user_id分别为1669879400和1223178222的微博用户的微博,后面会讲[如何获取user_id](#如何获取user_id)。该方式的所有user_id使用config.json中的since_date和end_date设置,通过修改它们的值可以控制爬取的时间范围。若config.json中的user_id_list是文件路径,每个命令行中的user_id都会自动保存到该文件内,且自动更新since_date;若不是路径,user_id会保存在当前目录的user_id_list.txt内,且自动更新since_date,若当前目录下不存在user_id_list.txt,程序会自动创建它。 + +## 个性化定制程序(可选) + +本部分为可选部分,如果不需要个性化定制程序或添加新功能,可以忽略此部分。 + +本程序主体代码位于weibo_spider.py文件,程序主体是一个 Spider 类,上述所有功能都是通过在main函数调用 Spider 类实现的,默认的调用代码如下: + +```python + config = get_config() + wb = Spider(config) + wb.start() # 爬取微博信息 +``` + +用户可以按照自己的需求调用或修改 Spider 类。通过执行本程序,我们可以得到很多信息。 + +
+
+
+
+**wb.weibo**:除不包含上述信息外,wb.weibo包含爬取到的所有微博信息,如**微博id**、**微博正文**、**原始图片url**、**发布位置**、**发布时间**、**发布工具**、**点赞数**、**转发数**、**评论数**等。如果爬的是全部微博(原创+转发),除上述信息之外,还包含被**转发微博原始图片url**、**是否为原创微博**等。wb.weibo是一个列表,包含了爬取的所有微博信息。wb.weibo[0]为爬取的第一条微博,wb.weibo[1]为爬取的第二条微博,以此类推。当filter=1时,wb.weibo[0]为爬取的第一条**原创**微博,以此类推。wb.weibo[0]['id']为第一条微博的id,wb.weibo[0]['content']为第一条微博的正文,wb.weibo[0]['publish_time']为第一条微博的发布时间,还有其它很多信息不在赘述,大家可以点击下面的"详情"查看具体用法。
+
+点击查看详情
+ +- wb.user['nickname']:用户昵称; +- wb.user['gender']:用户性别; +- wb.user['location']:用户所在地; +- wb.user['birthday']:用户出生日期; +- wb.user['description']:用户简介; +- wb.user['verified_reason']:用户认证; +- wb.user['talent']:用户标签; +- wb.user['education']:用户学习经历; +- wb.user['work']:用户工作经历; +- wb.user['weibo_num']:微博数; +- wb.user['following']:关注数; +- wb.user['followers']:粉丝数; + +
+
+
+
+## 定期自动爬取微博(可选)
+
+要想让程序每隔一段时间自动爬取,且爬取的内容为新增加的内容(不包括已经获取的微博),请查看[定期自动爬取微博](https://github.com/dataabc/weiboSpider/blob/master/docs/automation.md)。
+
+## 如何获取cookie
+
+要了解获取cookie方法,请查看[cookie文档](https://github.com/dataabc/weiboSpider/blob/master/docs/cookie.md)。
+
+## 如何获取user_id
+
+要了解获取user_id方法,请查看[user_id文档](https://github.com/dataabc/weiboSpider/blob/master/docs/userid.md),该文档介绍了如何获取一个及多个微博用户user_id的方法。
+
+## 常见问题
+
+如果运行程序的过程中出现错误,可以查看[常见问题](https://github.com/dataabc/weiboSpider/blob/master/docs/FAQ.md)页面,里面包含了最常见的问题及解决方法。如果出现的错误不在常见问题里,您可以通过[发issue](https://github.com/dataabc/weiboSpider/issues/new/choose)寻求帮助,我们会很乐意为您解答。
+
+## 学术研究
+
+本项目通过获取微博数据,为写论文、做研究等非商业项目提供所需数据。[学术研究文档](https://github.com/dataabc/weiboSpider/blob/master/docs/academic.md)是一些在论文或研究等方面使用过本程序的项目,这些项目展示已征得所有者同意。在一些涉及隐私的描述上,已与所有者做了沟通,描述中只介绍所有者允许展示的部分。如果部分信息所有者之前同意展示并且已经写在了文档中,现在又不想展示了,可以通过邮件(chillychen1991@gmail.com)或issue的方式告诉我,我会删除相关信息。同时,也欢迎使用本项目写论文或做其它学术研究的朋友,将自己的研究成果展示在[学术研究文档](https://github.com/dataabc/weiboSpider/blob/master/docs/academic.md)里,这完全是自愿的。
+
+为方便大家引用,现提供本项目的 bibtex 条目如下:
+
+```
+@misc{weibospider2020,
+ author = {Lei Chen, Zhengyang Song, schaepher, minami9, bluerthanever, MKSP2015, moqimoqidea, windlively, eggachecat, mtuwei, codermino, duangan1},
+ title = {{Weibo Spider}},
+ howpublished = {\url{https://github.com/dataabc/weiboSpider}},
+ year = {2020}
+}
+```
+
+## 相关项目
+
+- [weibo-crawler](https://github.com/dataabc/weibo-crawler) - 功能和本项目完全一样,可以不添加cookie,获取的微博属性更多;
+- [weibo-search](https://github.com/dataabc/weibo-search) - 可以连续获取一个或多个**微博关键词搜索**结果,并将结果写入文件(可选)、数据库(可选)等。所谓微博关键词搜索即:**搜索正文中包含指定关键词的微博**,可以指定搜索的时间范围。对于非常热门的关键词,一天的时间范围,可以获得**1000万**以上的搜索结果,N天的时间范围就可以获得1000万 X N搜索结果。对于大多数关键词,一天产生的相应微博数量应该在1000万条以下,因此可以说该程序可以获得大部分关键词的全部或近似全部的搜索结果。而且该程序可以获得搜索结果的所有信息,本程序获得的微博信息该程序都能获得。
+
+## 贡献
+
+欢迎为本项目贡献力量。贡献可以是提交代码,可以是通过issue提建议(如新功能、改进方案等),也可以是通过issue告知我们项目存在哪些bug、缺点等,具体贡献方式见[为本项目做贡献](https://github.com/dataabc/weiboSpider/blob/master/CONTRIBUTING.md)。
+
+## 贡献者
+
+感谢所有为本项目贡献力量的朋友,贡献者详情见[贡献者](https://github.com/dataabc/weiboSpider/blob/master/docs/contributors.md)页面。
+
+## 注意事项
+
+1. user_id不能为爬虫微博的user_id。因为要爬微博信息,必须先登录到某个微博账号,此账号我们姑且称为爬虫微博。爬虫微博访问自己的页面和访问其他用户的页面,得到的网页格式不同,所以无法爬取自己的微博信息;如果想要爬取爬虫微博内容,可以参考[获取自身微博信息](https://github.com/dataabc/weiboSpider/issues/113);
+2. cookie有期限限制,大约三个月。若提示cookie错误或已过期,需要重新更新cookie。
diff --git a/docs/FAQ.md b/docs/FAQ.md
new file mode 100644
index 00000000..14e41657
--- /dev/null
+++ b/docs/FAQ.md
@@ -0,0 +1,45 @@
+# 常见问题
+
+## 1. 程序运行出错,错误提示中包含“ImportError: cannot import name 'config_util' from '__main__'”,如何解决?
+
+出现这种错误,说明使用者很可能是直接运行的.py文件,程序正确的运行方式是在weiboSpider目录下,运行如下命令:
+
+```bash
+python3 -m weibo_spider
+```
+
+## 2. 程序运行出错,错误提示中包含“'NoneType' object”字样,如何解决?
+
+这是最常见的问题之一。出错原因是爬取速度太快,被暂时限制了,限制可能包含爬虫账号限制和ip限制。一般情况下,一段时间后限制会自动解除。可通过降低爬取速度避免被限制,具体修改config.json文件中的如下代码:
+
+```json
+ "random_wait_pages": [1, 5],
+ "random_wait_seconds": [6, 10],
+ "global_wait": [[1000, 3600], [500, 2000]],
+```
+
+前两行的意思是每爬取1到5页,随机等待6到10秒。可以通过加快暂停频率(减小random_wait_pages内的值)或增加等待时间(加大random_wait_seconds内的值)避免被限制。最后一行的意思是获取1000页微博,一次性等待3600秒;之后获取500页微博一次性等待2000秒。默认只有两个global_wait配置([1000, 3600]和[500, 2000]),可以添加更多个,也可以自定义。当配置使用完,如默认配置在获取1500(1000+500)页微博后就用完了,之后程序会从第一个配置开始循环使用(获取第1501页到2500页等待3600秒,获取第2501页到第3000页等待2000秒,以此类推)。
+
+## 3. 如何获取微博评论?
+
+因为限制,只能获取一部分评论,无法获取全部,因此暂时没有添加获取评论功能的计划。
+
+## 4. 有的长微博正文只能获取一部分内容,如何解决?
+
+程序是可以获取长微博全文的。程序首先在微博列表页获取微博,如果发现长微博(正文没有显示完整,以“全文”代替部分内容的微博),会先保存这个不全的内容,然后去该长微博的详情页尝试获取全文,如果获取成功,获取的内容就是微博文本;如果获取失败,等待若干秒重新获取;如果连续尝试5次都失败,就用上面不全的内容代替。这样做的原因是避免因部分长微博获取失败而卡住。如果想尝试更多次,可以修改comment_parser.py文件get_long_weibo方法内for循环的次数。
+
+## 5. 如何按指定关键词获取微博?
+
+请使用[weibo-search](https://github.com/dataabc/weibo-search)。该程序可以连续获取一个或多个微博关键词搜索结果,并将结果写入文件(可选)、数据库(可选)等。所谓微博关键词搜索即:搜索正文中包含指定关键词的微博,可以指定搜索的时间范围。对于非常热门的关键词,一天的时间范围,可以获得1000万以上的搜索结果,N天的时间范围就可以获得1000万 X N搜索结果。对于大多数关键词,一天产生的相应微博数量应该在1000万条以下,因此可以说该程序可以获得大部分关键词的全部或近似全部的搜索结果。而且该程序可以获得搜索结果的所有信息,本程序获得的微博信息该程序都能获得。
+
+## 6. 如何获取微博用户关注列表中用户的user_id?
+
+请使用[weibo-follow](https://github.com/dataabc/weibo-follow)。该程序可以利用一个user_id,获取该user_id微博用户关注人的user_id,一个user_id最多可以获得200个user_id,并写入user_id_list.txt文件。程序支持读文件,利用这200个user_id,可以获得最多200X200=40000个user_id。再利用这40000个user_id可以得到40000X200=8000000个user_id,如此反复,以此类推,可以获得大量user_id。本项目也支持读文件,将上述程序的结果文件user_id_list.txt路径赋值给本项目config.json的user_id_list参数,就可以获得这些user_id用户所发布的大量微博。
+
+## 7. 如何获取自己的微博?
+
+修改page_parser.py中__init__方法,将self.url修改为:
+
+```python
+ self.url = "https://weibo.cn/%s/profile?page=%d" % (self.user_uri, page)
+```
diff --git a/docs/academic.md b/docs/academic.md
new file mode 100644
index 00000000..1f378eaa
--- /dev/null
+++ b/docs/academic.md
@@ -0,0 +1,8 @@
+# 学术研究
+
+本项目通过获取微博数据,为写论文、做研究等非商业项目提供所需数据。下面是一些在论文或研究等方面使用过本程序的项目。在一些涉及隐私的描述上,已与研究者做了沟通,在下面的描述中只介绍研究者
+允许展示的部分。如果部分信息研究者之前同意展示并且已经写在了本文档中,现在又不想展示了,可以通过邮件(chillychen1991@gmail.com)或issue的方式告诉我,我会删除相关信息。同时,使用本项目写论文或做其它学术研究的朋友,如果想把自己的研究成果展示在下面,也可以通过邮件或issue的方式告诉我。
+
+***
+
+- 英国伦敦国王学院[Mak-LokGay](https://github.com/Mak-LokGay)的[毕业论文](https://github.com/Mak-LokGay/KCL_Dissertation)
diff --git a/docs/automation.md b/docs/automation.md
new file mode 100644
index 00000000..2d8970dc
--- /dev/null
+++ b/docs/automation.md
@@ -0,0 +1,58 @@
+# 定期自动爬取微博(可选)
+
+我们爬取了微博以后,很多微博账号又可能发了一些新微博,定期自动爬取微博就是每隔一段时间自动运行程序,自动爬取这段时间产生的新微博(忽略以前爬过的旧微博)。本部分为可选部分,如果不需要可以忽略。
+
+思路是**利用第三方软件,如crontab,让程序每隔一段时间运行一次**。因为是要跳过以前爬过的旧微博,只爬新微博。所以需要**设置一个动态的since_date**。很多时候我们使用的since_date是固定的,比如since_date="2018-01-01",程序就会按照这个设置从最新的微博一直爬到发布时间为2018-01-01的微博(包括这个时间)。因为我们想追加新微博,跳过旧微博。第二次爬取时since_date值就应该是当前时间到上次爬取的时间。
+如果我们使用最原始的方式实现追加爬取,应该是这样:
+
+```text
+假如程序第一次执行时间是2019-06-06,since_date假如为2018-01-01,那这一次就是爬取从2018-01-01到2019-06-06这段时间用户所发的微博;
+第二次爬取,我们想要接着上次的爬,那since_date的值应该是上次程序执行的日期,即2019-06-06
+```
+
+上面的方法太麻烦,因为每次都要手动设置since_date。因此我们需要动态设置since_date,即程序根据实际情况,自动生成since_date。
+
+有两种方法实现动态更新since_date,**推荐使用方法二**。
+
+## 方法一:将since_date设置成整数
+
+将config.json文件中的since_date设置成整数,如:
+
+```json
+"since_date": 10,
+```
+
+这个配置告诉程序爬取最近10天的微博,更准确说是爬取发布时间从**10天前到本程序开始执行时**之间的微博。这样since_date就是一个动态的变量,每次程序执行时,它的值就是当前日期减10。配合crontab每9天或10天执行一次,就实现了定期追加爬取。
+
+## 方法二:将上次执行程序的时间写入文件(推荐)
+
+这个方法很简单,就是使用[程序设置](https://github.com/dataabc/weiboSpider/blob/master/docs/settings.md)中**设置user_id_list**的第二种方法设置user_id_list,这样设置就全部结束了。
+
+说下这个方法的好处和原理,假如你的txt文件内容为:
+
+```text
+1669879400
+1223178222 胡歌
+1729370543 郭碧婷 2019-01-01 19:28
+```
+
+第一次执行时,因为第一行和第二行都没有写时间,程序会按照config.json文件中since_date的值爬取,第三行有时间“2019-01-01 19:28”,程序就会把这个时间当作since_date。每个用户爬取结束程序都会自动更新txt文件,每一行第一部分是user_id,第二部分是用户昵称,第三部分是程序**准备**爬取该用户第一条微博(最新微博)时的时间。爬完三个用户后,txt文件的内容自动更新为:
+
+```text
+1669879400 Dear-迪丽热巴 2020-01-13 19:18
+1223178222 胡歌 2020-01-13 19:28
+1729370543 郭碧婷 2020-01-13 19:33
+```
+
+下次再爬取微博的时候,程序会把每行的时间数据作为since_date。这样的好处一是不用修改since_date,程序自动更新;二是每一个用户都可以单独拥有只属于自己的since_date,每个用户的since_date相互独立,互不干扰。since_date既可以是“yyyy-mm-dd”格式,也可以是“yyyy-mm-dd hh:mm”格式。比如,现在又添加了一个新用户,例如杨紫,你想获取她从2018-01-23到现在的全部微博,只需要这样修改txt文件:
+
+```text
+1669879400 Dear-迪丽热巴 2020-01-13 19:18
+1223178222 胡歌 2020-01-13 19:28
+1729370543 郭碧婷 2020-01-13 19:33
+1227368500 杨紫 2018-01-23
+```
+
+注意每一行的用户配置参数以空格分隔,如果第一个参数全部由数字组成,程序就认为此行为一个用户的配置,否则程序会认为该行只是注释,跳过该行;第二个参数可以为任意格式,建议写用户昵称;第三个如果是日期格式(yyyy-mm-dd),程序就将该日期设置为用户自己的since_date,否则使用config.json中的since_date爬取该用户的微博,第二个参数和第三个参数也可以不填。
+
+推荐第二种方法,本方法是[Evifly](https://github.com/Evifly)想出的,非常热心非常有想法的网友,在此感谢。
diff --git a/docs/contributors.md b/docs/contributors.md
new file mode 100644
index 00000000..a58eb5c9
--- /dev/null
+++ b/docs/contributors.md
@@ -0,0 +1,26 @@
+# 贡献者
+
+感谢所有为本项目作出贡献和将要作出贡献的朋友,感谢对开源事业的支持。大家每贡献一行code都让项目功能更丰富,每提一个建议都让程序更完善,每发现一个bug都让代码更健壮。
+
+本项目贡献者包含三部分:主要代码开发者、代码贡献者和优质issue提出者。以下按贡献者的用户名首字母排序,若某贡献者在多部分都有贡献,则以主要贡献为准。
+
+## 主要代码开发者
+
+| [dataabc](https://github.com/dataabc) | [songzy12](https://github.com/songzy12) |
+| - | - |
+
+## 代码贡献者
+
+| [codermino](https://github.com/codermino) | [duangan1](https://github.com/duangan1) | [MKSP2015](https://github.com/MKSP2015) |
+| - | - | - |
+
+## 优质issue提出者
+
+| | | | | | |
+| - | - | - | - | - | - |
+| [13531982270](https://github.com/13531982270) | [Archenemy61](https://github.com/Archenemy61) | [arctanx](https://github.com/arctanx) | [bossming](https://github.com/bossming) | [bubblesran](https://github.com/bubblesran) | [cangling](https://github.com/cangling)|
+| [Ccccche](https://github.com/Ccccche) | [Evifly](https://github.com/Evifly) | [gudaost](https://github.com/gudaost) | [Hylan129](https://github.com/Hylan129) | [HZzzzy](https://github.com/HZzzzy) | [kur0mi](https://github.com/kur0mi) |
+| [leonall](https://github.com/leonall) | [liu-song](https://github.com/liu-song) | [Issac110](https://github.com/Issac110) | [MengyingQian](https://github.com/MengyingQian) | [PandGnone](https://github.com/PandGnone) | [PLQin](https://github.com/PLQin) |
+| [redMUSCLE](https://github.com/redMUSCLE) | [shengdade](https://github.com/shengdade) | [softrime](https://github.com/softrime) | [SugimitoYuuji](https://github.com/SugimitoYuuji) | [sunbat](https://github.com/sunbat) | [taichifox95](https://github.com/taichifox95) |
+| [Twinklingcode](https://github.com/Twinklingcode) | [vincentlee5](https://github.com/vincentlee5) | [wiidi](https://github.com/wiidi) | [wwwpf](https://github.com/wwwpf) | [xiaomingdaily](https://github.com/xiaomingdaily) | [xiekeyi98](https://github.com/xiekeyi98) |
+| [xnzmc](https://github.com/xnzmc) | [yangy9593](https://github.com/yangy9593) | [zhangjibao](https://github.com/zhangjibao) |
diff --git a/docs/cookie.md b/docs/cookie.md
new file mode 100644
index 00000000..57db59cf
--- /dev/null
+++ b/docs/cookie.md
@@ -0,0 +1,10 @@
+# 如何获取cookie
+
+1. 用Chrome打开详情
+ +若目标微博用户存在微博,则: + +- id:存储微博id。如wb.weibo[0]['id']为最新一条微博的id; +- content:存储微博正文。如wb.weibo[0]['content']为最新一条微博的正文; +- article_url:存储微博中头条文章的url。如wb.weibo[0]['article_url']为最新一条微博的头条文章url,若微博中不存在头条文章,则值为''; +- original_pictures:存储原创微博的原始图片url和转发微博转发理由中的图片url。如wb.weibo[0]['original_pictures']为最新一条微博的原始图片url,若该条微博有多张图片,则存储多个url,以英文逗号分割;若该微博没有图片,则值为"无"; +- retweet_pictures:存储被转发微博中的原始图片url。当最新微博为原创微博或者为没有图片的转发微博时,则值为"无",否则为被转发微博的图片url。若有多张图片,则存储多个url,以英文逗号分割; +- publish_place:存储微博的发布位置。如wb.weibo[0]['publish_place']为最新一条微博的发布位置,如果该条微博没有位置信息,则值为"无"; +- publish_time:存储微博的发布时间。如wb.weibo[0]['publish_time']为最新一条微博的发布时间; +- up_num:存储微博获得的点赞数。如wb.weibo[0]['up_num']为最新一条微博获得的点赞数; +- retweet_num:存储微博获得的转发数。如wb.weibo[0]['retweet_num']为最新一条微博获得的转发数; +- comment_num:存储微博获得的评论数。如wb.weibo[0]['comment_num']为最新一条微博获得的评论数; +- publish_tool:存储微博的发布工具。如wb.weibo[0]['publish_tool']为最新一条微博的发布工具。 + +
+
+
+
+## 设置API接口POST联动(可选)
+
+本部分是可选部分,如果不需要将爬取信息通过POST请求发送到指定API接口,可跳过这一步
+
+请求数据格式为 `content-type : application/json`,接口响应返回也需要是 `content-type : application/json`,HTTP状态码为 `200`
+
+数据主体与 `write_mode` 配置的 `json` 输出格式一致,是整页获取数据json,每页POST发送一次
+
+`api_url` 为指定的API接口地址
+
+`api_token` 为接口鉴权TOKEN,将在 Request Headers 中添加 `api-token` 字段,根据需要配置
\ No newline at end of file
diff --git a/docs/userid.md b/docs/userid.md
new file mode 100644
index 00000000..68d2e595
--- /dev/null
+++ b/docs/userid.md
@@ -0,0 +1,16 @@
+## 如何获取user_id
+
+1. 打开网址详情
+ +- **user表** +- **id**:存储用户id,如"1669879400"; +- **nickname**:存储用户昵称,如"Dear-迪丽热巴"; +- **gender**:存储用户性别; +- **location**:存储用户所在地; +- **birthday**:存储用户出生日期; +- **description**:存储用户简介; +- **verified_reason**:存储用户认证; +- **talent**:存储用户标签; +- **education**:存储用户学习经历; +- **work**:存储用户工作经历; +- **weibo_num**:存储微博数; +- **following**:存储关注数; +- **followers**:存储粉丝数。 + +*** + +- **weibo表** +- **id**:存储微博id; +- **user_id**:存储微博发布者的用户id,如"1669879400"; +- **content**:存储微博正文; +- **article_url**:存储微博中头条文章的url,若微博中不存在头条文章,则值为''; +- **original_pictures**:存储原创微博的原始图片url和转发微博转发理由中的图片url。若某条微博有多张图片,则存储多个url,以英文逗号分割;若某微博没有图片,则值为"无"; +- **retweet_pictures**:存储被转发微博中的原始图片url。当最新微博为原创微博或者为没有图片的转发微博时,则值为"无",否则为被转发微博的图片url。若有多张图片,则存储多个url,以英文逗号分割; +- **publish_place**:存储微博的发布位置。如果某条微博没有位置信息,则值为"无"; +- **publish_time**:存储微博的发布时间; +- **up_num**:存储微博获得的点赞数; +- **retweet_num**:存储微博获得的转发数; +- **comment_num**:存储微博获得的评论数; +- **publish_tool**:存储微博的发布工具。 + +Dear-迪丽热巴的微博 加关注
微博 相册

炎炎夏日让每天的沐浴时光都变得尤其重要,精致的沙龙香相伴让沐浴也可以成为清新浪漫的享受!给大家@LUX力士 的沐浴小秘密分享,有力士植萃沐浴露,把沐浴变成“仪式感”!我的心选好物分享给你们啦 ![[笑而不语]](//h5.sinaimg.cn/m/emoticon/icon/default/d_heiheihei-f7ca09d6e8.png) LUX力士的微博视频
LUX力士的微博视频
赞[377578] 转发[1000000] 评论[1000000] 收藏 2020-05-31 10:59
赞[377578] 转发[1000000] 评论[1000000] 收藏 2020-05-31 10:59
#idoltube##周放vlog# 第二篇来啦!今天邀请大家走进生活,走进幸福的放放子一家~![[喵喵]](//h5.sinaimg.cn/m/emoticon/icon/others/d_miao-61fe2a7aaa.png) #幸福触手可及# Dear-迪丽热巴的微博视频
#幸福触手可及# Dear-迪丽热巴的微博视频
赞[397970] 转发[1000000] 评论[1000000] 收藏 2020-05-30 19:02 来自国产剧集 · 视频社区
赞[397970] 转发[1000000] 评论[1000000] 收藏 2020-05-30 19:02 来自国产剧集 · 视频社区
@法国娇韵诗 收到宠爱了~小娇的618#娇宠你有一套#,早晚护肤都靠它,超级喜欢这份宠爱!现在给全体爱丽丝们施法,希望你们都可以拥有这份让你变美的娇宠礼物哦~同款娇宠http://t.cn/A62cgDJp一起享用! [组图共2张]

#微博剧场# 我为4A景区代言,酷飒周放的追剧邀请,你来吗? #4A景区触手可及#



转发了 护舒宝
 的微博:还记得和宝宝陪着@Dear-迪丽热巴 走过的花路吗?谢谢阿丝们一直以来的陪伴
的微博:还记得和宝宝陪着@Dear-迪丽热巴 走过的花路吗?谢谢阿丝们一直以来的陪伴![[太开心]](//h5.sinaimg.cn/m/emoticon/icon/default/d_taikaixin-97bd3f82d6.png) ~为你甄选护舒宝天然纯棉卫生巾,给你透气亲肤的体验。现在上天猫超市购买,1套减25,第2套只要19.9。未来的花路,和宝宝一起用好物,守护热巴!#迪丽热巴[超话]#
~为你甄选护舒宝天然纯棉卫生巾,给你透气亲肤的体验。现在上天猫超市购买,1套减25,第2套只要19.9。未来的花路,和宝宝一起用好物,守护热巴!#迪丽热巴[超话]#
的微博:还记得和宝宝陪着@Dear-迪丽热巴 走过的花路吗?谢谢阿丝们一直以来的陪伴
#idoltube##周放vlog# 放放子的第一支搞事业篇vlog已上线~约vlog的朋友们可以放下你们的号码牌了![[可爱]](//h5.sinaimg.cn/m/emoticon/icon/default/d_keai-7a5bf88086.png) #幸福触手可及# Dear-迪丽热巴的微博视频
#幸福触手可及# Dear-迪丽热巴的微博视频
赞[450541] 转发[1000000] 评论[216934] 收藏 2020-05-25 20:53 来自影视剪辑 · 视频社区
赞[450541] 转发[1000000] 评论[216934] 收藏 2020-05-25 20:53 来自影视剪辑 · 视频社区

weibo.cn[06-19 00:47]
diff --git a/tests/testdata/4957814af5a123b82e974b5537dea736dfb34e48d8835203a45d2e67.html b/tests/testdata/4957814af5a123b82e974b5537dea736dfb34e48d8835203a45d2e67.html
new file mode 100644
index 00000000..23803ea5
--- /dev/null
+++ b/tests/testdata/4957814af5a123b82e974b5537dea736dfb34e48d8835203a45d2e67.html
@@ -0,0 +1 @@
+ |
微博 相册

刚收到我定制的亓那眼镜,猜猜定制了什么![[doge]](//h5.sinaimg.cn/m/emoticon/icon/others/d_doge-861403219c.png) 好奇?没关系,你们也可以拥有自己的定制眼镜。关注@QINA亓那眼镜 解锁6月限定惊喜,#时髦寻宝计划# 线上线下都安排了
好奇?没关系,你们也可以拥有自己的定制眼镜。关注@QINA亓那眼镜 解锁6月限定惊喜,#时髦寻宝计划# 线上线下都安排了![[偷笑]](//h5.sinaimg.cn/m/emoticon/icon/default/d_touxiao-15afb1c739.png) QINA亓那眼镜的微博视频
QINA亓那眼镜的微博视频
赞[415899] 转发[1000000] 评论[1000000] 收藏 06月15日 10:09
赞[415899] 转发[1000000] 评论[1000000] 收藏 06月15日 10:09
#idoltube##周放vlog# 什么?放放子还有两副面孔呢? #幸福触手可及# Dear-迪丽热巴的微博视频
赞[318054] 转发[1000000] 评论[514546] 收藏 06月14日 20:09 来自影视剪辑 · 视频社区
赞[318054] 转发[1000000] 评论[514546] 收藏 06月14日 20:09 来自影视剪辑 · 视频社区

言出必行,说了18张就是18张,送给七千万的你们 ~ [组图共18张]

放放子缺个快板 绿洲

#出手吧兄弟# 今晚20:10,我在湖南卫视 ,为湖南永州的夏橙出手! #出手吧兄弟节目单#

转发了 WCS野生生物保护学会 的微博:去年和亲善大使热巴@Dear-迪丽热巴 的特别回忆![[心]](//h5.sinaimg.cn/m/emoticon/icon/others/l_xin-6912791858.png) 。我们在藏北羌塘一起爬山,探访藏羚羊、雪豹、黑颈鹤的栖息地,感受野生动物保护工作的点滴。此时此刻,我们比以往更加重视与自然相处的方式,我们也从未如此迫切需要将想法付诸行动。热巴已经和我们@北京绿色阳光 站在一起,希望看完视频的你们,也...全文 赞[119296] 原文转发[1000000] 原文评论[38688]
。我们在藏北羌塘一起爬山,探访藏羚羊、雪豹、黑颈鹤的栖息地,感受野生动物保护工作的点滴。此时此刻,我们比以往更加重视与自然相处的方式,我们也从未如此迫切需要将想法付诸行动。热巴已经和我们@北京绿色阳光 站在一起,希望看完视频的你们,也...全文 赞[119296] 原文转发[1000000] 原文评论[38688]
的微博:去年和亲善大使热巴@Dear-迪丽热巴 的特别回忆转发理由:在羌塘的美好回忆~第一次来到这片独特的荒野,看到野生动物自由生活,还有一群快乐可爱的人在守护着它们。把这些美好留存下来,关注野生动物保护,积极行动,我们每个人都能贡献力量。
赞[554415] 转发[1000000] 评论[1000000] 收藏 06月05日 11:11
赞[554415] 转发[1000000] 评论[1000000] 收藏 06月05日 11:11
要开心。要充实。

#微博live秀# 28岁的直播~@Dear-迪丽热巴 的一直播(下载App->http://t.cn/RDUuslr)
赞[435650] 转发[23584] 评论[1000000] 收藏 06月03日 19:00 来自一直播Yi
赞[435650] 转发[23584] 评论[1000000] 收藏 06月03日 19:00 来自一直播Yi
weibo.cn[06-19 00:47]
diff --git a/tests/testdata/4d5ed0a3ebd0303cb45edd544dbc0ab5e86d43e103405f0c60515884.html b/tests/testdata/4d5ed0a3ebd0303cb45edd544dbc0ab5e86d43e103405f0c60515884.html
new file mode 100644
index 00000000..9cb503c5
--- /dev/null
+++ b/tests/testdata/4d5ed0a3ebd0303cb45edd544dbc0ab5e86d43e103405f0c60515884.html
@@ -0,0 +1 @@
+ Dear-迪丽热巴 转发了 @WCS野生生物保护学会 的微博:去年和亲善大使热巴@Dear-迪丽热巴 的特别回忆。我们在藏北羌塘一起爬山,探访藏羚羊、雪豹、黑颈鹤的栖息地,感受野生动物保护工作的点滴。此时此刻,我们比以往更加重视与自然相处的方式,我们也从未如此迫切需要将想法付诸行动。热巴已经和我们@北京绿色阳光 站在一起,希望看完视频的你们,也能获得同样感受与动力。
转发了 @WCS野生生物保护学会 的微博:去年和亲善大使热巴@Dear-迪丽热巴 的特别回忆。我们在藏北羌塘一起爬山,探访藏羚羊、雪豹、黑颈鹤的栖息地,感受野生动物保护工作的点滴。此时此刻,我们比以往更加重视与自然相处的方式,我们也从未如此迫切需要将想法付诸行动。热巴已经和我们@北京绿色阳光 站在一起,希望看完视频的你们,也能获得同样感受与动力。
We Stand for Wildlife.
明日朝阳68309的优酷视频 原文转发[1000000] 原文评论[38688]
转发了 @WCS野生生物保护学会 的微博:去年和亲善大使热巴@Dear-迪丽热巴 的特别回忆We Stand for Wildlife.
明日朝阳68309的优酷视频 原文转发[1000000] 原文评论[38688]




















 |
微博 相册
刚收到我定制的亓那眼镜,猜猜定制了什么好奇?没关系,你们也可以拥有自己的定制眼镜。关注@QINA亓那眼镜 解锁6月限定惊喜,#时髦寻宝计划# 线上线下都安排了QINA亓那眼镜的微博视频
赞[415899] 转发[1000000] 评论[1000000] 收藏 06月15日 10:09
赞[415899] 转发[1000000] 评论[1000000] 收藏 06月15日 10:09
#idoltube##周放vlog# 什么?放放子还有两副面孔呢? #幸福触手可及# Dear-迪丽热巴的微博视频
赞[318054] 转发[1000000] 评论[514546] 收藏 06月14日 20:09 来自影视剪辑 · 视频社区
赞[318054] 转发[1000000] 评论[514546] 收藏 06月14日 20:09 来自影视剪辑 · 视频社区
言出必行,说了18张就是18张,送给七千万的你们 ~ [组图共18张]
放放子缺个快板 绿洲
#出手吧兄弟# 今晚20:10,我在湖南卫视 ,为湖南永州的夏橙出手! #出手吧兄弟节目单#
转发了 WCS野生生物保护学会 的微博:去年和亲善大使热巴@Dear-迪丽热巴 的特别回忆。我们在藏北羌塘一起爬山,探访藏羚羊、雪豹、黑颈鹤的栖息地,感受野生动物保护工作的点滴。此时此刻,我们比以往更加重视与自然相处的方式,我们也从未如此迫切需要将想法付诸行动。热巴已经和我们@北京绿色阳光 站在一起,希望看完视频的你们,也...全文 赞[119296] 原文转发[1000000] 原文评论[38688]
的微博:去年和亲善大使热巴@Dear-迪丽热巴 的特别回忆转发理由:在羌塘的美好回忆~第一次来到这片独特的荒野,看到野生动物自由生活,还有一群快乐可爱的人在守护着它们。把这些美好留存下来,关注野生动物保护,积极行动,我们每个人都能贡献力量。
赞[554415] 转发[1000000] 评论[1000000] 收藏 06月05日 11:11
赞[554415] 转发[1000000] 评论[1000000] 收藏 06月05日 11:11
要开心。要充实。
#微博live秀# 28岁的直播~@Dear-迪丽热巴 的一直播(下载App->http://t.cn/RDUuslr)
赞[435650] 转发[23584] 评论[1000000] 收藏 06月03日 19:00 来自一直播Yi
赞[435650] 转发[23584] 评论[1000000] 收藏 06月03日 19:00 来自一直播Yi
weibo.cn[06-19 00:47]
diff --git a/tests/testdata/b541fd1751117498b6d6f40d3321686ddf871651237c4ac854a5c3eb.html b/tests/testdata/b541fd1751117498b6d6f40d3321686ddf871651237c4ac854a5c3eb.html
new file mode 100644
index 00000000..30936fb8
--- /dev/null
+++ b/tests/testdata/b541fd1751117498b6d6f40d3321686ddf871651237c4ac854a5c3eb.html
@@ -0,0 +1 @@
+![[X]](https://h5.sinaimg.cn/upload/2016/12/30/125/5366.gif)
专辑:头像相册




照片墙|传统列表
京ICP备12002058号-1 [08-16 00:54]
\ No newline at end of file
diff --git a/tests/testdata/ca5f2a555e8d62f728c66fa90afb2d54d19f8c898e164204a61bdf03.html b/tests/testdata/ca5f2a555e8d62f728c66fa90afb2d54d19f8c898e164204a61bdf03.html
new file mode 100644
index 00000000..ad189dec
--- /dev/null
+++ b/tests/testdata/ca5f2a555e8d62f728c66fa90afb2d54d19f8c898e164204a61bdf03.html
@@ -0,0 +1 @@
+




基本信息
昵称:Dear-迪丽热巴
认证:嘉行传媒签约演员
性别:女
地区:上海
生日:双子座
认证信息:嘉行传媒签约演员
简介:一只喜欢默默表演的小透明。工作联系jaywalk@jaywalk.com.cn 🍒
认证:嘉行传媒签约演员
性别:女
地区:上海
生日:双子座
认证信息:嘉行传媒签约演员
简介:一只喜欢默默表演的小透明。工作联系jaywalk@jaywalk.com.cn 🍒
学习经历
·上海戏剧学院
工作经历
·嘉行传媒
其他信息
weibo.cn[06-19 00:47]
diff --git a/tests/testdata/d486235d4a17dd0accb0f2cc77b3648abfa03580b9e0cdb61f1e618f.html b/tests/testdata/d486235d4a17dd0accb0f2cc77b3648abfa03580b9e0cdb61f1e618f.html
new file mode 100644
index 00000000..1f1b6a9c
--- /dev/null
+++ b/tests/testdata/d486235d4a17dd0accb0f2cc77b3648abfa03580b9e0cdb61f1e618f.html
@@ -0,0 +1 @@
+Dear-迪丽热巴的微博 加关注
微博 相册

#幸福触手可及开播##幸福触手可及# 度量自身,方能修炼精彩人生。追梦不易,披荆斩棘。今晚八点@湖南卫视 和周放,一起守护梦想,书写初夏。

很高兴成为力士大中华区沐浴系列代言人,520就要到啦,大家快来接收告白福利哦!全新植萃泡泡沐浴露让每一位小仙女都能在浓密泡泡浴中拥有夏日嫩白肌,仙气香气都十足!关注@LUX力士 第一时间锁定新品哦!LUX力士的微博视频
赞[741402] 转发[1000000] 评论[1000000] 收藏 05月19日 09:03
赞[741402] 转发[1000000] 评论[1000000] 收藏 05月19日 09:03
转发了 电视剧幸福触手可及 的微博:#幸福触手可及##幸福触手可及定档0519# 从没有一个时刻,幸福如此靠近,只因有你在身边5月19日20:00锁定@湖南卫视 金鹰独播剧场,@优酷 @爱奇艺 @腾讯视频 24点同步更新,等你解锁初夏甜梦!
的微博:#幸福触手可及##幸福触手可及定档0519# 从没有一个时刻,幸福如此靠近,只因有你在身边
转发理由:#幸福触手可及定档0519# 唯有热爱,不负韶华,为之全力以赴,才能成为更优秀的人。5月19日20:00锁定湖南卫视#幸福触手可及# ,愈挫愈勇的独立设计师周放来啦。
赞[480418] 转发[57012] 评论[40966] 收藏 05月15日 20:23
赞[480418] 转发[57012] 评论[40966] 收藏 05月15日 20:23
哈哈哈哈哈哈👅

转发了 北京2022年冬奥会 的微博:【爱豆喊你来助力#北京2022#】
花样滑冰,旋转跳跃 ,“迪丽”前行 @Dear-迪丽热巴 北京2022年冬奥会的微博视频 赞[680201] 原文转发[1450782] 原文评论[50694]
的微博:【爱豆喊你来助力#北京2022#】花样滑冰,旋转跳跃 ,“迪丽”前行 @Dear-迪丽热巴 北京2022年冬奥会的微博视频 赞[680201] 原文转发[1450782] 原文评论[50694]
转发了 央视网 的微博:【想看看战疫一线医护人员们的脸!#极限挑战致敬医护人员#】脱下防疫服,援鄂人员们原来是这个模样。八位医护人员集体分享支援一线的故事,是他们为后方的我们竖起了最坚实的屏障,感谢这群医护天使的负重前行,致敬!@央视网青年 @雷佳音 @岳云鹏 @演员王迅 @贾乃亮 @努力努力再努力x @Dear-迪丽热巴...全文 赞[364004] 原文转发[1056354] 原文评论[3645]
的微博:【想看看战疫一线医护人员们的脸!#极限挑战致敬医护人员#】脱下防疫服,援鄂人员们原来是这个模样。八位医护人员集体分享支援一线的故事,是他们为后方的我们竖起了最坚实的屏障,感谢这群医护天使的负重前行,致敬!@央视网青年 @雷佳音 @岳云鹏 @演员王迅 @贾乃亮 @努力努力再努力x @Dear-迪丽热巴...全文 赞[364004] 原文转发[1056354] 原文评论[3645]#极限挑战# 无奖填词竞答,今晚看👉登峰造_,不可_量,百里_一,南征北_~ Dear-迪丽热巴的微博视频
赞[731516] 转发[1000000] 评论[1000000] 收藏 05月10日 16:50
赞[731516] 转发[1000000] 评论[1000000] 收藏 05月10日 16:50
转发了 中国青年报 的微博:#五四致敬战疫青年# #青春万岁#各地应急响应级别陆续下调,我们正在走向痊愈。回望这些年轻医务人员的脸,不应忘记,正是他们在危难之下,白衣执甲,毅然逆行,为我们筑起血肉长城。感恩提灯天使,致敬最可爱的人!春暖花开,等到疫情完全解除,无论你是从医还是就医,请记住医患之间的休戚与共、唇齿...全文 [组图共12张]
的微博:#五四致敬战疫青年# #青春万岁#各地应急响应级别陆续下调,我们正在走向痊愈。回望这些年轻医务人员的脸,不应忘记,正是他们在危难之下,白衣执甲,毅然逆行,为我们筑起血肉长城。感恩提灯天使,致敬最可爱的人!春暖花开,等到疫情完全解除,无论你是从医还是就医,请记住医患之间的休戚与共、唇齿...全文 [组图共12张]
转发了 东方卫视极限挑战 的微博:鸡条君目睹了vivo#极限挑战#第六季首发阵容@雷佳音 @岳云鹏 @演员王迅 @贾乃亮 @努力努力再努力x @Dear-迪丽热巴 @郭京飞 @邓伦 集结的整个过程,这就是欢迎新人的方式![[疑问]](//h5.sinaimg.cn/m/emoticon/icon/default/d_yiwen-40a816d206.png) 说好要相亲相爱的呢😂东方卫视极限挑战的微博视频 赞[711013] 原文转发[1409505] 原文评论[14761]
说好要相亲相爱的呢😂东方卫视极限挑战的微博视频 赞[711013] 原文转发[1409505] 原文评论[14761]
的微博:鸡条君目睹了vivo#极限挑战#第六季首发阵容@雷佳音 @岳云鹏 @演员王迅 @贾乃亮 @努力努力再努力x @Dear-迪丽热巴 @郭京飞 @邓伦 集结的整个过程,这就是欢迎新人的方式转发理由:#极限挑战#举手之劳,岳岳哥别客气!//@岳云鹏:#极限挑战#谢谢热巴@Dear-迪丽热巴 给我p图,我这里还有好多库存 查看图片
赞[983376] 转发[1000000] 评论[1000000] 收藏 04月30日 12:30
赞[983376] 转发[1000000] 评论[1000000] 收藏 04月30日 12:30
weibo.cn[06-19 00:47]
diff --git a/tests/testdata/e4d541ecb02253c14abc1d52605fc00d91279df9ac4c1465c85b91b3.html b/tests/testdata/e4d541ecb02253c14abc1d52605fc00d91279df9ac4c1465c85b91b3.html
new file mode 100644
index 00000000..161b4305
--- /dev/null
+++ b/tests/testdata/e4d541ecb02253c14abc1d52605fc00d91279df9ac4c1465c85b91b3.html
@@ -0,0 +1 @@
+霜叶的相册
微博 相册


京ICP备12002058号-1 [08-16 23:53]
\ No newline at end of file
diff --git a/tests/testdata/e97222acd5bc7d8d1bfbd3f352f8cad3e36fdd19e40b69e1c33fb3c3.html b/tests/testdata/e97222acd5bc7d8d1bfbd3f352f8cad3e36fdd19e40b69e1c33fb3c3.html
new file mode 100644
index 00000000..9a4e494b
--- /dev/null
+++ b/tests/testdata/e97222acd5bc7d8d1bfbd3f352f8cad3e36fdd19e40b69e1c33fb3c3.html
@@ -0,0 +1 @@
+

{kind=link} + pic_list = self.selector.xpath('//div[@class="c"]//img/@src')
+ for i, pic in enumerate(pic_list):
+ if "?" in pic:
+ pic = pic[:pic.index("?")]
+ pic_list[i] = pic
+ return pic_list
diff --git a/weibo_spider/parser/comment_parser.py b/weibo_spider/parser/comment_parser.py
new file mode 100644
index 00000000..c0117d80
--- /dev/null
+++ b/weibo_spider/parser/comment_parser.py
@@ -0,0 +1,69 @@
+import logging
+import random
+import requests
+import re
+from time import sleep
+from lxml.html import tostring
+from lxml.html import fromstring
+from lxml import etree
+from .parser import Parser
+from .util import handle_garbled, handle_html
+
+logger = logging.getLogger('spider.comment_parser')
+
+
+class CommentParser(Parser):
+ def __init__(self, cookie, weibo_id):
+ self.cookie = cookie
+ self.url = 'https://weibo.cn/comment/' + weibo_id
+ self.selector = handle_html(self.cookie, self.url)
+
+ def get_long_weibo(self):
+ """获取长原创微博"""
+ try:
+ for i in range(5):
+ self.selector = handle_html(self.cookie, self.url)
+ if self.selector is not None:
+ info_div = self.selector.xpath("//div[@class='c' and @id='M_']")[0]
+ info_span = info_div.xpath("//span[@class='ctt']")[0]
+ # 1. 获取 info_span 中的所有 HTML 代码作为字符串
+ html_string = etree.tostring(info_span, encoding='unicode', method='html')
+ # 2. 将
+ pic_list = self.selector.xpath('//div[@class="c"]//img/@src')
+ for i, pic in enumerate(pic_list):
+ if "?" in pic:
+ pic = pic[:pic.index("?")]
+ pic_list[i] = pic
+ return pic_list
diff --git a/weibo_spider/parser/comment_parser.py b/weibo_spider/parser/comment_parser.py
new file mode 100644
index 00000000..c0117d80
--- /dev/null
+++ b/weibo_spider/parser/comment_parser.py
@@ -0,0 +1,69 @@
+import logging
+import random
+import requests
+import re
+from time import sleep
+from lxml.html import tostring
+from lxml.html import fromstring
+from lxml import etree
+from .parser import Parser
+from .util import handle_garbled, handle_html
+
+logger = logging.getLogger('spider.comment_parser')
+
+
+class CommentParser(Parser):
+ def __init__(self, cookie, weibo_id):
+ self.cookie = cookie
+ self.url = 'https://weibo.cn/comment/' + weibo_id
+ self.selector = handle_html(self.cookie, self.url)
+
+ def get_long_weibo(self):
+ """获取长原创微博"""
+ try:
+ for i in range(5):
+ self.selector = handle_html(self.cookie, self.url)
+ if self.selector is not None:
+ info_div = self.selector.xpath("//div[@class='c' and @id='M_']")[0]
+ info_span = info_div.xpath("//span[@class='ctt']")[0]
+ # 1. 获取 info_span 中的所有 HTML 代码作为字符串
+ html_string = etree.tostring(info_span, encoding='unicode', method='html')
+ # 2. 将 替换为 \n + html_string = html_string.replace('
', '\n') + # 3. 去掉所有 HTML 标签,但保留标签内的有效文本 + new_content = fromstring(html_string).text_content() + # 4. 替换多个连续的 \n 为一个 \n + new_content = re.sub(r'\n+\s*', '\n', new_content) + weibo_content = handle_garbled(new_content) + if weibo_content is not None: + return weibo_content + sleep(random.randint(6, 10)) + except Exception: + logger.exception(u'网络出错') + + def get_long_retweet(self): + """获取长转发微博""" + try: + wb_content = self.get_long_weibo() + weibo_content = wb_content[:wb_content.rfind(u'原文转发')] + return weibo_content + except Exception as e: + logger.exception(e) + + def get_video_page_url(self): + """获取微博视频页面的链接""" + video_url = '' + try: + self.selector = handle_html(self.cookie, self.url) + if self.selector is not None: + # 来自微博视频号的格式与普通格式不一致,不加 span 层级 + links = self.selector.xpath("body/div[@class='c' and @id][1]/div//a") + for a in links: + if 'm.weibo.cn/s/video/show?object_id=' in a.xpath( + '@href')[0]: + video_url = a.xpath('@href')[0] + break + except Exception: + logger.exception(u'网络出错') + + return video_url diff --git a/weibo_spider/parser/index_parser.py b/weibo_spider/parser/index_parser.py new file mode 100644 index 00000000..0c5f5e4a --- /dev/null +++ b/weibo_spider/parser/index_parser.py @@ -0,0 +1,56 @@ +import logging + +from .info_parser import InfoParser +from .parser import Parser +from .util import handle_html, string_to_int + +logger = logging.getLogger('spider.index_parser') + + +class IndexParser(Parser): + def __init__(self, cookie, user_uri): + self.cookie = cookie + self.user_uri = user_uri + self.url = 'https://weibo.cn/%s/profile' % (user_uri) + self.selector = handle_html(self.cookie, self.url) + + def _get_user_id(self): + """获取用户id,使用者输入的user_id不一定是正确的,可能是个性域名等,需要获取真正的user_id""" + user_id = self.user_uri + url_list = self.selector.xpath("//div[@class='u']//a") + for url in url_list: + if (url.xpath('string(.)')) == u'资料': + if url.xpath('@href') and url.xpath('@href')[0].endswith( + '/info'): + link = url.xpath('@href')[0] + user_id = link[1:-5] + break + return user_id + + def get_user(self): + """获取用户信息、微博数、关注数、粉丝数""" + try: + user_id = self._get_user_id() + self.user = InfoParser(self.cookie, + user_id).extract_user_info() # 获取用户信息 + self.user.id = user_id + + user_info = self.selector.xpath("//div[@class='tip2']/*/text()") + self.user.weibo_num = string_to_int(user_info[0][3:-1]) + self.user.following = string_to_int(user_info[1][3:-1]) + self.user.followers = string_to_int(user_info[2][3:-1]) + return self.user + except Exception as e: + logger.exception(e) + + def get_page_num(self): + """获取微博总页数""" + try: + if self.selector.xpath("//input[@name='mp']") == []: + page_num = 1 + else: + page_num = (int)(self.selector.xpath("//input[@name='mp']") + [0].attrib['value']) + return page_num + except Exception as e: + logger.exception(e) diff --git a/weibo_spider/parser/info_parser.py b/weibo_spider/parser/info_parser.py new file mode 100644 index 00000000..ad39a2b2 --- /dev/null +++ b/weibo_spider/parser/info_parser.py @@ -0,0 +1,88 @@ +import logging +import sys + +from ..user import User +from .parser import Parser +from .util import handle_html + +logger = logging.getLogger('spider.info_parser') + + +class InfoParser(Parser): + def __init__(self, cookie, user_id): + self.cookie = cookie + self.url = 'https://weibo.cn/%s/info' % (user_id) + self.selector = handle_html(self.cookie, self.url) + + def extract_user_info(self): + """提取用户信息""" + try: + user = User() + nickname = self.selector.xpath('//title/text()')[0] + nickname = nickname[:-3] + if nickname == u'登录 - 新' or nickname == u'新浪': + logger.warning(u'cookie错误或已过期,请按照README中方法重新获取') + sys.exit() + user.nickname = nickname + + zh_list = [u'性别', u'地区', u'生日', u'简介', u'认证', u'达人'] + en_list = [ + 'gender', 'location', 'birthday', 'description', + 'verified_reason', 'talent' + ] + + # 先尝试标准格式(查看他人资料页) + basic_info = self.selector.xpath("//div[@class='c'][3]/text()") + has_info = any( + ':' in str(i) and str(i).split(':', 1)[0] in zh_list + for i in basic_info) + + if not has_info: + # 自己查看自己的资料页:标签在标签内,值在的tail文本中 + basic_info = [] + for c_div in self.selector.xpath("//div[@class='c']"): + a_texts = c_div.xpath('a/text()') + if u'性别' in a_texts or u'昵称' in a_texts: + for a in c_div.xpath('a'): + label = (a.text or '').strip() + tail = (a.tail or '').strip() + if label in zh_list and tail.startswith(':'): + basic_info.append(label + tail) + break + + for i in basic_info: + if ':' in str(i) and str(i).split(':', 1)[0] in zh_list: + setattr(user, en_list[zh_list.index(str(i).split(':', 1)[0])], + str(i).split(':', 1)[1].replace('\u3000', '')) + + # 提取学习经历和工作经历,使用following-sibling定位,兼容自己和他人页面 + tip_divs = self.selector.xpath("//div[@class='tip']") + for tip in tip_divs: + tip_text = tip.xpath('string(.)').strip() + if tip_text == u'学习经历': + edu_div = tip.xpath( + 'following-sibling::div[@class="c"][1]') + if edu_div: + # 优先用text()(他人页面),fallback用string(.)(自己页面) + edu_text = edu_div[0].xpath('text()') + if edu_text and len(edu_text[0].strip()) > 1: + user.education = edu_text[0][1:].replace( + u'\xa0', u' ') + else: + user.education = ' '.join( + edu_div[0].xpath('string(.)').split()) + elif tip_text == u'工作经历': + work_div = tip.xpath( + 'following-sibling::div[@class="c"][1]') + if work_div: + work_text = work_div[0].xpath('text()') + if work_text and len(work_text[0].strip()) > 1: + user.work = work_text[0][1:].replace( + u'\xa0', u' ') + else: + user.work = ' '.join( + work_div[0].xpath('string(.)').split()) + + return user + except Exception as e: + logger.exception(e) diff --git a/weibo_spider/parser/mblog_picAll_parser.py b/weibo_spider/parser/mblog_picAll_parser.py new file mode 100644 index 00000000..1bc66610 --- /dev/null +++ b/weibo_spider/parser/mblog_picAll_parser.py @@ -0,0 +1,12 @@ +from .parser import Parser +from .util import handle_html + + +class MblogPicAllParser(Parser): + def __init__(self, cookie, weibo_id): + self.cookie = cookie + self.url = 'https://weibo.cn/mblog/picAll/' + weibo_id + '?rl=1' + self.selector = handle_html(self.cookie, self.url) + + def extract_preview_picture_list(self): + return self.selector.xpath('//img/@src') diff --git a/weibo_spider/parser/page_parser.py b/weibo_spider/parser/page_parser.py new file mode 100644 index 00000000..6acf1ad9 --- /dev/null +++ b/weibo_spider/parser/page_parser.py @@ -0,0 +1,380 @@ +import logging +import re +import sys +from datetime import datetime, timedelta + +from .. import datetime_util +from ..weibo import Weibo +from .comment_parser import CommentParser +from .mblog_picAll_parser import MblogPicAllParser +from .parser import Parser +from .util import handle_garbled, handle_html, to_video_download_url + +MAX_PINNED_COUNT = 2 + +logger = logging.getLogger('spider.page_parser') + + +class PageParser(Parser): + empty_count = 0 + + def __init__(self, cookie, user_config, page, filter): + self.cookie = cookie + if hasattr(PageParser, + 'user_uri') and self.user_uri != user_config['user_uri']: + PageParser.empty_count = 0 + self.user_uri = user_config['user_uri'] + self.since_date = user_config['since_date'] + self.end_date = user_config['end_date'] + self.page = page + self.url = 'https://weibo.cn/%s/profile?page=%d' % (self.user_uri, page) + if self.end_date != 'now': + since_date = self.since_date.split(' ')[0].split('-') + end_date = self.end_date.split(' ')[0].split('-') + for date in [since_date, end_date]: + for i in [1, 2]: + if len(date[i]) == 1: + date[i] = '0' + date[i] + starttime = ''.join(since_date) + endtime = ''.join(end_date) + self.url = 'https://weibo.cn/%s/profile?starttime=%s&endtime=%s&advancedfilter=1&page=%d' % ( + self.user_uri, starttime, endtime, page) + self.selector = '' + self.to_continue = True + is_exist = '' + for i in range(3): + self.selector = handle_html(self.cookie, self.url) + if self.selector: + info = self.selector.xpath("//div[@class='c']") + if info is None or len(info) == 0: + continue + is_exist = info[0].xpath("div/span[@class='ctt']") + if is_exist: + PageParser.empty_count = 0 + break + if not is_exist: + PageParser.empty_count += 1 + if PageParser.empty_count > 2: + self.to_continue = False + PageParser.empty_count = 0 + self.filter = filter + + def get_one_page(self, weibo_id_list): + """获取第page页的全部微博""" + cur_pinned_count = 0 + try: + info = self.selector.xpath("//div[@class='c']") + is_exist = info[0].xpath("div/span[@class='ctt']") + weibos = [] + if is_exist: + since_date = datetime_util.str_to_time(self.since_date) + for i in range(0, len(info) - 1): + weibo = self.get_one_weibo(info[i]) + if weibo: + if weibo.id in weibo_id_list: + continue + publish_time = datetime_util.str_to_time( + weibo.publish_time) + + if publish_time < since_date: + # As of 2023.05, there can be at most 2 pinned weibo. + # We will continue for at most 2 times before return. + if self.page == 1 and cur_pinned_count < MAX_PINNED_COUNT: + cur_pinned_count += 1 + continue + else: + return weibos, weibo_id_list, False + logger.info(weibo) + logger.info('-' * 100) + weibos.append(weibo) + weibo_id_list.append(weibo.id) + return weibos, weibo_id_list, self.to_continue + except Exception as e: + logger.exception(e) + return [], weibo_id_list, self.to_continue + + def is_original(self, info): + """判断微博是否为原创微博""" + is_original = info.xpath("div/span[@class='cmt']") + if len(is_original) > 3: + return False + else: + return True + + def get_original_weibo(self, info, weibo_id): + """获取原创微博""" + try: + weibo_content = handle_garbled(info) + weibo_content = weibo_content[:weibo_content.rfind(u'赞')] + a_text = info.xpath('div//a/text()') + if u'全文' in a_text: + wb_content = CommentParser(self.cookie, + weibo_id).get_long_weibo() + if wb_content: + weibo_content = wb_content + return weibo_content + except Exception as e: + logger.exception(e) + + def get_retweet(self, info, weibo_id): + """获取转发微博""" + try: + weibo_content = handle_garbled(info) + weibo_content = weibo_content[weibo_content.find(':') + + 1:weibo_content.rfind(u'赞')] + weibo_content = weibo_content[:weibo_content.rfind(u'赞')] + a_text = info.xpath('div//a/text()') + if u'全文' in a_text: + wb_content = CommentParser(self.cookie, + weibo_id).get_long_retweet() + if wb_content: + weibo_content = wb_content + retweet_reason = handle_garbled(info.xpath('div')[-1]) + retweet_reason = retweet_reason[:retweet_reason.rindex(u'赞')] + original_user = info.xpath("div/span[@class='cmt']/a/text()") + if original_user: + original_user = original_user[0] + weibo_content = (retweet_reason + '\n' + u'原始用户: ' + + original_user + '\n' + u'转发内容: ' + + weibo_content) + else: + weibo_content = (retweet_reason + '\n' + u'转发内容: ' + + weibo_content) + return weibo_content + except Exception as e: + logger.exception(e) + + def get_weibo_content(self, info, is_original): + """获取微博内容""" + try: + weibo_id = info.xpath('@id')[0][2:] + if is_original: + weibo_content = self.get_original_weibo(info, weibo_id) + else: + weibo_content = self.get_retweet(info, weibo_id) + return weibo_content + except Exception as e: + logger.exception(e) + + def get_article_url(self, info): + """获取微博头条文章的url""" + article_url = '' + text = handle_garbled(info) + if text.startswith(u'发布了头条文章') or text.startswith(u'我发表了头条文章'): + url = info.xpath('.//a/@href') + if url and url[0].startswith('https://weibo.com/ttarticle'): + article_url = url[0] + return article_url + + def get_publish_place(self, info): + """获取微博发布位置""" + try: + div_first = info.xpath('div')[0] + a_list = div_first.xpath('a') + publish_place = u'无' + for a in a_list: + if ('place.weibo.com' in a.xpath('@href')[0] + and a.xpath('text()')[0] == u'显示地图'): + weibo_a = div_first.xpath("span[@class='ctt']/a") + if len(weibo_a) >= 1: + publish_place = weibo_a[-1] + if (u'视频' == div_first.xpath( + "span[@class='ctt']/a/text()")[-1][-2:]): + if len(weibo_a) >= 2: + publish_place = weibo_a[-2] + else: + publish_place = u'无' + publish_place = handle_garbled(publish_place) + break + return publish_place + except Exception as e: + logger.exception(e) + + def get_publish_time(self, info): + """获取微博发布时间""" + try: + str_time = info.xpath("div/span[@class='ct']") + str_time = handle_garbled(str_time[0]) + publish_time = str_time.split(u'来自')[0] + if u'刚刚' in publish_time: + publish_time = datetime.now().strftime('%Y-%m-%d %H:%M') + elif u'分钟' in publish_time: + minute = publish_time[:publish_time.find(u'分钟')] + minute = timedelta(minutes=int(minute)) + publish_time = (datetime.now() - + minute).strftime('%Y-%m-%d %H:%M') + elif u'今天' in publish_time: + today = datetime.now().strftime('%Y-%m-%d') + time = publish_time[3:] + publish_time = today + ' ' + time + if len(publish_time) > 16: + publish_time = publish_time[:16] + elif u'月' in publish_time: + year = datetime.now().strftime('%Y') + month = publish_time[0:2] + day = publish_time[3:5] + time = publish_time[7:12] + publish_time = year + '-' + month + '-' + day + ' ' + time + else: + publish_time = publish_time[:16] + return publish_time + except Exception as e: + logger.exception(e) + + def get_publish_tool(self, info): + """获取微博发布工具""" + try: + str_time = info.xpath("div/span[@class='ct']") + str_time = handle_garbled(str_time[0]) + if len(str_time.split(u'来自')) > 1: + publish_tool = str_time.split(u'来自')[1] + else: + publish_tool = u'无' + return publish_tool + except Exception as e: + logger.exception(e) + + def get_weibo_footer(self, info): + """获取微博点赞数、转发数、评论数""" + try: + footer = {} + pattern = r'\d+' + str_footer = info.xpath('div')[-1] + str_footer = handle_garbled(str_footer) + str_footer = str_footer[str_footer.rfind(u'赞'):] + weibo_footer = re.findall(pattern, str_footer, re.M) + + up_num = int(weibo_footer[0]) + footer['up_num'] = up_num + + retweet_num = int(weibo_footer[1]) + footer['retweet_num'] = retweet_num + + comment_num = int(weibo_footer[2]) + footer['comment_num'] = comment_num + return footer + except Exception as e: + logger.exception(e) + + def get_picture_urls(self, info, is_original): + """获取微博原始图片url""" + try: + weibo_id = info.xpath('@id')[0][2:] + picture_urls = {} + if is_original: + original_pictures = self.extract_picture_urls(info, weibo_id) + picture_urls['original_pictures'] = original_pictures + if not self.filter: + picture_urls['retweet_pictures'] = u'无' + else: + retweet_url = info.xpath("div/a[@class='cc']/@href")[0] + retweet_id = retweet_url.split('/')[-1].split('?')[0] + retweet_pictures = self.extract_picture_urls(info, retweet_id) + picture_urls['retweet_pictures'] = retweet_pictures + a_list = info.xpath('div[last()]/a/@href') + original_picture = u'无' + for a in a_list: + if a.endswith(('.gif', '.jpeg', '.jpg', '.png')): + original_picture = a + break + picture_urls['original_pictures'] = original_picture + return picture_urls + except Exception as e: + logger.exception(e) + + def get_video_url(self, info): + """获取微博视频url""" + video_url = u'无' + + weibo_id = info.xpath('@id')[0][2:] + try: + video_page_url = '' + a_text = info.xpath('./div[1]//a/text()') + if u'全文' in a_text: + video_page_url = CommentParser(self.cookie, + weibo_id).get_video_page_url() + else: + # 来自微博视频号的格式与普通格式不一致,不加 span 层级 + a_list = info.xpath('./div[1]//a') + for a in a_list: + if 'm.weibo.cn/s/video/show?object_id=' in a.xpath( + '@href')[0]: + video_page_url = a.xpath('@href')[0] + break + + if video_page_url != '': + video_url = to_video_download_url(self.cookie, video_page_url) + except Exception as e: + logger.exception(e) + + return video_url + + def get_one_weibo(self, info): + """获取一条微博的全部信息""" + try: + weibo = Weibo() + is_original = self.is_original(info) + weibo.original = is_original # 是否原创微博 + if (not self.filter) or is_original: + weibo.id = info.xpath('@id')[0][2:] + weibo.content = self.get_weibo_content(info, + is_original) # 微博内容 + weibo.article_url = self.get_article_url(info) # 头条文章url + picture_urls = self.get_picture_urls(info, is_original) + weibo.original_pictures = picture_urls[ + 'original_pictures'] # 原创图片url + if not self.filter: + weibo.retweet_pictures = picture_urls[ + 'retweet_pictures'] # 转发图片url + weibo.video_url = self.get_video_url(info) # 微博视频url + weibo.publish_place = self.get_publish_place(info) # 微博发布位置 + weibo.publish_time = self.get_publish_time(info) # 微博发布时间 + weibo.publish_tool = self.get_publish_tool(info) # 微博发布工具 + footer = self.get_weibo_footer(info) + weibo.up_num = footer['up_num'] # 微博点赞数 + weibo.retweet_num = footer['retweet_num'] # 转发数 + weibo.comment_num = footer['comment_num'] # 评论数 + else: + weibo = None + logger.info(u'正在过滤转发微博') + return weibo + except Exception as e: + logger.exception(e) + + def extract_picture_urls(self, info, weibo_id): + """提取微博原始图片url""" + try: + a_list = info.xpath('div/a/@href') + first_pic = 'https://weibo.cn/mblog/pic/' + weibo_id + all_pic = 'https://weibo.cn/mblog/picAll/' + weibo_id + picture_urls = u'无' + if first_pic in ''.join(a_list): + if all_pic in ''.join(a_list): + preview_picture_list = MblogPicAllParser( + self.cookie, weibo_id).extract_preview_picture_list() + picture_list = [ + p.replace('/thumb180/', '/large/') + for p in preview_picture_list + ] + picture_urls = ','.join(picture_list) + else: + if info.xpath('.//img/@src'): + for link in info.xpath('div/a'): + if len(link.xpath('@href')) > 0: + if first_pic in link.xpath('@href')[0]: + if len(link.xpath('img/@src')) > 0: + preview_picture = link.xpath( + 'img/@src')[0] + picture_urls = preview_picture.replace( + '/wap180/', '/large/') + break + else: + logger.warning( + u'爬虫微博可能被设置成了"不显示图片",请前往' + u'"https://weibo.cn/account/customize/pic",修改为"显示"' + ) + sys.exit() + return picture_urls + except Exception as e: + logger.exception(e) + return u'无' diff --git a/weibo_spider/parser/parser.py b/weibo_spider/parser/parser.py new file mode 100644 index 00000000..41302ba4 --- /dev/null +++ b/weibo_spider/parser/parser.py @@ -0,0 +1,5 @@ +class Parser: + def __init__(self, cookie): + self.cookie = cookie + self.url = '' + self.selector = None diff --git a/weibo_spider/parser/photo_parser.py b/weibo_spider/parser/photo_parser.py new file mode 100644 index 00000000..236e76e2 --- /dev/null +++ b/weibo_spider/parser/photo_parser.py @@ -0,0 +1,19 @@ +from .parser import Parser +from .util import handle_html + + +class PhotoParser(Parser): + def __init__(self, cookie, user_id): + self.cookie = cookie + self.url = "https://weibo.cn/" + str(user_id) + "/photo?tf=6_008" + self.selector = handle_html(self.cookie, self.url) + self.user_id = user_id + + def extract_avatar_album_url(self): + # Finds the href attribute of the table td div element with text 头像相册, e.g. + #
 + result = self.selector.xpath('//img[@alt="头像相册"]/../@href')
+ if len(result) > 0:
+ return "https://weibo.cn" + result[0]
+ else:
+ return "https://weibo.cn/" + str(self.user_id) + "/avatar?rl=0"
diff --git a/weibo_spider/parser/util.py b/weibo_spider/parser/util.py
new file mode 100644
index 00000000..b7c95736
--- /dev/null
+++ b/weibo_spider/parser/util.py
@@ -0,0 +1,150 @@
+import hashlib
+import json
+import logging
+import sys
+
+import requests
+from lxml import etree
+
+# Set GENERATE_TEST_DATA to True when generating test data.
+GENERATE_TEST_DATA = False
+TEST_DATA_DIR = 'tests/testdata'
+URL_MAP_FILE = 'url_map.json'
+logger = logging.getLogger('spider.util')
+
+# 全局代理配置,由 spider.py 初始化
+_proxies = None
+
+
+def set_proxies(proxy_url):
+ """设置全局代理"""
+ global _proxies
+ if proxy_url:
+ _proxies = {'http': proxy_url, 'https': proxy_url}
+ logger.info(u'已启用代理: %s', proxy_url)
+
+
+def get_proxies():
+ return _proxies
+
+
+def hash_url(url):
+ return hashlib.sha224(url.encode('utf8')).hexdigest()
+
+
+DEFAULT_UA = ('Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) '
+ 'AppleWebKit/537.36 (KHTML, like Gecko) '
+ 'Chrome/133.0.0.0 Safari/537.36')
+
+
+def handle_html(cookie, url):
+ """处理html"""
+ from time import sleep
+ headers = {'User-Agent': DEFAULT_UA, 'Cookie': cookie}
+ for attempt in range(5):
+ try:
+ resp = requests.get(url, headers=headers, timeout=10,
+ proxies=_proxies)
+ if resp.status_code == 200 and len(resp.content) > 0:
+ selector = etree.HTML(resp.content)
+ return selector
+ elif resp.status_code == 403:
+ wait = 300 * (attempt + 1)
+ logger.warning(u'403 IP被限制,等待%d秒后重试(第%d次)',
+ wait, attempt + 1)
+ sleep(wait)
+ elif resp.status_code == 432:
+ logger.error(u'432 User-Agent被拒绝,请更新UA')
+ return None
+ else:
+ wait = 60 * (attempt + 1)
+ logger.warning(u'请求返回状态码%d,等待%d秒后重试(第%d次)',
+ resp.status_code, wait, attempt + 1)
+ sleep(wait)
+ except Exception as e:
+ wait = 60 * (attempt + 1)
+ logger.warning(u'请求异常,等待%d秒后重试(第%d次): %s',
+ wait, attempt + 1, str(e))
+ sleep(wait)
+ logger.error(u'请求%s失败,已重试5次', url)
+ return None
+
+
+def handle_garbled(info):
+ """处理乱码"""
+ try:
+ if hasattr(info, 'xpath'): # 检查 info 是否具有 xpath 方法
+ info_str = info.xpath('string(.)') # 提取字符串内容
+ else:
+ info_str = str(info) # 若不支持 xpath,将其转换为字符串
+
+ info = info_str.replace(u'\u200b', '').encode(
+ sys.stdout.encoding, 'ignore').decode(sys.stdout.encoding)
+ return info
+ except Exception as e:
+ logger.exception(e)
+ return u'无'
+
+
+def bid2mid(bid):
+ """convert string bid to string mid"""
+ alphabet = '0123456789abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ'
+ base = len(alphabet)
+ bidlen = len(bid)
+ head = bidlen % 4
+ digit = int((bidlen - head) / 4)
+ dlist = [bid[0:head]]
+ for d in range(1, digit + 1):
+ dlist.append(bid[head:head + d * 4])
+ head += 4
+ mid = ''
+ for d in dlist:
+ num = 0
+ idx = 0
+ strlen = len(d)
+ for char in d:
+ power = (strlen - (idx + 1))
+ num += alphabet.index(char) * (base**power)
+ idx += 1
+ strnum = str(num)
+ while (len(d) == 4 and len(strnum) < 7):
+ strnum = '0' + strnum
+ mid += strnum
+ return mid
+
+
+def to_video_download_url(cookie, video_page_url):
+ if video_page_url == '':
+ return ''
+
+ video_object_url = video_page_url.replace('m.weibo.cn/s/video/show',
+ 'm.weibo.cn/s/video/object')
+ try:
+ headers = {'User-Agent': DEFAULT_UA, 'Cookie': cookie}
+ wb_info = requests.get(video_object_url, headers=headers,
+ proxies=_proxies).json()
+ video_url = wb_info['data']['object']['stream'].get('hd_url')
+ if not video_url:
+ video_url = wb_info['data']['object']['stream']['url']
+ if not video_url: # 说明该视频为直播
+ video_url = ''
+ except json.decoder.JSONDecodeError:
+ logger.warning(u'当前账号没有浏览该视频的权限')
+
+ return video_url
+
+
+def string_to_int(string):
+ """字符串转换为整数"""
+ if len(string) == 0:
+ logger.warning("string to int, the input string is empty!")
+ return 0
+ if isinstance(string, int):
+ return string
+ elif string.endswith(u'万+'):
+ string = string[:-2] + '0000'
+ elif string.endswith(u'万'):
+ string = float(string[:-1]) * 10000
+ elif string.endswith(u'亿'):
+ string = float(string[:-1]) * 100000000
+ return int(string)
diff --git a/weibo_spider/spider.py b/weibo_spider/spider.py
new file mode 100644
index 00000000..09125233
--- /dev/null
+++ b/weibo_spider/spider.py
@@ -0,0 +1,400 @@
+#!/usr/bin/env python
+# -*- coding: UTF-8 -*-
+
+import json
+import logging
+import logging.config
+import os
+import random
+import shutil
+import sys
+from datetime import date, datetime, timedelta
+from time import sleep
+
+from absl import app, flags
+from tqdm import tqdm
+
+from . import config_util, datetime_util
+from .downloader import AvatarPictureDownloader
+from .parser import AlbumParser, IndexParser, PageParser, PhotoParser
+from .user import User
+
+FLAGS = flags.FLAGS
+
+flags.DEFINE_string('config_path', None, 'The path to config.json.')
+flags.DEFINE_string('u', None, 'The user_id we want to input.')
+flags.DEFINE_string('user_id_list', None, 'The path to user_id_list.txt.')
+flags.DEFINE_string('output_dir', None, 'The dir path to store results.')
+
+logging_path = os.path.split(
+ os.path.realpath(__file__))[0] + os.sep + 'logging.conf'
+logging.config.fileConfig(logging_path)
+logger = logging.getLogger('spider')
+
+
+class Spider:
+ def __init__(self, config):
+ """Weibo类初始化"""
+ self.filter = config[
+ 'filter'] # 取值范围为0、1,程序默认值为0,代表要爬取用户的全部微博,1代表只爬取用户的原创微博
+ since_date = config['since_date']
+ if isinstance(since_date, int):
+ since_date = date.today() - timedelta(since_date)
+ self.since_date = str(
+ since_date) # 起始时间,即爬取发布日期从该值到结束时间的微博,形式为yyyy-mm-dd
+ self.end_date = config[
+ 'end_date'] # 结束时间,即爬取发布日期从起始时间到该值的微博,形式为yyyy-mm-dd,特殊值"now"代表现在
+ random_wait_pages = config['random_wait_pages']
+ self.random_wait_pages = [
+ min(random_wait_pages),
+ max(random_wait_pages)
+ ] # 随机等待频率,即每爬多少页暂停一次
+ random_wait_seconds = config['random_wait_seconds']
+ self.random_wait_seconds = [
+ min(random_wait_seconds),
+ max(random_wait_seconds)
+ ] # 随机等待时间,即每次暂停要sleep多少秒
+ self.global_wait = config['global_wait'] # 配置全局等待时间,如每爬1000页等待3600秒等
+ self.page_count = 0 # 统计每次全局等待后,爬取了多少页,若页数满足全局等待要求就进入下一次全局等待
+ self.write_mode = config[
+ 'write_mode'] # 结果信息保存类型,为list形式,可包含txt、csv、json、mongo和mysql五种类型
+ self.pic_download = config[
+ 'pic_download'] # 取值范围为0、1,程序默认值为0,代表不下载微博原始图片,1代表下载
+ self.video_download = config[
+ 'video_download'] # 取值范围为0、1,程序默认为0,代表不下载微博视频,1代表下载
+ self.file_download_timeout = config.get(
+ 'file_download_timeout',
+ [5, 5, 10
+ ]) # 控制文件下载“超时”时的操作,值是list形式,包含三个数字,依次分别是最大超时重试次数、最大连接时间和最大读取时间
+ self.result_dir_name = config.get(
+ 'result_dir_name', 0) # 结果目录名,取值为0或1,决定结果文件存储在用户昵称文件夹里还是用户id文件夹里
+ self.cookie = config['cookie']
+ self.mysql_config = config.get('mysql_config') # MySQL数据库连接配置,可以不填
+
+ self.sqlite_config = config.get('sqlite_config')
+ self.kafka_config = config.get('kafka_config')
+ self.mongo_config = config.get('mongo_config')
+ self.post_config = config.get('post_config')
+ self.user_config_file_path = ''
+ user_id_list = config['user_id_list']
+ if FLAGS.user_id_list:
+ user_id_list = FLAGS.user_id_list
+ if not isinstance(user_id_list, list):
+ if not os.path.isabs(user_id_list):
+ user_id_list = os.getcwd() + os.sep + user_id_list
+ if not os.path.isfile(user_id_list):
+ logger.warning('不存在%s文件', user_id_list)
+ sys.exit()
+ self.user_config_file_path = user_id_list
+ if FLAGS.u:
+ user_id_list = FLAGS.u.split(',')
+ if isinstance(user_id_list, list):
+ # 第一部分是处理dict类型的
+ # 第二部分是其他类型,其他类型提供去重功能
+ user_config_list = list(
+ map(
+ lambda x: {
+ 'user_uri': x['id'],
+ 'since_date': x.get('since_date', self.since_date),
+ 'end_date': x.get('end_date', self.end_date),
+ }, [
+ user_id for user_id in user_id_list
+ if isinstance(user_id, dict)
+ ])) + list(
+ map(
+ lambda x: {
+ 'user_uri': x,
+ 'since_date': self.since_date,
+ 'end_date': self.end_date
+ },
+ set([
+ user_id for user_id in user_id_list
+ if not isinstance(user_id, dict)
+ ])))
+ if FLAGS.u:
+ config_util.add_user_uri_list(self.user_config_file_path,
+ user_id_list)
+ else:
+ user_config_list = config_util.get_user_config_list(
+ user_id_list, self.since_date)
+ for user_config in user_config_list:
+ user_config['end_date'] = self.end_date
+ self.user_config_list = user_config_list # 要爬取的微博用户的user_config列表
+ self.user_config = {} # 用户配置,包含用户id和since_date
+ self.new_since_date = '' # 完成某用户爬取后,自动生成对应用户新的since_date
+ self.user = User() # 存储爬取到的用户信息
+ self.got_num = 0 # 存储爬取到的微博数
+ self.weibo_id_list = [] # 存储爬取到的所有微博id
+
+ def write_weibo(self, weibos):
+ """将爬取到的信息写入文件或数据库"""
+ for writer in self.writers:
+ writer.write_weibo(weibos)
+ for downloader in self.downloaders:
+ downloader.download_files(weibos)
+
+ def write_user(self, user):
+ """将用户信息写入数据库"""
+ for writer in self.writers:
+ writer.write_user(user)
+
+ def get_user_info(self, user_uri):
+ """获取用户信息"""
+ self.user = IndexParser(self.cookie, user_uri).get_user()
+ self.page_count += 1
+
+ def download_user_avatar(self, user_uri):
+ """下载用户头像"""
+ avatar_album_url = PhotoParser(self.cookie,
+ user_uri).extract_avatar_album_url()
+ pic_urls = AlbumParser(self.cookie,
+ avatar_album_url).extract_pic_urls()
+ AvatarPictureDownloader(
+ self._get_filepath('img'),
+ self.file_download_timeout).handle_download(pic_urls)
+
+ def get_weibo_info(self):
+ """获取微博信息"""
+ try:
+ since_date = datetime_util.str_to_time(
+ self.user_config['since_date'])
+ now = datetime.now()
+ if since_date <= now:
+ page_num = IndexParser(
+ self.cookie,
+ self.user_config['user_uri']).get_page_num() # 获取微博总页数
+ self.page_count += 1
+ if self.page_count > 2 and (self.page_count +
+ page_num) > self.global_wait[0][0]:
+ wait_seconds = int(
+ self.global_wait[0][1] *
+ min(1, self.page_count / self.global_wait[0][0]))
+ logger.info(u'即将进入全局等待时间,%d秒后程序继续执行' % wait_seconds)
+ for i in tqdm(range(wait_seconds)):
+ sleep(1)
+ self.page_count = 0
+ self.global_wait.append(self.global_wait.pop(0))
+ page1 = 0
+ random_pages = random.randint(*self.random_wait_pages)
+ for page in tqdm(range(1, page_num + 1), desc='Progress'):
+ weibos, self.weibo_id_list, to_continue = PageParser(
+ self.cookie,
+ self.user_config, page, self.filter).get_one_page(
+ self.weibo_id_list) # 获取第page页的全部微博
+ logger.info(
+ u'%s已获取%s(%s)的第%d页微博%s',
+ '-' * 30,
+ self.user.nickname,
+ self.user.id,
+ page,
+ '-' * 30,
+ )
+ self.page_count += 1
+ if weibos:
+ yield weibos
+ if not to_continue:
+ break
+
+ # 通过加入随机等待避免被限制。爬虫速度过快容易被系统限制(一段时间后限
+ # 制会自动解除),加入随机等待模拟人的操作,可降低被系统限制的风险。默
+ # 认是每爬取1到5页随机等待6到10秒,如果仍然被限,可适当增加sleep时间
+ if (page - page1) % random_pages == 0 and page < page_num:
+ sleep(random.randint(*self.random_wait_seconds))
+ page1 = page
+ random_pages = random.randint(*self.random_wait_pages)
+
+ if self.page_count >= self.global_wait[0][0]:
+ logger.info(u'即将进入全局等待时间,%d秒后程序继续执行' %
+ self.global_wait[0][1])
+ for i in tqdm(range(self.global_wait[0][1])):
+ sleep(1)
+ self.page_count = 0
+ self.global_wait.append(self.global_wait.pop(0))
+
+ # 更新用户user_id_list.txt中的since_date
+ if self.user_config_file_path or FLAGS.u:
+ config_util.update_user_config_file(
+ self.user_config_file_path,
+ self.user_config['user_uri'],
+ self.user.nickname,
+ self.new_since_date,
+ )
+ except Exception as e:
+ logger.exception(e)
+
+ def _get_filepath(self, type):
+ """获取结果文件路径"""
+ try:
+ dir_name = self.user.nickname
+ if self.result_dir_name:
+ dir_name = self.user.id
+ if FLAGS.output_dir is not None:
+ file_dir = FLAGS.output_dir + os.sep + dir_name
+ else:
+ file_dir = (os.getcwd() + os.sep + 'weibo' + os.sep + dir_name)
+ if type == 'img' or type == 'video':
+ file_dir = file_dir + os.sep + type
+ if not os.path.isdir(file_dir):
+ os.makedirs(file_dir)
+ if type == 'img' or type == 'video':
+ return file_dir
+ file_path = file_dir + os.sep + self.user.id + '.' + type
+ return file_path
+ except Exception as e:
+ logger.exception(e)
+
+ def initialize_info(self, user_config):
+ """初始化爬虫信息"""
+ self.got_num = 0
+ self.user_config = user_config
+ self.weibo_id_list = []
+ if self.end_date == 'now':
+ self.new_since_date = datetime.now().strftime('%Y-%m-%d %H:%M')
+ else:
+ self.new_since_date = self.end_date
+ self.writers = []
+ if 'csv' in self.write_mode:
+ from .writer import CsvWriter
+
+ self.writers.append(
+ CsvWriter(self._get_filepath('csv'), self.filter))
+ if 'txt' in self.write_mode:
+ from .writer import TxtWriter
+
+ self.writers.append(
+ TxtWriter(self._get_filepath('txt'), self.filter))
+ if 'json' in self.write_mode:
+ from .writer import JsonWriter
+
+ self.writers.append(JsonWriter(self._get_filepath('json')))
+ if 'mysql' in self.write_mode:
+ from .writer import MySqlWriter
+
+ self.writers.append(MySqlWriter(self.mysql_config))
+ if 'mongo' in self.write_mode:
+ from .writer import MongoWriter
+
+ self.writers.append(MongoWriter(self.mongo_config))
+ if 'sqlite' in self.write_mode:
+ from .writer import SqliteWriter
+
+ self.writers.append(SqliteWriter(self.sqlite_config))
+
+ if 'kafka' in self.write_mode:
+ from .writer import KafkaWriter
+
+ self.writers.append(KafkaWriter(self.kafka_config))
+
+ if 'post' in self.write_mode:
+ from .writer import PostWriter
+
+ self.writers.append(PostWriter(self.post_config))
+
+ self.downloaders = []
+ if self.pic_download == 1:
+ from .downloader import (OriginPictureDownloader,
+ RetweetPictureDownloader)
+
+ self.downloaders.append(
+ OriginPictureDownloader(self._get_filepath('img'),
+ self.file_download_timeout))
+ if self.pic_download and not self.filter:
+ self.downloaders.append(
+ RetweetPictureDownloader(self._get_filepath('img'),
+ self.file_download_timeout))
+ if self.video_download == 1:
+ from .downloader import VideoDownloader
+
+ self.downloaders.append(
+ VideoDownloader(self._get_filepath('video'),
+ self.file_download_timeout))
+
+ def get_one_user(self, user_config):
+ """获取一个用户的微博"""
+ try:
+ self.get_user_info(user_config['user_uri'])
+ logger.info(self.user)
+ logger.info('*' * 100)
+
+ self.initialize_info(user_config)
+ self.write_user(self.user)
+ logger.info('*' * 100)
+
+ # 下载用户头像相册中的图片。
+ if self.pic_download:
+ self.download_user_avatar(user_config['user_uri'])
+
+ for weibos in self.get_weibo_info():
+ self.write_weibo(weibos)
+ self.got_num += len(weibos)
+ if not self.filter:
+ logger.info(u'共爬取' + str(self.got_num) + u'条微博')
+ else:
+ logger.info(u'共爬取' + str(self.got_num) + u'条原创微博')
+ logger.info(u'信息抓取完毕')
+ logger.info('*' * 100)
+ except Exception as e:
+ logger.exception(e)
+
+ def start(self):
+ """运行爬虫"""
+ try:
+ if not self.user_config_list:
+ logger.info(
+ u'没有配置有效的user_id,请通过config.json或user_id_list.txt配置user_id')
+ return
+ user_count = 0
+ user_count1 = random.randint(*self.random_wait_pages)
+ random_users = random.randint(*self.random_wait_pages)
+ for user_config in self.user_config_list:
+ if (user_count - user_count1) % random_users == 0:
+ sleep(random.randint(*self.random_wait_seconds))
+ user_count1 = user_count
+ random_users = random.randint(*self.random_wait_pages)
+ user_count += 1
+ self.get_one_user(user_config)
+ except Exception as e:
+ logger.exception(e)
+
+
+def _get_config():
+ """获取config.json数据"""
+ src = os.path.split(
+ os.path.realpath(__file__))[0] + os.sep + 'config_sample.json'
+ config_path = os.getcwd() + os.sep + 'config.json'
+ if FLAGS.config_path:
+ config_path = FLAGS.config_path
+ elif not os.path.isfile(config_path):
+ shutil.copy(src, config_path)
+ logger.info(u'请先配置当前目录(%s)下的config.json文件,'
+ u'如果想了解config.json参数的具体意义及配置方法,请访问\n'
+ u'https://github.com/dataabc/weiboSpider#2程序设置' %
+ os.getcwd())
+ sys.exit()
+ try:
+ with open(config_path) as f:
+ config = json.loads(f.read())
+ return config
+ except ValueError:
+ logger.error(u'config.json 格式不正确,请访问 '
+ u'https://github.com/dataabc/weiboSpider#2程序设置')
+ sys.exit()
+
+
+def main(_):
+ try:
+ config = _get_config()
+ config_util.validate_config(config)
+ # 初始化代理
+ proxy = config.get('proxy')
+ if proxy:
+ from .parser.util import set_proxies
+ set_proxies(proxy)
+ wb = Spider(config)
+ wb.start() # 爬取微博信息
+ except Exception as e:
+ logger.exception(e)
+
+
+if __name__ == '__main__':
+ app.run(main)
diff --git a/weibo_spider/user.py b/weibo_spider/user.py
new file mode 100644
index 00000000..dc135799
--- /dev/null
+++ b/weibo_spider/user.py
@@ -0,0 +1,29 @@
+class User:
+ def __init__(self):
+ self.id = ''
+
+ self.nickname = ''
+
+ self.gender = ''
+ self.location = ''
+ self.birthday = ''
+ self.description = ''
+ self.verified_reason = ''
+ self.talent = ''
+
+ self.education = ''
+ self.work = ''
+
+ self.weibo_num = 0
+ self.following = 0
+ self.followers = 0
+
+ def __str__(self):
+ """打印微博用户信息"""
+ result = ''
+ result += u'用户昵称: %s\n' % self.nickname
+ result += u'用户id: %s\n' % self.id
+ result += u'微博数: %d\n' % self.weibo_num
+ result += u'关注数: %d\n' % self.following
+ result += u'粉丝数: %d\n' % self.followers
+ return result
diff --git a/weibo_spider/user_id_list.txt b/weibo_spider/user_id_list.txt
new file mode 100644
index 00000000..ead74227
--- /dev/null
+++ b/weibo_spider/user_id_list.txt
@@ -0,0 +1,3 @@
+1669879400 Dear-迪丽热巴 2020-01-13 19:18
+1223178222 胡歌 2020-01-13 19:28
+1729370543 郭碧婷 2020-01-13 19:33
\ No newline at end of file
diff --git a/weibo_spider/weibo.py b/weibo_spider/weibo.py
new file mode 100644
index 00000000..54cec7ff
--- /dev/null
+++ b/weibo_spider/weibo.py
@@ -0,0 +1,32 @@
+class Weibo:
+ def __init__(self):
+ self.id = ''
+ self.user_id = ''
+
+ self.content = ''
+ self.article_url = ''
+
+ self.original_pictures = []
+ self.retweet_pictures = None
+ self.original = None
+ self.video_url = ''
+
+ self.publish_place = ''
+ self.publish_time = ''
+ self.publish_tool = ''
+
+ self.up_num = 0
+ self.retweet_num = 0
+ self.comment_num = 0
+
+ def __str__(self):
+ """打印一条微博"""
+ result = self.content + '\n'
+ result += u'微博发布位置:%s\n' % self.publish_place
+ result += u'发布时间:%s\n' % self.publish_time
+ result += u'发布工具:%s\n' % self.publish_tool
+ result += u'点赞数:%d\n' % self.up_num
+ result += u'转发数:%d\n' % self.retweet_num
+ result += u'评论数:%d\n' % self.comment_num
+ result += u'url:https://weibo.cn/comment/%s\n' % self.id
+ return result
diff --git a/weibo_spider/writer/__init__.py b/weibo_spider/writer/__init__.py
new file mode 100644
index 00000000..f6b24bd6
--- /dev/null
+++ b/weibo_spider/writer/__init__.py
@@ -0,0 +1,10 @@
+from .csv_writer import CsvWriter
+from .json_writer import JsonWriter
+from .mongo_writer import MongoWriter
+from .mysql_writer import MySqlWriter
+from .txt_writer import TxtWriter
+from .sqlite_writer import SqliteWriter
+from .kafka_writer import KafkaWriter
+from .post_writer import PostWriter
+
+__all__ = [CsvWriter, TxtWriter, JsonWriter, MongoWriter, MySqlWriter, SqliteWriter, KafkaWriter, PostWriter]
diff --git a/weibo_spider/writer/csv_writer.py b/weibo_spider/writer/csv_writer.py
new file mode 100644
index 00000000..193803da
--- /dev/null
+++ b/weibo_spider/writer/csv_writer.py
@@ -0,0 +1,46 @@
+import csv
+import logging
+
+from .writer import Writer
+
+logger = logging.getLogger('spider.csv_writer')
+
+
+class CsvWriter(Writer):
+ def __init__(self, file_path, filter):
+ self.file_path = file_path
+
+ self.result_headers = [('微博id', 'id'), ('微博正文', 'content'),
+ ('头条文章url', 'article_url'),
+ ('原始图片url', 'original_pictures'),
+ ('微博视频url', 'video_url'),
+ ('发布位置', 'publish_place'),
+ ('发布时间', 'publish_time'),
+ ('发布工具', 'publish_tool'), ('点赞数', 'up_num'),
+ ('转发数', 'retweet_num'), ('评论数', 'comment_num')]
+ if not filter:
+ self.result_headers.insert(4, ('被转发微博原始图片url', 'retweet_pictures'))
+ self.result_headers.insert(5, ('是否为原创微博', 'original'))
+ try:
+ with open(self.file_path, 'a', encoding='utf-8-sig',
+ newline='') as f:
+ writer = csv.writer(f)
+ writer.writerows([[kv[0] for kv in self.result_headers]])
+ except Exception as e:
+ logger.exception(e)
+
+ def write_user(self, user):
+ self.user = user
+
+ def write_weibo(self, weibos):
+ """将爬取的信息写入csv文件"""
+ try:
+ result_data = [[w.__dict__[kv[1]] for kv in self.result_headers]
+ for w in weibos]
+ with open(self.file_path, 'a', encoding='utf-8-sig',
+ newline='') as f:
+ writer = csv.writer(f)
+ writer.writerows(result_data)
+ logger.info(u'%d条微博写入csv文件完毕,保存路径:%s', len(weibos), self.file_path)
+ except Exception as e:
+ logger.exception(e)
diff --git a/weibo_spider/writer/json_writer.py b/weibo_spider/writer/json_writer.py
new file mode 100644
index 00000000..bca61c2d
--- /dev/null
+++ b/weibo_spider/writer/json_writer.py
@@ -0,0 +1,52 @@
+import codecs
+import json
+import logging
+import os
+
+from .writer import Writer
+
+logger = logging.getLogger('spider.json_writer')
+
+
+class JsonWriter(Writer):
+ def __init__(self, file_path):
+ self.file_path = file_path
+
+ def write_user(self, user):
+ self.user = user
+
+ def _update_json_data(self, data, weibo_info):
+ """更新要写入json结果文件中的数据,已经存在于json中的信息更新为最新值,不存在的信息添加到data中"""
+ data['user'] = self.user.__dict__
+ if data.get('weibo'):
+ is_new = 1 # 待写入微博是否全部为新微博,即待写入微博与json中的数据不重复
+ for old in data['weibo']:
+ if weibo_info[-1]['id'] == old['id']:
+ is_new = 0
+ break
+ if is_new == 0:
+ for new in weibo_info:
+ flag = 1
+ for i, old in enumerate(data['weibo']):
+ if new['id'] == old['id']:
+ data['weibo'][i] = new
+ flag = 0
+ break
+ if flag:
+ data['weibo'].append(new)
+ else:
+ data['weibo'] += weibo_info
+ else:
+ data['weibo'] = weibo_info
+ return data
+
+ def write_weibo(self, weibos):
+ """将爬到的信息写入json文件"""
+ data = {}
+ if os.path.isfile(self.file_path):
+ with codecs.open(self.file_path, 'r', encoding='utf-8') as f:
+ data = json.load(f)
+ data = self._update_json_data(data, [w.__dict__ for w in weibos])
+ with codecs.open(self.file_path, 'w', encoding='utf-8') as f:
+ f.write(json.dumps(data, indent=4, ensure_ascii=False))
+ logger.info(u'%d条微博写入json文件完毕,保存路径:%s', len(weibos), self.file_path)
diff --git a/weibo_spider/writer/kafka_writer.py b/weibo_spider/writer/kafka_writer.py
new file mode 100644
index 00000000..247fd3a2
--- /dev/null
+++ b/weibo_spider/writer/kafka_writer.py
@@ -0,0 +1,41 @@
+import json
+import logging
+import sys
+
+from .writer import Writer
+
+logger = logging.getLogger('spider.kafka_writer')
+
+
+class KafkaWriter(Writer):
+ def __init__(self, kafka_config):
+ try:
+ from kafka import KafkaProducer
+ except ImportError:
+ logger.warning(
+ u'系统中可能没有安装kafka库,请先运行 pip install kafka-python ,再运行程序')
+ sys.exit()
+
+ self.kafka_config = kafka_config
+ self.producer = KafkaProducer(
+ bootstrap_servers=str(kafka_config['bootstrap-server']).split(','),
+ value_serializer=lambda m: json.dumps(m, ensure_ascii=False
+ ).encode('UTF-8'))
+ self.weibo_topics = list(kafka_config['weibo_topics'])
+ self.user_topics = list(kafka_config['user_topics'])
+ logger.info('{}', kafka_config)
+
+ def write_weibo(self, weibo):
+ for w in weibo:
+ w.user_id = self.user.id
+ for topic in self.weibo_topics:
+ self.producer.send(topic, value=w.__dict__)
+
+ def write_user(self, user):
+ self.user = user
+
+ for topic in self.user_topics:
+ self.producer.send(topic, value=user.__dict__)
+
+ def __del__(self):
+ self.producer.close()
diff --git a/weibo_spider/writer/mongo_writer.py b/weibo_spider/writer/mongo_writer.py
new file mode 100644
index 00000000..c6c08c5b
--- /dev/null
+++ b/weibo_spider/writer/mongo_writer.py
@@ -0,0 +1,62 @@
+import copy
+import logging
+import sys
+
+from .writer import Writer
+
+logger = logging.getLogger('spider.mongo_writer')
+
+
+class MongoWriter(Writer):
+ def __init__(self, mongo_config):
+ self.mongo_config = mongo_config
+ self.connection_string = mongo_config['connection_string']
+ self.dba_name = mongo_config.get('dba_name', None)
+ self.dba_password = mongo_config.get('dba_password', None)
+
+ def _info_to_mongodb(self, collection, info_list):
+ """将爬取的信息写入MongoDB数据库"""
+ try:
+ import pymongo
+ except ImportError:
+ logger.warning(
+ u'系统中可能没有安装pymongo库,请先运行 pip install pymongo ,再运行程序')
+ sys.exit()
+ try:
+ from pymongo import MongoClient
+
+ client = MongoClient(self.connection_string)
+ if self.dba_name or self.dba_password:
+ # authenticate() 在PyMongo3.6版本就已弃用,这一段可能需要后续跟进
+ client.admin.authenticate(
+ self.dba_name, self.dba_password, mechanism='SCRAM-SHA-1'
+ )
+
+ db = client['weibo']
+ collection = db[collection]
+ new_info_list = copy.deepcopy(info_list)
+ for info in new_info_list:
+ if not collection.find_one({'id': info['id']}):
+ collection.insert_one(info)
+ else:
+ collection.update_one({'id': info['id']}, {'$set': info})
+ except pymongo.errors.ServerSelectionTimeoutError:
+ logger.warning(
+ u'系统中可能没有安装或启动MongoDB数据库,请先根据系统环境安装或启动MongoDB,再运行程序')
+ sys.exit()
+
+ def write_weibo(self, weibos):
+ """将爬取的微博信息写入MongoDB数据库"""
+ weibo_list = []
+ for w in weibos:
+ w.user_id = self.user.id
+ weibo_list.append(w.__dict__)
+ self._info_to_mongodb('weibo', weibo_list)
+ logger.info(u'%d条微博写入MongoDB数据库完毕', len(weibos))
+
+ def write_user(self, user):
+ """将爬取的用户信息写入MongoDB数据库"""
+ self.user = user
+ user_list = [user.__dict__]
+ self._info_to_mongodb('user', user_list)
+ logger.info(u'%s信息写入MongoDB数据库完毕', user.nickname)
diff --git a/weibo_spider/writer/mysql_writer.py b/weibo_spider/writer/mysql_writer.py
new file mode 100644
index 00000000..7118c083
--- /dev/null
+++ b/weibo_spider/writer/mysql_writer.py
@@ -0,0 +1,142 @@
+import copy
+import logging
+import sys
+
+from .writer import Writer
+
+logger = logging.getLogger('spider.mysql_writer')
+
+
+class MySqlWriter(Writer):
+ def __init__(self, mysql_config):
+ self.mysql_config = mysql_config
+
+ # 创建'weibo'数据库
+ create_database = """CREATE DATABASE IF NOT EXISTS weibo DEFAULT
+ CHARACTER SET utf8mb4 COLLATE utf8mb4_unicode_ci"""
+ self._mysql_create_database(create_database)
+ self.mysql_config['db'] = 'weibo'
+
+ def _mysql_create(self, connection, sql):
+ """创建MySQL数据库或表"""
+ try:
+ with connection.cursor() as cursor:
+ cursor.execute(sql)
+ finally:
+ connection.close()
+
+ def _mysql_create_database(self, sql):
+ """创建MySQL数据库"""
+ try:
+ import pymysql
+ except ImportError:
+ logger.warning(
+ u'系统中可能没有安装pymysql库,请先运行 pip install pymysql ,再运行程序')
+ sys.exit()
+ try:
+ connection = pymysql.connect(**self.mysql_config)
+ self._mysql_create(connection, sql)
+ except pymysql.OperationalError:
+ logger.warning(u'系统中可能没有安装或正确配置MySQL数据库,请先根据系统环境安装或配置MySQL,再运行程序')
+ sys.exit()
+
+ def _mysql_create_table(self, sql):
+ """创建MySQL表"""
+ import pymysql
+ connection = pymysql.connect(**self.mysql_config)
+ self._mysql_create(connection, sql)
+
+ def _mysql_insert(self, table, data_list):
+ """向MySQL表插入或更新数据"""
+ import pymysql
+ if len(data_list) > 0:
+ # We use this to filter out unset values.
+ data_list = [{k: v
+ for k, v in data.items() if v is not None}
+ for data in data_list]
+
+ keys = ', '.join(data_list[0].keys())
+ values = ', '.join(['%s'] * len(data_list[0]))
+ connection = pymysql.connect(**self.mysql_config)
+ cursor = connection.cursor()
+ sql = """INSERT INTO {table}({keys}) VALUES ({values}) ON
+ DUPLICATE KEY UPDATE""".format(table=table,
+ keys=keys,
+ values=values)
+ update = ','.join([
+ ' {key} = values({key})'.format(key=key)
+ for key in data_list[0]
+ ])
+ sql += update
+ try:
+ cursor.executemany(
+ sql, [tuple(data.values()) for data in data_list])
+ connection.commit()
+ except Exception as e:
+ connection.rollback()
+ logger.exception(e)
+ finally:
+ connection.close()
+
+ def write_weibo(self, weibos):
+ """将爬取的微博信息写入MySQL数据库"""
+ # 创建'weibo'表
+ try:
+ create_table = """
+ CREATE TABLE IF NOT EXISTS weibo (
+ id varchar(10) NOT NULL,
+ user_id varchar(12),
+ content varchar(5000),
+ article_url varchar(200),
+ original_pictures varchar(3000),
+ retweet_pictures varchar(3000),
+ original BOOLEAN NOT NULL DEFAULT 1,
+ video_url varchar(300),
+ publish_place varchar(100),
+ publish_time DATETIME NOT NULL,
+ publish_tool varchar(30),
+ up_num INT NOT NULL,
+ retweet_num INT NOT NULL,
+ comment_num INT NOT NULL,
+ PRIMARY KEY (id)
+ ) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4"""
+ self._mysql_create_table(create_table)
+ # 在'weibo'表中插入或更新微博数据
+ weibo_list = []
+ info_list = copy.deepcopy(weibos)
+ for weibo in info_list:
+ weibo.user_id = self.user.id
+ weibo_list.append(weibo.__dict__)
+ self._mysql_insert('weibo', weibo_list)
+ logger.info(u'%d条微博写入MySQL数据库完毕', len(weibos))
+ except Exception as e:
+ logger.exception(e)
+
+ def write_user(self, user):
+ """将爬取的用户信息写入MySQL数据库"""
+ try:
+ self.user = user
+
+ # 创建'user'表
+ create_table = """
+ CREATE TABLE IF NOT EXISTS user (
+ id varchar(20) NOT NULL,
+ nickname varchar(30),
+ gender varchar(10),
+ location varchar(200),
+ birthday varchar(40),
+ description varchar(400),
+ verified_reason varchar(140),
+ talent varchar(200),
+ education varchar(200),
+ work varchar(200),
+ weibo_num INT,
+ following INT,
+ followers INT,
+ PRIMARY KEY (id)
+ ) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4"""
+ self._mysql_create_table(create_table)
+ self._mysql_insert('user', [user.__dict__])
+ logger.info(u'%s信息写入MySQL数据库完毕', user.nickname)
+ except Exception as e:
+ logger.exception(e)
diff --git a/weibo_spider/writer/post_writer.py b/weibo_spider/writer/post_writer.py
new file mode 100644
index 00000000..af536623
--- /dev/null
+++ b/weibo_spider/writer/post_writer.py
@@ -0,0 +1,59 @@
+import codecs
+import json
+import logging
+import os
+import requests
+
+from .writer import Writer
+from time import sleep
+from requests.exceptions import RequestException
+
+logger = logging.getLogger('spider.post_writer')
+
+class PostWriter(Writer):
+ def __init__(self, post_config):
+ self.post_config = post_config
+ self.api_url = post_config['api_url']
+ self.api_token = post_config.get('api_token', None)
+ self.dba_password = post_config.get('dba_password', None)
+
+ def write_user(self, user):
+ self.user = user
+
+ def _update_json_data(self, data, weibo_info):
+ """将获取到的微博数据转换为json输出模式一致"""
+ data['user'] = self.user.__dict__
+ if data.get('weibo'):
+ data['weibo'] += weibo_info
+ else:
+ data['weibo'] = weibo_info
+ return data
+
+ def send_post_request_with_token(self, url, data, token, max_retries, backoff_factor):
+ headers = {
+ 'Content-Type': 'application/json',
+ 'api-token': f'{token}',
+ }
+ for attempt in range(max_retries + 1):
+ try:
+ response = requests.post(url, json=data, headers=headers)
+ if response.status_code == requests.codes.ok:
+ return response.json()
+ else:
+ raise RequestException(f"Unexpected response status: {response.status_code}")
+ except RequestException as e:
+ if attempt < max_retries:
+ sleep(backoff_factor * (attempt + 1)) # 逐步增加等待时间,避免频繁重试
+ continue
+ else:
+ logger.error(f"在尝试{max_retries}次发出POST连接后,请求失败:{e}")
+
+ def write_weibo(self, weibos):
+ """将爬到的信息POST到API"""
+ data = {}
+ data = self._update_json_data(data, [w.__dict__ for w in weibos])
+ if data:
+ self.send_post_request_with_token(self.api_url, data, self.api_token, 3, 2)
+ logger.info(u'%d条微博通过POST发送到 %s', len(weibos), self.api_url)
+ else:
+ logger.info(u'没有获取到微博,略过API POST')
diff --git a/weibo_spider/writer/sqlite_writer.py b/weibo_spider/writer/sqlite_writer.py
new file mode 100644
index 00000000..cea0ccd9
--- /dev/null
+++ b/weibo_spider/writer/sqlite_writer.py
@@ -0,0 +1,108 @@
+import copy
+import logging
+import sys
+
+from .writer import Writer
+
+logger = logging.getLogger('spider.sqlite_writer')
+
+
+class SqliteWriter(Writer):
+ def __init__(self, sqlite_config):
+ self.sqlite_config = sqlite_config
+
+ def _sqlite_create(self, connection, sql):
+ """创建sqlite数据库或表"""
+ try:
+ cursor = connection.cursor()
+ cursor.execute(sql)
+ finally:
+ connection.close()
+
+ def _sqlite_create_table(self, sql):
+ """创建sqlite表"""
+ import sqlite3
+ connection = sqlite3.connect(self.sqlite_config)
+ self._sqlite_create(connection, sql)
+
+ def _sqlite_insert(self, table, data_list):
+ """向sqlite表插入或更新数据"""
+ import sqlite3
+ if len(data_list) > 0:
+ # We use this to filter out unset values.
+ data_list = [{k: v
+ for k, v in data.items() if v is not None}
+ for data in data_list]
+
+ keys = ', '.join(data_list[0].keys())
+ values = ', '.join(['?'] * len(data_list[0]))
+ connection = sqlite3.connect(self.sqlite_config)
+ cursor = connection.cursor()
+ sql = """INSERT OR REPLACE INTO {table}({keys}) VALUES ({values})""".format(
+ table=table, keys=keys, values=values)
+ try:
+ cursor.executemany(
+ sql, [tuple(data.values()) for data in data_list])
+ connection.commit()
+ except Exception as e:
+ connection.rollback()
+ logger.exception(e)
+ finally:
+ connection.close()
+
+ def write_weibo(self, weibos):
+ """将爬取的微博信息写入sqlite数据库"""
+ # 创建'weibo'表
+ create_table = """
+ CREATE TABLE IF NOT EXISTS weibo (
+ id varchar(10) NOT NULL,
+ user_id varchar(12),
+ content varchar(2000),
+ article_url varchar(200),
+ original_pictures varchar(3000),
+ retweet_pictures varchar(3000),
+ original BOOLEAN NOT NULL DEFAULT 1,
+ video_url varchar(300),
+ publish_place varchar(100),
+ publish_time DATETIME NOT NULL,
+ publish_tool varchar(30),
+ up_num INT NOT NULL,
+ retweet_num INT NOT NULL,
+ comment_num INT NOT NULL,
+ PRIMARY KEY (id)
+ )"""
+ self._sqlite_create_table(create_table)
+ # 在'weibo'表中插入或更新微博数据
+ weibo_list = []
+ info_list = copy.deepcopy(weibos)
+ for weibo in info_list:
+ weibo.user_id = self.user.id
+ weibo_list.append(weibo.__dict__)
+ self._sqlite_insert('weibo', weibo_list)
+ logger.info(u'%d条微博写入sqlite数据库完毕', len(weibos))
+
+ def write_user(self, user):
+ """将爬取的用户信息写入sqlite数据库"""
+ self.user = user
+
+ # 创建'user'表
+ create_table = """
+ CREATE TABLE IF NOT EXISTS user (
+ id varchar(20) NOT NULL,
+ nickname varchar(30),
+ gender varchar(10),
+ location varchar(200),
+ birthday varchar(40),
+ description varchar(400),
+ verified_reason varchar(140),
+ talent varchar(200),
+ education varchar(200),
+ work varchar(200),
+ weibo_num INT,
+ following INT,
+ followers INT,
+ PRIMARY KEY (id)
+ )"""
+ self._sqlite_create_table(create_table)
+ self._sqlite_insert('user', [user.__dict__])
+ logger.info(u'%s信息写入sqlite数据库完毕', user.nickname)
diff --git a/weibo_spider/writer/txt_writer.py b/weibo_spider/writer/txt_writer.py
new file mode 100644
index 00000000..6eddd862
--- /dev/null
+++ b/weibo_spider/writer/txt_writer.py
@@ -0,0 +1,57 @@
+import logging
+import sys
+
+from .writer import Writer
+
+logger = logging.getLogger('spider.txt_writer')
+
+
+class TxtWriter(Writer):
+ def __init__(self, file_path, filter):
+ self.file_path = file_path
+
+ self.user_header = u'用户信息'
+ self.user_desc = [('nickname', '用户昵称'), ('id', '用户id'),
+ ('weibo_num', '微博数'), ('following', '关注数'),
+ ('followers', '粉丝数')]
+
+ if filter:
+ self.weibo_header = u'原创微博内容'
+ else:
+ self.weibo_header = u'微博内容'
+ self.weibo_desc = [('publish_place', '微博位置'), ('publish_time', '发布时间'),
+ ('up_num', '点赞数'), ('retweet_num', '转发数'),
+ ('comment_num', '评论数'), ('publish_tool', '发布工具')]
+
+ def write_user(self, user):
+ self.user = user
+ user_info = '\n'.join(
+ [v + ':' + str(self.user.__dict__[k]) for k, v in self.user_desc])
+
+ with open(self.file_path, 'ab') as f:
+ f.write((self.user_header + ':\n' + user_info + '\n\n').encode(
+ sys.stdout.encoding))
+ logger.info(u'%s信息写入txt文件完毕,保存路径:%s', self.user.nickname,
+ self.file_path)
+
+ def write_weibo(self, weibo):
+ """将爬取的信息写入txt文件"""
+
+ weibo_header = ''
+ if self.weibo_header:
+ weibo_header = self.weibo_header + ':\n'
+ self.weibo_header = ''
+
+ try:
+ temp_result = []
+ for w in weibo:
+ temp_result.append(w.__dict__['content'] + '\n' + '\n'.join(
+ [v + ':' + str(w.__dict__[k])
+ for k, v in self.weibo_desc]))
+ result = '\n\n'.join(temp_result) + '\n\n'
+
+ with open(self.file_path, 'ab') as f:
+ f.write((weibo_header + result).encode(sys.stdout.encoding))
+ logger.info(u'%d条微博写入txt文件完毕,保存路径:%s', len(weibo), self.file_path)
+ except Exception as e:
+ logger.exception(e)
diff --git a/weibo_spider/writer/writer.py b/weibo_spider/writer/writer.py
new file mode 100644
index 00000000..45366510
--- /dev/null
+++ b/weibo_spider/writer/writer.py
@@ -0,0 +1,17 @@
+from abc import ABC, abstractmethod
+
+
+class Writer(ABC):
+ def __init__(self):
+ """根据需要,初始化结果路径、初始化表头、初始化数据库等"""
+ pass
+
+ @abstractmethod
+ def write_weibo(self, weibo):
+ """给定微博信息,写入对应文本或数据库"""
+ pass
+
+ @abstractmethod
+ def write_user(self, user):
+ """给定用户信息,写入对应文本或数据库"""
+ pass
+ result = self.selector.xpath('//img[@alt="头像相册"]/../@href')
+ if len(result) > 0:
+ return "https://weibo.cn" + result[0]
+ else:
+ return "https://weibo.cn/" + str(self.user_id) + "/avatar?rl=0"
diff --git a/weibo_spider/parser/util.py b/weibo_spider/parser/util.py
new file mode 100644
index 00000000..b7c95736
--- /dev/null
+++ b/weibo_spider/parser/util.py
@@ -0,0 +1,150 @@
+import hashlib
+import json
+import logging
+import sys
+
+import requests
+from lxml import etree
+
+# Set GENERATE_TEST_DATA to True when generating test data.
+GENERATE_TEST_DATA = False
+TEST_DATA_DIR = 'tests/testdata'
+URL_MAP_FILE = 'url_map.json'
+logger = logging.getLogger('spider.util')
+
+# 全局代理配置,由 spider.py 初始化
+_proxies = None
+
+
+def set_proxies(proxy_url):
+ """设置全局代理"""
+ global _proxies
+ if proxy_url:
+ _proxies = {'http': proxy_url, 'https': proxy_url}
+ logger.info(u'已启用代理: %s', proxy_url)
+
+
+def get_proxies():
+ return _proxies
+
+
+def hash_url(url):
+ return hashlib.sha224(url.encode('utf8')).hexdigest()
+
+
+DEFAULT_UA = ('Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) '
+ 'AppleWebKit/537.36 (KHTML, like Gecko) '
+ 'Chrome/133.0.0.0 Safari/537.36')
+
+
+def handle_html(cookie, url):
+ """处理html"""
+ from time import sleep
+ headers = {'User-Agent': DEFAULT_UA, 'Cookie': cookie}
+ for attempt in range(5):
+ try:
+ resp = requests.get(url, headers=headers, timeout=10,
+ proxies=_proxies)
+ if resp.status_code == 200 and len(resp.content) > 0:
+ selector = etree.HTML(resp.content)
+ return selector
+ elif resp.status_code == 403:
+ wait = 300 * (attempt + 1)
+ logger.warning(u'403 IP被限制,等待%d秒后重试(第%d次)',
+ wait, attempt + 1)
+ sleep(wait)
+ elif resp.status_code == 432:
+ logger.error(u'432 User-Agent被拒绝,请更新UA')
+ return None
+ else:
+ wait = 60 * (attempt + 1)
+ logger.warning(u'请求返回状态码%d,等待%d秒后重试(第%d次)',
+ resp.status_code, wait, attempt + 1)
+ sleep(wait)
+ except Exception as e:
+ wait = 60 * (attempt + 1)
+ logger.warning(u'请求异常,等待%d秒后重试(第%d次): %s',
+ wait, attempt + 1, str(e))
+ sleep(wait)
+ logger.error(u'请求%s失败,已重试5次', url)
+ return None
+
+
+def handle_garbled(info):
+ """处理乱码"""
+ try:
+ if hasattr(info, 'xpath'): # 检查 info 是否具有 xpath 方法
+ info_str = info.xpath('string(.)') # 提取字符串内容
+ else:
+ info_str = str(info) # 若不支持 xpath,将其转换为字符串
+
+ info = info_str.replace(u'\u200b', '').encode(
+ sys.stdout.encoding, 'ignore').decode(sys.stdout.encoding)
+ return info
+ except Exception as e:
+ logger.exception(e)
+ return u'无'
+
+
+def bid2mid(bid):
+ """convert string bid to string mid"""
+ alphabet = '0123456789abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ'
+ base = len(alphabet)
+ bidlen = len(bid)
+ head = bidlen % 4
+ digit = int((bidlen - head) / 4)
+ dlist = [bid[0:head]]
+ for d in range(1, digit + 1):
+ dlist.append(bid[head:head + d * 4])
+ head += 4
+ mid = ''
+ for d in dlist:
+ num = 0
+ idx = 0
+ strlen = len(d)
+ for char in d:
+ power = (strlen - (idx + 1))
+ num += alphabet.index(char) * (base**power)
+ idx += 1
+ strnum = str(num)
+ while (len(d) == 4 and len(strnum) < 7):
+ strnum = '0' + strnum
+ mid += strnum
+ return mid
+
+
+def to_video_download_url(cookie, video_page_url):
+ if video_page_url == '':
+ return ''
+
+ video_object_url = video_page_url.replace('m.weibo.cn/s/video/show',
+ 'm.weibo.cn/s/video/object')
+ try:
+ headers = {'User-Agent': DEFAULT_UA, 'Cookie': cookie}
+ wb_info = requests.get(video_object_url, headers=headers,
+ proxies=_proxies).json()
+ video_url = wb_info['data']['object']['stream'].get('hd_url')
+ if not video_url:
+ video_url = wb_info['data']['object']['stream']['url']
+ if not video_url: # 说明该视频为直播
+ video_url = ''
+ except json.decoder.JSONDecodeError:
+ logger.warning(u'当前账号没有浏览该视频的权限')
+
+ return video_url
+
+
+def string_to_int(string):
+ """字符串转换为整数"""
+ if len(string) == 0:
+ logger.warning("string to int, the input string is empty!")
+ return 0
+ if isinstance(string, int):
+ return string
+ elif string.endswith(u'万+'):
+ string = string[:-2] + '0000'
+ elif string.endswith(u'万'):
+ string = float(string[:-1]) * 10000
+ elif string.endswith(u'亿'):
+ string = float(string[:-1]) * 100000000
+ return int(string)
diff --git a/weibo_spider/spider.py b/weibo_spider/spider.py
new file mode 100644
index 00000000..09125233
--- /dev/null
+++ b/weibo_spider/spider.py
@@ -0,0 +1,400 @@
+#!/usr/bin/env python
+# -*- coding: UTF-8 -*-
+
+import json
+import logging
+import logging.config
+import os
+import random
+import shutil
+import sys
+from datetime import date, datetime, timedelta
+from time import sleep
+
+from absl import app, flags
+from tqdm import tqdm
+
+from . import config_util, datetime_util
+from .downloader import AvatarPictureDownloader
+from .parser import AlbumParser, IndexParser, PageParser, PhotoParser
+from .user import User
+
+FLAGS = flags.FLAGS
+
+flags.DEFINE_string('config_path', None, 'The path to config.json.')
+flags.DEFINE_string('u', None, 'The user_id we want to input.')
+flags.DEFINE_string('user_id_list', None, 'The path to user_id_list.txt.')
+flags.DEFINE_string('output_dir', None, 'The dir path to store results.')
+
+logging_path = os.path.split(
+ os.path.realpath(__file__))[0] + os.sep + 'logging.conf'
+logging.config.fileConfig(logging_path)
+logger = logging.getLogger('spider')
+
+
+class Spider:
+ def __init__(self, config):
+ """Weibo类初始化"""
+ self.filter = config[
+ 'filter'] # 取值范围为0、1,程序默认值为0,代表要爬取用户的全部微博,1代表只爬取用户的原创微博
+ since_date = config['since_date']
+ if isinstance(since_date, int):
+ since_date = date.today() - timedelta(since_date)
+ self.since_date = str(
+ since_date) # 起始时间,即爬取发布日期从该值到结束时间的微博,形式为yyyy-mm-dd
+ self.end_date = config[
+ 'end_date'] # 结束时间,即爬取发布日期从起始时间到该值的微博,形式为yyyy-mm-dd,特殊值"now"代表现在
+ random_wait_pages = config['random_wait_pages']
+ self.random_wait_pages = [
+ min(random_wait_pages),
+ max(random_wait_pages)
+ ] # 随机等待频率,即每爬多少页暂停一次
+ random_wait_seconds = config['random_wait_seconds']
+ self.random_wait_seconds = [
+ min(random_wait_seconds),
+ max(random_wait_seconds)
+ ] # 随机等待时间,即每次暂停要sleep多少秒
+ self.global_wait = config['global_wait'] # 配置全局等待时间,如每爬1000页等待3600秒等
+ self.page_count = 0 # 统计每次全局等待后,爬取了多少页,若页数满足全局等待要求就进入下一次全局等待
+ self.write_mode = config[
+ 'write_mode'] # 结果信息保存类型,为list形式,可包含txt、csv、json、mongo和mysql五种类型
+ self.pic_download = config[
+ 'pic_download'] # 取值范围为0、1,程序默认值为0,代表不下载微博原始图片,1代表下载
+ self.video_download = config[
+ 'video_download'] # 取值范围为0、1,程序默认为0,代表不下载微博视频,1代表下载
+ self.file_download_timeout = config.get(
+ 'file_download_timeout',
+ [5, 5, 10
+ ]) # 控制文件下载“超时”时的操作,值是list形式,包含三个数字,依次分别是最大超时重试次数、最大连接时间和最大读取时间
+ self.result_dir_name = config.get(
+ 'result_dir_name', 0) # 结果目录名,取值为0或1,决定结果文件存储在用户昵称文件夹里还是用户id文件夹里
+ self.cookie = config['cookie']
+ self.mysql_config = config.get('mysql_config') # MySQL数据库连接配置,可以不填
+
+ self.sqlite_config = config.get('sqlite_config')
+ self.kafka_config = config.get('kafka_config')
+ self.mongo_config = config.get('mongo_config')
+ self.post_config = config.get('post_config')
+ self.user_config_file_path = ''
+ user_id_list = config['user_id_list']
+ if FLAGS.user_id_list:
+ user_id_list = FLAGS.user_id_list
+ if not isinstance(user_id_list, list):
+ if not os.path.isabs(user_id_list):
+ user_id_list = os.getcwd() + os.sep + user_id_list
+ if not os.path.isfile(user_id_list):
+ logger.warning('不存在%s文件', user_id_list)
+ sys.exit()
+ self.user_config_file_path = user_id_list
+ if FLAGS.u:
+ user_id_list = FLAGS.u.split(',')
+ if isinstance(user_id_list, list):
+ # 第一部分是处理dict类型的
+ # 第二部分是其他类型,其他类型提供去重功能
+ user_config_list = list(
+ map(
+ lambda x: {
+ 'user_uri': x['id'],
+ 'since_date': x.get('since_date', self.since_date),
+ 'end_date': x.get('end_date', self.end_date),
+ }, [
+ user_id for user_id in user_id_list
+ if isinstance(user_id, dict)
+ ])) + list(
+ map(
+ lambda x: {
+ 'user_uri': x,
+ 'since_date': self.since_date,
+ 'end_date': self.end_date
+ },
+ set([
+ user_id for user_id in user_id_list
+ if not isinstance(user_id, dict)
+ ])))
+ if FLAGS.u:
+ config_util.add_user_uri_list(self.user_config_file_path,
+ user_id_list)
+ else:
+ user_config_list = config_util.get_user_config_list(
+ user_id_list, self.since_date)
+ for user_config in user_config_list:
+ user_config['end_date'] = self.end_date
+ self.user_config_list = user_config_list # 要爬取的微博用户的user_config列表
+ self.user_config = {} # 用户配置,包含用户id和since_date
+ self.new_since_date = '' # 完成某用户爬取后,自动生成对应用户新的since_date
+ self.user = User() # 存储爬取到的用户信息
+ self.got_num = 0 # 存储爬取到的微博数
+ self.weibo_id_list = [] # 存储爬取到的所有微博id
+
+ def write_weibo(self, weibos):
+ """将爬取到的信息写入文件或数据库"""
+ for writer in self.writers:
+ writer.write_weibo(weibos)
+ for downloader in self.downloaders:
+ downloader.download_files(weibos)
+
+ def write_user(self, user):
+ """将用户信息写入数据库"""
+ for writer in self.writers:
+ writer.write_user(user)
+
+ def get_user_info(self, user_uri):
+ """获取用户信息"""
+ self.user = IndexParser(self.cookie, user_uri).get_user()
+ self.page_count += 1
+
+ def download_user_avatar(self, user_uri):
+ """下载用户头像"""
+ avatar_album_url = PhotoParser(self.cookie,
+ user_uri).extract_avatar_album_url()
+ pic_urls = AlbumParser(self.cookie,
+ avatar_album_url).extract_pic_urls()
+ AvatarPictureDownloader(
+ self._get_filepath('img'),
+ self.file_download_timeout).handle_download(pic_urls)
+
+ def get_weibo_info(self):
+ """获取微博信息"""
+ try:
+ since_date = datetime_util.str_to_time(
+ self.user_config['since_date'])
+ now = datetime.now()
+ if since_date <= now:
+ page_num = IndexParser(
+ self.cookie,
+ self.user_config['user_uri']).get_page_num() # 获取微博总页数
+ self.page_count += 1
+ if self.page_count > 2 and (self.page_count +
+ page_num) > self.global_wait[0][0]:
+ wait_seconds = int(
+ self.global_wait[0][1] *
+ min(1, self.page_count / self.global_wait[0][0]))
+ logger.info(u'即将进入全局等待时间,%d秒后程序继续执行' % wait_seconds)
+ for i in tqdm(range(wait_seconds)):
+ sleep(1)
+ self.page_count = 0
+ self.global_wait.append(self.global_wait.pop(0))
+ page1 = 0
+ random_pages = random.randint(*self.random_wait_pages)
+ for page in tqdm(range(1, page_num + 1), desc='Progress'):
+ weibos, self.weibo_id_list, to_continue = PageParser(
+ self.cookie,
+ self.user_config, page, self.filter).get_one_page(
+ self.weibo_id_list) # 获取第page页的全部微博
+ logger.info(
+ u'%s已获取%s(%s)的第%d页微博%s',
+ '-' * 30,
+ self.user.nickname,
+ self.user.id,
+ page,
+ '-' * 30,
+ )
+ self.page_count += 1
+ if weibos:
+ yield weibos
+ if not to_continue:
+ break
+
+ # 通过加入随机等待避免被限制。爬虫速度过快容易被系统限制(一段时间后限
+ # 制会自动解除),加入随机等待模拟人的操作,可降低被系统限制的风险。默
+ # 认是每爬取1到5页随机等待6到10秒,如果仍然被限,可适当增加sleep时间
+ if (page - page1) % random_pages == 0 and page < page_num:
+ sleep(random.randint(*self.random_wait_seconds))
+ page1 = page
+ random_pages = random.randint(*self.random_wait_pages)
+
+ if self.page_count >= self.global_wait[0][0]:
+ logger.info(u'即将进入全局等待时间,%d秒后程序继续执行' %
+ self.global_wait[0][1])
+ for i in tqdm(range(self.global_wait[0][1])):
+ sleep(1)
+ self.page_count = 0
+ self.global_wait.append(self.global_wait.pop(0))
+
+ # 更新用户user_id_list.txt中的since_date
+ if self.user_config_file_path or FLAGS.u:
+ config_util.update_user_config_file(
+ self.user_config_file_path,
+ self.user_config['user_uri'],
+ self.user.nickname,
+ self.new_since_date,
+ )
+ except Exception as e:
+ logger.exception(e)
+
+ def _get_filepath(self, type):
+ """获取结果文件路径"""
+ try:
+ dir_name = self.user.nickname
+ if self.result_dir_name:
+ dir_name = self.user.id
+ if FLAGS.output_dir is not None:
+ file_dir = FLAGS.output_dir + os.sep + dir_name
+ else:
+ file_dir = (os.getcwd() + os.sep + 'weibo' + os.sep + dir_name)
+ if type == 'img' or type == 'video':
+ file_dir = file_dir + os.sep + type
+ if not os.path.isdir(file_dir):
+ os.makedirs(file_dir)
+ if type == 'img' or type == 'video':
+ return file_dir
+ file_path = file_dir + os.sep + self.user.id + '.' + type
+ return file_path
+ except Exception as e:
+ logger.exception(e)
+
+ def initialize_info(self, user_config):
+ """初始化爬虫信息"""
+ self.got_num = 0
+ self.user_config = user_config
+ self.weibo_id_list = []
+ if self.end_date == 'now':
+ self.new_since_date = datetime.now().strftime('%Y-%m-%d %H:%M')
+ else:
+ self.new_since_date = self.end_date
+ self.writers = []
+ if 'csv' in self.write_mode:
+ from .writer import CsvWriter
+
+ self.writers.append(
+ CsvWriter(self._get_filepath('csv'), self.filter))
+ if 'txt' in self.write_mode:
+ from .writer import TxtWriter
+
+ self.writers.append(
+ TxtWriter(self._get_filepath('txt'), self.filter))
+ if 'json' in self.write_mode:
+ from .writer import JsonWriter
+
+ self.writers.append(JsonWriter(self._get_filepath('json')))
+ if 'mysql' in self.write_mode:
+ from .writer import MySqlWriter
+
+ self.writers.append(MySqlWriter(self.mysql_config))
+ if 'mongo' in self.write_mode:
+ from .writer import MongoWriter
+
+ self.writers.append(MongoWriter(self.mongo_config))
+ if 'sqlite' in self.write_mode:
+ from .writer import SqliteWriter
+
+ self.writers.append(SqliteWriter(self.sqlite_config))
+
+ if 'kafka' in self.write_mode:
+ from .writer import KafkaWriter
+
+ self.writers.append(KafkaWriter(self.kafka_config))
+
+ if 'post' in self.write_mode:
+ from .writer import PostWriter
+
+ self.writers.append(PostWriter(self.post_config))
+
+ self.downloaders = []
+ if self.pic_download == 1:
+ from .downloader import (OriginPictureDownloader,
+ RetweetPictureDownloader)
+
+ self.downloaders.append(
+ OriginPictureDownloader(self._get_filepath('img'),
+ self.file_download_timeout))
+ if self.pic_download and not self.filter:
+ self.downloaders.append(
+ RetweetPictureDownloader(self._get_filepath('img'),
+ self.file_download_timeout))
+ if self.video_download == 1:
+ from .downloader import VideoDownloader
+
+ self.downloaders.append(
+ VideoDownloader(self._get_filepath('video'),
+ self.file_download_timeout))
+
+ def get_one_user(self, user_config):
+ """获取一个用户的微博"""
+ try:
+ self.get_user_info(user_config['user_uri'])
+ logger.info(self.user)
+ logger.info('*' * 100)
+
+ self.initialize_info(user_config)
+ self.write_user(self.user)
+ logger.info('*' * 100)
+
+ # 下载用户头像相册中的图片。
+ if self.pic_download:
+ self.download_user_avatar(user_config['user_uri'])
+
+ for weibos in self.get_weibo_info():
+ self.write_weibo(weibos)
+ self.got_num += len(weibos)
+ if not self.filter:
+ logger.info(u'共爬取' + str(self.got_num) + u'条微博')
+ else:
+ logger.info(u'共爬取' + str(self.got_num) + u'条原创微博')
+ logger.info(u'信息抓取完毕')
+ logger.info('*' * 100)
+ except Exception as e:
+ logger.exception(e)
+
+ def start(self):
+ """运行爬虫"""
+ try:
+ if not self.user_config_list:
+ logger.info(
+ u'没有配置有效的user_id,请通过config.json或user_id_list.txt配置user_id')
+ return
+ user_count = 0
+ user_count1 = random.randint(*self.random_wait_pages)
+ random_users = random.randint(*self.random_wait_pages)
+ for user_config in self.user_config_list:
+ if (user_count - user_count1) % random_users == 0:
+ sleep(random.randint(*self.random_wait_seconds))
+ user_count1 = user_count
+ random_users = random.randint(*self.random_wait_pages)
+ user_count += 1
+ self.get_one_user(user_config)
+ except Exception as e:
+ logger.exception(e)
+
+
+def _get_config():
+ """获取config.json数据"""
+ src = os.path.split(
+ os.path.realpath(__file__))[0] + os.sep + 'config_sample.json'
+ config_path = os.getcwd() + os.sep + 'config.json'
+ if FLAGS.config_path:
+ config_path = FLAGS.config_path
+ elif not os.path.isfile(config_path):
+ shutil.copy(src, config_path)
+ logger.info(u'请先配置当前目录(%s)下的config.json文件,'
+ u'如果想了解config.json参数的具体意义及配置方法,请访问\n'
+ u'https://github.com/dataabc/weiboSpider#2程序设置' %
+ os.getcwd())
+ sys.exit()
+ try:
+ with open(config_path) as f:
+ config = json.loads(f.read())
+ return config
+ except ValueError:
+ logger.error(u'config.json 格式不正确,请访问 '
+ u'https://github.com/dataabc/weiboSpider#2程序设置')
+ sys.exit()
+
+
+def main(_):
+ try:
+ config = _get_config()
+ config_util.validate_config(config)
+ # 初始化代理
+ proxy = config.get('proxy')
+ if proxy:
+ from .parser.util import set_proxies
+ set_proxies(proxy)
+ wb = Spider(config)
+ wb.start() # 爬取微博信息
+ except Exception as e:
+ logger.exception(e)
+
+
+if __name__ == '__main__':
+ app.run(main)
diff --git a/weibo_spider/user.py b/weibo_spider/user.py
new file mode 100644
index 00000000..dc135799
--- /dev/null
+++ b/weibo_spider/user.py
@@ -0,0 +1,29 @@
+class User:
+ def __init__(self):
+ self.id = ''
+
+ self.nickname = ''
+
+ self.gender = ''
+ self.location = ''
+ self.birthday = ''
+ self.description = ''
+ self.verified_reason = ''
+ self.talent = ''
+
+ self.education = ''
+ self.work = ''
+
+ self.weibo_num = 0
+ self.following = 0
+ self.followers = 0
+
+ def __str__(self):
+ """打印微博用户信息"""
+ result = ''
+ result += u'用户昵称: %s\n' % self.nickname
+ result += u'用户id: %s\n' % self.id
+ result += u'微博数: %d\n' % self.weibo_num
+ result += u'关注数: %d\n' % self.following
+ result += u'粉丝数: %d\n' % self.followers
+ return result
diff --git a/weibo_spider/user_id_list.txt b/weibo_spider/user_id_list.txt
new file mode 100644
index 00000000..ead74227
--- /dev/null
+++ b/weibo_spider/user_id_list.txt
@@ -0,0 +1,3 @@
+1669879400 Dear-迪丽热巴 2020-01-13 19:18
+1223178222 胡歌 2020-01-13 19:28
+1729370543 郭碧婷 2020-01-13 19:33
\ No newline at end of file
diff --git a/weibo_spider/weibo.py b/weibo_spider/weibo.py
new file mode 100644
index 00000000..54cec7ff
--- /dev/null
+++ b/weibo_spider/weibo.py
@@ -0,0 +1,32 @@
+class Weibo:
+ def __init__(self):
+ self.id = ''
+ self.user_id = ''
+
+ self.content = ''
+ self.article_url = ''
+
+ self.original_pictures = []
+ self.retweet_pictures = None
+ self.original = None
+ self.video_url = ''
+
+ self.publish_place = ''
+ self.publish_time = ''
+ self.publish_tool = ''
+
+ self.up_num = 0
+ self.retweet_num = 0
+ self.comment_num = 0
+
+ def __str__(self):
+ """打印一条微博"""
+ result = self.content + '\n'
+ result += u'微博发布位置:%s\n' % self.publish_place
+ result += u'发布时间:%s\n' % self.publish_time
+ result += u'发布工具:%s\n' % self.publish_tool
+ result += u'点赞数:%d\n' % self.up_num
+ result += u'转发数:%d\n' % self.retweet_num
+ result += u'评论数:%d\n' % self.comment_num
+ result += u'url:https://weibo.cn/comment/%s\n' % self.id
+ return result
diff --git a/weibo_spider/writer/__init__.py b/weibo_spider/writer/__init__.py
new file mode 100644
index 00000000..f6b24bd6
--- /dev/null
+++ b/weibo_spider/writer/__init__.py
@@ -0,0 +1,10 @@
+from .csv_writer import CsvWriter
+from .json_writer import JsonWriter
+from .mongo_writer import MongoWriter
+from .mysql_writer import MySqlWriter
+from .txt_writer import TxtWriter
+from .sqlite_writer import SqliteWriter
+from .kafka_writer import KafkaWriter
+from .post_writer import PostWriter
+
+__all__ = [CsvWriter, TxtWriter, JsonWriter, MongoWriter, MySqlWriter, SqliteWriter, KafkaWriter, PostWriter]
diff --git a/weibo_spider/writer/csv_writer.py b/weibo_spider/writer/csv_writer.py
new file mode 100644
index 00000000..193803da
--- /dev/null
+++ b/weibo_spider/writer/csv_writer.py
@@ -0,0 +1,46 @@
+import csv
+import logging
+
+from .writer import Writer
+
+logger = logging.getLogger('spider.csv_writer')
+
+
+class CsvWriter(Writer):
+ def __init__(self, file_path, filter):
+ self.file_path = file_path
+
+ self.result_headers = [('微博id', 'id'), ('微博正文', 'content'),
+ ('头条文章url', 'article_url'),
+ ('原始图片url', 'original_pictures'),
+ ('微博视频url', 'video_url'),
+ ('发布位置', 'publish_place'),
+ ('发布时间', 'publish_time'),
+ ('发布工具', 'publish_tool'), ('点赞数', 'up_num'),
+ ('转发数', 'retweet_num'), ('评论数', 'comment_num')]
+ if not filter:
+ self.result_headers.insert(4, ('被转发微博原始图片url', 'retweet_pictures'))
+ self.result_headers.insert(5, ('是否为原创微博', 'original'))
+ try:
+ with open(self.file_path, 'a', encoding='utf-8-sig',
+ newline='') as f:
+ writer = csv.writer(f)
+ writer.writerows([[kv[0] for kv in self.result_headers]])
+ except Exception as e:
+ logger.exception(e)
+
+ def write_user(self, user):
+ self.user = user
+
+ def write_weibo(self, weibos):
+ """将爬取的信息写入csv文件"""
+ try:
+ result_data = [[w.__dict__[kv[1]] for kv in self.result_headers]
+ for w in weibos]
+ with open(self.file_path, 'a', encoding='utf-8-sig',
+ newline='') as f:
+ writer = csv.writer(f)
+ writer.writerows(result_data)
+ logger.info(u'%d条微博写入csv文件完毕,保存路径:%s', len(weibos), self.file_path)
+ except Exception as e:
+ logger.exception(e)
diff --git a/weibo_spider/writer/json_writer.py b/weibo_spider/writer/json_writer.py
new file mode 100644
index 00000000..bca61c2d
--- /dev/null
+++ b/weibo_spider/writer/json_writer.py
@@ -0,0 +1,52 @@
+import codecs
+import json
+import logging
+import os
+
+from .writer import Writer
+
+logger = logging.getLogger('spider.json_writer')
+
+
+class JsonWriter(Writer):
+ def __init__(self, file_path):
+ self.file_path = file_path
+
+ def write_user(self, user):
+ self.user = user
+
+ def _update_json_data(self, data, weibo_info):
+ """更新要写入json结果文件中的数据,已经存在于json中的信息更新为最新值,不存在的信息添加到data中"""
+ data['user'] = self.user.__dict__
+ if data.get('weibo'):
+ is_new = 1 # 待写入微博是否全部为新微博,即待写入微博与json中的数据不重复
+ for old in data['weibo']:
+ if weibo_info[-1]['id'] == old['id']:
+ is_new = 0
+ break
+ if is_new == 0:
+ for new in weibo_info:
+ flag = 1
+ for i, old in enumerate(data['weibo']):
+ if new['id'] == old['id']:
+ data['weibo'][i] = new
+ flag = 0
+ break
+ if flag:
+ data['weibo'].append(new)
+ else:
+ data['weibo'] += weibo_info
+ else:
+ data['weibo'] = weibo_info
+ return data
+
+ def write_weibo(self, weibos):
+ """将爬到的信息写入json文件"""
+ data = {}
+ if os.path.isfile(self.file_path):
+ with codecs.open(self.file_path, 'r', encoding='utf-8') as f:
+ data = json.load(f)
+ data = self._update_json_data(data, [w.__dict__ for w in weibos])
+ with codecs.open(self.file_path, 'w', encoding='utf-8') as f:
+ f.write(json.dumps(data, indent=4, ensure_ascii=False))
+ logger.info(u'%d条微博写入json文件完毕,保存路径:%s', len(weibos), self.file_path)
diff --git a/weibo_spider/writer/kafka_writer.py b/weibo_spider/writer/kafka_writer.py
new file mode 100644
index 00000000..247fd3a2
--- /dev/null
+++ b/weibo_spider/writer/kafka_writer.py
@@ -0,0 +1,41 @@
+import json
+import logging
+import sys
+
+from .writer import Writer
+
+logger = logging.getLogger('spider.kafka_writer')
+
+
+class KafkaWriter(Writer):
+ def __init__(self, kafka_config):
+ try:
+ from kafka import KafkaProducer
+ except ImportError:
+ logger.warning(
+ u'系统中可能没有安装kafka库,请先运行 pip install kafka-python ,再运行程序')
+ sys.exit()
+
+ self.kafka_config = kafka_config
+ self.producer = KafkaProducer(
+ bootstrap_servers=str(kafka_config['bootstrap-server']).split(','),
+ value_serializer=lambda m: json.dumps(m, ensure_ascii=False
+ ).encode('UTF-8'))
+ self.weibo_topics = list(kafka_config['weibo_topics'])
+ self.user_topics = list(kafka_config['user_topics'])
+ logger.info('{}', kafka_config)
+
+ def write_weibo(self, weibo):
+ for w in weibo:
+ w.user_id = self.user.id
+ for topic in self.weibo_topics:
+ self.producer.send(topic, value=w.__dict__)
+
+ def write_user(self, user):
+ self.user = user
+
+ for topic in self.user_topics:
+ self.producer.send(topic, value=user.__dict__)
+
+ def __del__(self):
+ self.producer.close()
diff --git a/weibo_spider/writer/mongo_writer.py b/weibo_spider/writer/mongo_writer.py
new file mode 100644
index 00000000..c6c08c5b
--- /dev/null
+++ b/weibo_spider/writer/mongo_writer.py
@@ -0,0 +1,62 @@
+import copy
+import logging
+import sys
+
+from .writer import Writer
+
+logger = logging.getLogger('spider.mongo_writer')
+
+
+class MongoWriter(Writer):
+ def __init__(self, mongo_config):
+ self.mongo_config = mongo_config
+ self.connection_string = mongo_config['connection_string']
+ self.dba_name = mongo_config.get('dba_name', None)
+ self.dba_password = mongo_config.get('dba_password', None)
+
+ def _info_to_mongodb(self, collection, info_list):
+ """将爬取的信息写入MongoDB数据库"""
+ try:
+ import pymongo
+ except ImportError:
+ logger.warning(
+ u'系统中可能没有安装pymongo库,请先运行 pip install pymongo ,再运行程序')
+ sys.exit()
+ try:
+ from pymongo import MongoClient
+
+ client = MongoClient(self.connection_string)
+ if self.dba_name or self.dba_password:
+ # authenticate() 在PyMongo3.6版本就已弃用,这一段可能需要后续跟进
+ client.admin.authenticate(
+ self.dba_name, self.dba_password, mechanism='SCRAM-SHA-1'
+ )
+
+ db = client['weibo']
+ collection = db[collection]
+ new_info_list = copy.deepcopy(info_list)
+ for info in new_info_list:
+ if not collection.find_one({'id': info['id']}):
+ collection.insert_one(info)
+ else:
+ collection.update_one({'id': info['id']}, {'$set': info})
+ except pymongo.errors.ServerSelectionTimeoutError:
+ logger.warning(
+ u'系统中可能没有安装或启动MongoDB数据库,请先根据系统环境安装或启动MongoDB,再运行程序')
+ sys.exit()
+
+ def write_weibo(self, weibos):
+ """将爬取的微博信息写入MongoDB数据库"""
+ weibo_list = []
+ for w in weibos:
+ w.user_id = self.user.id
+ weibo_list.append(w.__dict__)
+ self._info_to_mongodb('weibo', weibo_list)
+ logger.info(u'%d条微博写入MongoDB数据库完毕', len(weibos))
+
+ def write_user(self, user):
+ """将爬取的用户信息写入MongoDB数据库"""
+ self.user = user
+ user_list = [user.__dict__]
+ self._info_to_mongodb('user', user_list)
+ logger.info(u'%s信息写入MongoDB数据库完毕', user.nickname)
diff --git a/weibo_spider/writer/mysql_writer.py b/weibo_spider/writer/mysql_writer.py
new file mode 100644
index 00000000..7118c083
--- /dev/null
+++ b/weibo_spider/writer/mysql_writer.py
@@ -0,0 +1,142 @@
+import copy
+import logging
+import sys
+
+from .writer import Writer
+
+logger = logging.getLogger('spider.mysql_writer')
+
+
+class MySqlWriter(Writer):
+ def __init__(self, mysql_config):
+ self.mysql_config = mysql_config
+
+ # 创建'weibo'数据库
+ create_database = """CREATE DATABASE IF NOT EXISTS weibo DEFAULT
+ CHARACTER SET utf8mb4 COLLATE utf8mb4_unicode_ci"""
+ self._mysql_create_database(create_database)
+ self.mysql_config['db'] = 'weibo'
+
+ def _mysql_create(self, connection, sql):
+ """创建MySQL数据库或表"""
+ try:
+ with connection.cursor() as cursor:
+ cursor.execute(sql)
+ finally:
+ connection.close()
+
+ def _mysql_create_database(self, sql):
+ """创建MySQL数据库"""
+ try:
+ import pymysql
+ except ImportError:
+ logger.warning(
+ u'系统中可能没有安装pymysql库,请先运行 pip install pymysql ,再运行程序')
+ sys.exit()
+ try:
+ connection = pymysql.connect(**self.mysql_config)
+ self._mysql_create(connection, sql)
+ except pymysql.OperationalError:
+ logger.warning(u'系统中可能没有安装或正确配置MySQL数据库,请先根据系统环境安装或配置MySQL,再运行程序')
+ sys.exit()
+
+ def _mysql_create_table(self, sql):
+ """创建MySQL表"""
+ import pymysql
+ connection = pymysql.connect(**self.mysql_config)
+ self._mysql_create(connection, sql)
+
+ def _mysql_insert(self, table, data_list):
+ """向MySQL表插入或更新数据"""
+ import pymysql
+ if len(data_list) > 0:
+ # We use this to filter out unset values.
+ data_list = [{k: v
+ for k, v in data.items() if v is not None}
+ for data in data_list]
+
+ keys = ', '.join(data_list[0].keys())
+ values = ', '.join(['%s'] * len(data_list[0]))
+ connection = pymysql.connect(**self.mysql_config)
+ cursor = connection.cursor()
+ sql = """INSERT INTO {table}({keys}) VALUES ({values}) ON
+ DUPLICATE KEY UPDATE""".format(table=table,
+ keys=keys,
+ values=values)
+ update = ','.join([
+ ' {key} = values({key})'.format(key=key)
+ for key in data_list[0]
+ ])
+ sql += update
+ try:
+ cursor.executemany(
+ sql, [tuple(data.values()) for data in data_list])
+ connection.commit()
+ except Exception as e:
+ connection.rollback()
+ logger.exception(e)
+ finally:
+ connection.close()
+
+ def write_weibo(self, weibos):
+ """将爬取的微博信息写入MySQL数据库"""
+ # 创建'weibo'表
+ try:
+ create_table = """
+ CREATE TABLE IF NOT EXISTS weibo (
+ id varchar(10) NOT NULL,
+ user_id varchar(12),
+ content varchar(5000),
+ article_url varchar(200),
+ original_pictures varchar(3000),
+ retweet_pictures varchar(3000),
+ original BOOLEAN NOT NULL DEFAULT 1,
+ video_url varchar(300),
+ publish_place varchar(100),
+ publish_time DATETIME NOT NULL,
+ publish_tool varchar(30),
+ up_num INT NOT NULL,
+ retweet_num INT NOT NULL,
+ comment_num INT NOT NULL,
+ PRIMARY KEY (id)
+ ) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4"""
+ self._mysql_create_table(create_table)
+ # 在'weibo'表中插入或更新微博数据
+ weibo_list = []
+ info_list = copy.deepcopy(weibos)
+ for weibo in info_list:
+ weibo.user_id = self.user.id
+ weibo_list.append(weibo.__dict__)
+ self._mysql_insert('weibo', weibo_list)
+ logger.info(u'%d条微博写入MySQL数据库完毕', len(weibos))
+ except Exception as e:
+ logger.exception(e)
+
+ def write_user(self, user):
+ """将爬取的用户信息写入MySQL数据库"""
+ try:
+ self.user = user
+
+ # 创建'user'表
+ create_table = """
+ CREATE TABLE IF NOT EXISTS user (
+ id varchar(20) NOT NULL,
+ nickname varchar(30),
+ gender varchar(10),
+ location varchar(200),
+ birthday varchar(40),
+ description varchar(400),
+ verified_reason varchar(140),
+ talent varchar(200),
+ education varchar(200),
+ work varchar(200),
+ weibo_num INT,
+ following INT,
+ followers INT,
+ PRIMARY KEY (id)
+ ) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4"""
+ self._mysql_create_table(create_table)
+ self._mysql_insert('user', [user.__dict__])
+ logger.info(u'%s信息写入MySQL数据库完毕', user.nickname)
+ except Exception as e:
+ logger.exception(e)
diff --git a/weibo_spider/writer/post_writer.py b/weibo_spider/writer/post_writer.py
new file mode 100644
index 00000000..af536623
--- /dev/null
+++ b/weibo_spider/writer/post_writer.py
@@ -0,0 +1,59 @@
+import codecs
+import json
+import logging
+import os
+import requests
+
+from .writer import Writer
+from time import sleep
+from requests.exceptions import RequestException
+
+logger = logging.getLogger('spider.post_writer')
+
+class PostWriter(Writer):
+ def __init__(self, post_config):
+ self.post_config = post_config
+ self.api_url = post_config['api_url']
+ self.api_token = post_config.get('api_token', None)
+ self.dba_password = post_config.get('dba_password', None)
+
+ def write_user(self, user):
+ self.user = user
+
+ def _update_json_data(self, data, weibo_info):
+ """将获取到的微博数据转换为json输出模式一致"""
+ data['user'] = self.user.__dict__
+ if data.get('weibo'):
+ data['weibo'] += weibo_info
+ else:
+ data['weibo'] = weibo_info
+ return data
+
+ def send_post_request_with_token(self, url, data, token, max_retries, backoff_factor):
+ headers = {
+ 'Content-Type': 'application/json',
+ 'api-token': f'{token}',
+ }
+ for attempt in range(max_retries + 1):
+ try:
+ response = requests.post(url, json=data, headers=headers)
+ if response.status_code == requests.codes.ok:
+ return response.json()
+ else:
+ raise RequestException(f"Unexpected response status: {response.status_code}")
+ except RequestException as e:
+ if attempt < max_retries:
+ sleep(backoff_factor * (attempt + 1)) # 逐步增加等待时间,避免频繁重试
+ continue
+ else:
+ logger.error(f"在尝试{max_retries}次发出POST连接后,请求失败:{e}")
+
+ def write_weibo(self, weibos):
+ """将爬到的信息POST到API"""
+ data = {}
+ data = self._update_json_data(data, [w.__dict__ for w in weibos])
+ if data:
+ self.send_post_request_with_token(self.api_url, data, self.api_token, 3, 2)
+ logger.info(u'%d条微博通过POST发送到 %s', len(weibos), self.api_url)
+ else:
+ logger.info(u'没有获取到微博,略过API POST')
diff --git a/weibo_spider/writer/sqlite_writer.py b/weibo_spider/writer/sqlite_writer.py
new file mode 100644
index 00000000..cea0ccd9
--- /dev/null
+++ b/weibo_spider/writer/sqlite_writer.py
@@ -0,0 +1,108 @@
+import copy
+import logging
+import sys
+
+from .writer import Writer
+
+logger = logging.getLogger('spider.sqlite_writer')
+
+
+class SqliteWriter(Writer):
+ def __init__(self, sqlite_config):
+ self.sqlite_config = sqlite_config
+
+ def _sqlite_create(self, connection, sql):
+ """创建sqlite数据库或表"""
+ try:
+ cursor = connection.cursor()
+ cursor.execute(sql)
+ finally:
+ connection.close()
+
+ def _sqlite_create_table(self, sql):
+ """创建sqlite表"""
+ import sqlite3
+ connection = sqlite3.connect(self.sqlite_config)
+ self._sqlite_create(connection, sql)
+
+ def _sqlite_insert(self, table, data_list):
+ """向sqlite表插入或更新数据"""
+ import sqlite3
+ if len(data_list) > 0:
+ # We use this to filter out unset values.
+ data_list = [{k: v
+ for k, v in data.items() if v is not None}
+ for data in data_list]
+
+ keys = ', '.join(data_list[0].keys())
+ values = ', '.join(['?'] * len(data_list[0]))
+ connection = sqlite3.connect(self.sqlite_config)
+ cursor = connection.cursor()
+ sql = """INSERT OR REPLACE INTO {table}({keys}) VALUES ({values})""".format(
+ table=table, keys=keys, values=values)
+ try:
+ cursor.executemany(
+ sql, [tuple(data.values()) for data in data_list])
+ connection.commit()
+ except Exception as e:
+ connection.rollback()
+ logger.exception(e)
+ finally:
+ connection.close()
+
+ def write_weibo(self, weibos):
+ """将爬取的微博信息写入sqlite数据库"""
+ # 创建'weibo'表
+ create_table = """
+ CREATE TABLE IF NOT EXISTS weibo (
+ id varchar(10) NOT NULL,
+ user_id varchar(12),
+ content varchar(2000),
+ article_url varchar(200),
+ original_pictures varchar(3000),
+ retweet_pictures varchar(3000),
+ original BOOLEAN NOT NULL DEFAULT 1,
+ video_url varchar(300),
+ publish_place varchar(100),
+ publish_time DATETIME NOT NULL,
+ publish_tool varchar(30),
+ up_num INT NOT NULL,
+ retweet_num INT NOT NULL,
+ comment_num INT NOT NULL,
+ PRIMARY KEY (id)
+ )"""
+ self._sqlite_create_table(create_table)
+ # 在'weibo'表中插入或更新微博数据
+ weibo_list = []
+ info_list = copy.deepcopy(weibos)
+ for weibo in info_list:
+ weibo.user_id = self.user.id
+ weibo_list.append(weibo.__dict__)
+ self._sqlite_insert('weibo', weibo_list)
+ logger.info(u'%d条微博写入sqlite数据库完毕', len(weibos))
+
+ def write_user(self, user):
+ """将爬取的用户信息写入sqlite数据库"""
+ self.user = user
+
+ # 创建'user'表
+ create_table = """
+ CREATE TABLE IF NOT EXISTS user (
+ id varchar(20) NOT NULL,
+ nickname varchar(30),
+ gender varchar(10),
+ location varchar(200),
+ birthday varchar(40),
+ description varchar(400),
+ verified_reason varchar(140),
+ talent varchar(200),
+ education varchar(200),
+ work varchar(200),
+ weibo_num INT,
+ following INT,
+ followers INT,
+ PRIMARY KEY (id)
+ )"""
+ self._sqlite_create_table(create_table)
+ self._sqlite_insert('user', [user.__dict__])
+ logger.info(u'%s信息写入sqlite数据库完毕', user.nickname)
diff --git a/weibo_spider/writer/txt_writer.py b/weibo_spider/writer/txt_writer.py
new file mode 100644
index 00000000..6eddd862
--- /dev/null
+++ b/weibo_spider/writer/txt_writer.py
@@ -0,0 +1,57 @@
+import logging
+import sys
+
+from .writer import Writer
+
+logger = logging.getLogger('spider.txt_writer')
+
+
+class TxtWriter(Writer):
+ def __init__(self, file_path, filter):
+ self.file_path = file_path
+
+ self.user_header = u'用户信息'
+ self.user_desc = [('nickname', '用户昵称'), ('id', '用户id'),
+ ('weibo_num', '微博数'), ('following', '关注数'),
+ ('followers', '粉丝数')]
+
+ if filter:
+ self.weibo_header = u'原创微博内容'
+ else:
+ self.weibo_header = u'微博内容'
+ self.weibo_desc = [('publish_place', '微博位置'), ('publish_time', '发布时间'),
+ ('up_num', '点赞数'), ('retweet_num', '转发数'),
+ ('comment_num', '评论数'), ('publish_tool', '发布工具')]
+
+ def write_user(self, user):
+ self.user = user
+ user_info = '\n'.join(
+ [v + ':' + str(self.user.__dict__[k]) for k, v in self.user_desc])
+
+ with open(self.file_path, 'ab') as f:
+ f.write((self.user_header + ':\n' + user_info + '\n\n').encode(
+ sys.stdout.encoding))
+ logger.info(u'%s信息写入txt文件完毕,保存路径:%s', self.user.nickname,
+ self.file_path)
+
+ def write_weibo(self, weibo):
+ """将爬取的信息写入txt文件"""
+
+ weibo_header = ''
+ if self.weibo_header:
+ weibo_header = self.weibo_header + ':\n'
+ self.weibo_header = ''
+
+ try:
+ temp_result = []
+ for w in weibo:
+ temp_result.append(w.__dict__['content'] + '\n' + '\n'.join(
+ [v + ':' + str(w.__dict__[k])
+ for k, v in self.weibo_desc]))
+ result = '\n\n'.join(temp_result) + '\n\n'
+
+ with open(self.file_path, 'ab') as f:
+ f.write((weibo_header + result).encode(sys.stdout.encoding))
+ logger.info(u'%d条微博写入txt文件完毕,保存路径:%s', len(weibo), self.file_path)
+ except Exception as e:
+ logger.exception(e)
diff --git a/weibo_spider/writer/writer.py b/weibo_spider/writer/writer.py
new file mode 100644
index 00000000..45366510
--- /dev/null
+++ b/weibo_spider/writer/writer.py
@@ -0,0 +1,17 @@
+from abc import ABC, abstractmethod
+
+
+class Writer(ABC):
+ def __init__(self):
+ """根据需要,初始化结果路径、初始化表头、初始化数据库等"""
+ pass
+
+ @abstractmethod
+ def write_weibo(self, weibo):
+ """给定微博信息,写入对应文本或数据库"""
+ pass
+
+ @abstractmethod
+ def write_user(self, user):
+ """给定用户信息,写入对应文本或数据库"""
+ pass