
Open-source database access governance platform
A SQL and NoSQL proxy that puts review, approval, and audit between your team and production data.
![]()
Website · Live Docs · Quick Start · Design Docs
AccessFlow sits as a full query proxy in front of your databases — the relational engines PostgreSQL, MySQL, MariaDB, Oracle, and Microsoft SQL Server are supported out of the box via a declarative connector catalog (additional engines such as ClickHouse install with one click), any other JDBC-compatible engine can be added by uploading its driver JAR, the NoSQL document engines MongoDB and Couchbase (SQL++), the NoSQL key-value engine Redis, the NoSQL wide-column engines Apache Cassandra (CQL) and ScyllaDB (CQL-compatible), the NoSQL search engines Elasticsearch and OpenSearch, the NoSQL key-value engine Amazon DynamoDB (PartiQL), and the NoSQL graph engine Neo4j (Cypher over Bolt) install the same way through on-demand native engine plugins. The catalog separates the SQL (relational) family from the NoSQL umbrella of native engine-managed connectors. Every query a user submits — SQL, a MongoDB shell / JSON command, a Couchbase SQL++ statement, a Redis command, a Cassandra/ScyllaDB CQL statement, an Elasticsearch/OpenSearch query, a DynamoDB PartiQL statement, or a Neo4j Cypher statement — is parsed, classified, optionally analyzed by AI, and routed through a configurable human-approval workflow before it ever reaches live data. Every request, decision, and execution is captured in a tamper-evident metadata audit log. Authentication is JWT (RS256) with optional SAML 2.0 SSO and OAuth 2.0 / OIDC sign-in (built-in templates for Google, GitHub, GitHub Enterprise Server, Microsoft, GitLab, and self-managed GitLab). AccessFlow ships as a single open-source product under Apache 2.0 and is designed to run entirely inside your own infrastructure.
Most teams pick one of two extremes for database access:
- Shared production credentials — anyone with the password can run
DELETE. Fast, but a single mistake is unbounded and there is no record of who did what. - Ticket-driven DBA access — every change goes through a manual DBA queue. Safe, but slow enough that engineers route around it.
AccessFlow provides the missing middle: governed, self-service access where every query is reviewable, every approval is traceable, and AI catches the obvious problems before a human ever sees the request.
A glance at the day-to-day flows engineers and approvers actually use.
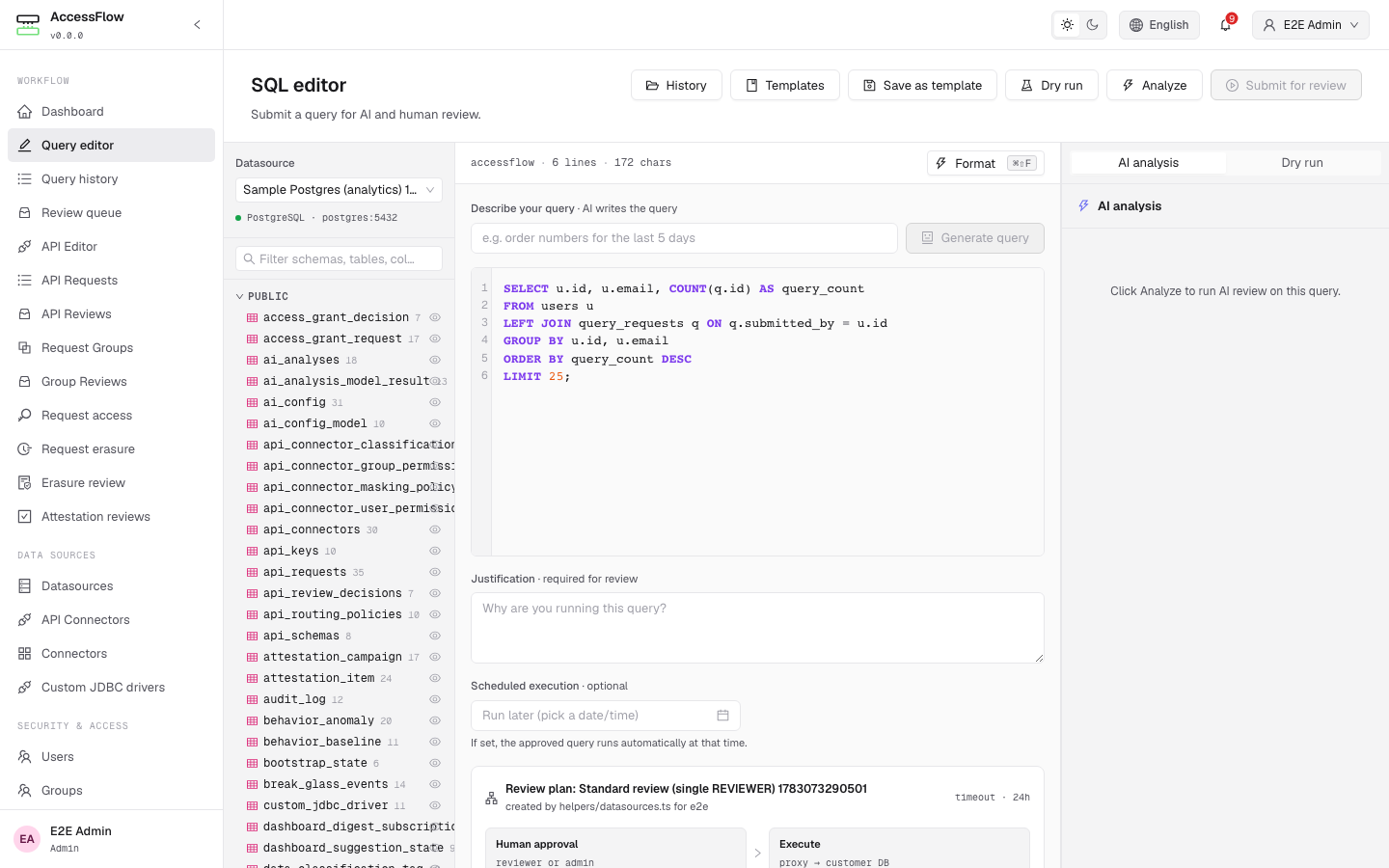
Submit a query — CodeMirror 6 with dialect-aware highlighting, live schema autocomplete, and an inline review-plan preview that shows exactly which approvals the submission will trigger.
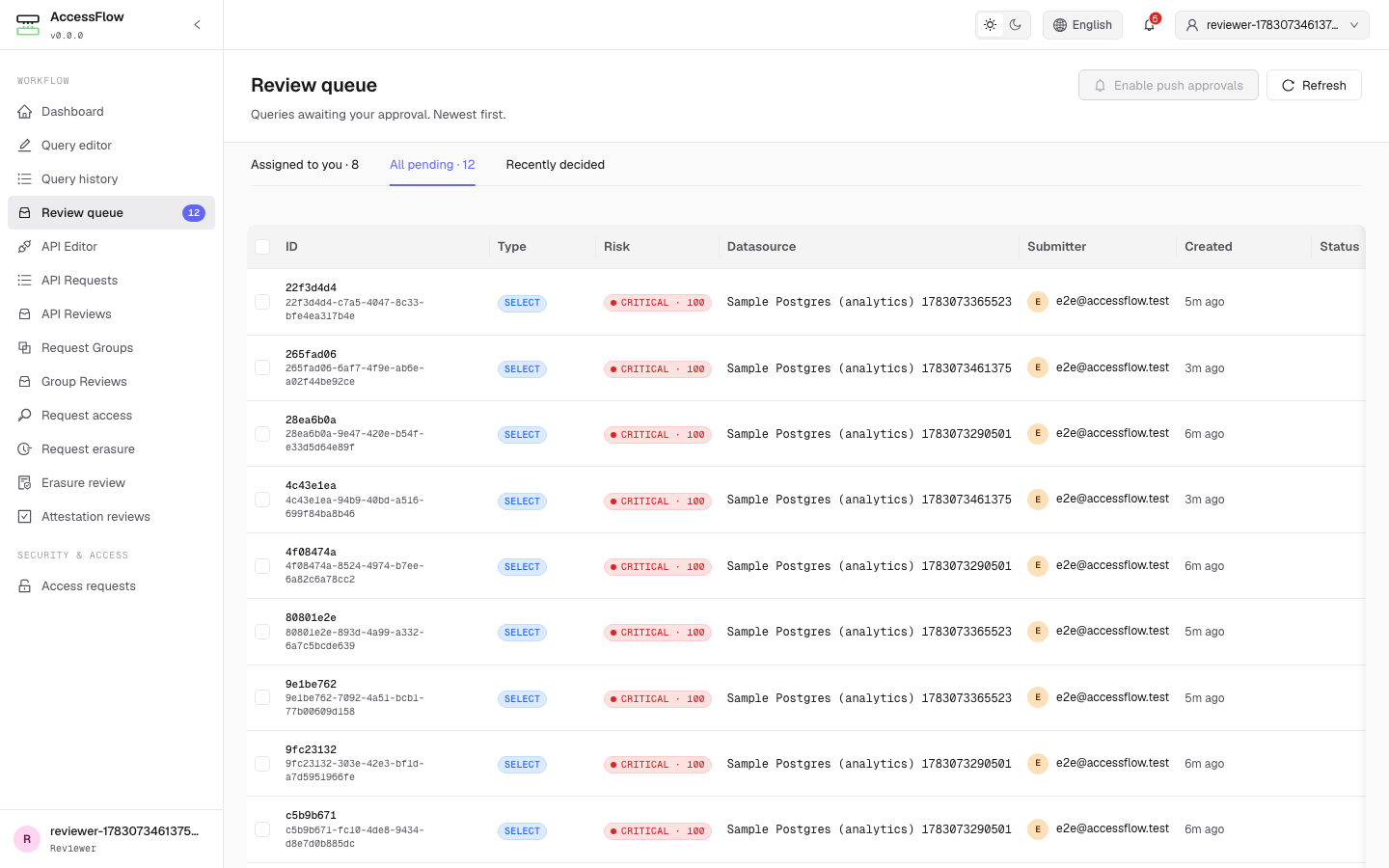
Approve or reject pending writes from one place — the queue is scoped to queries assigned to you, with risk score, query type, and submitter at a glance. A user can never approve their own query.
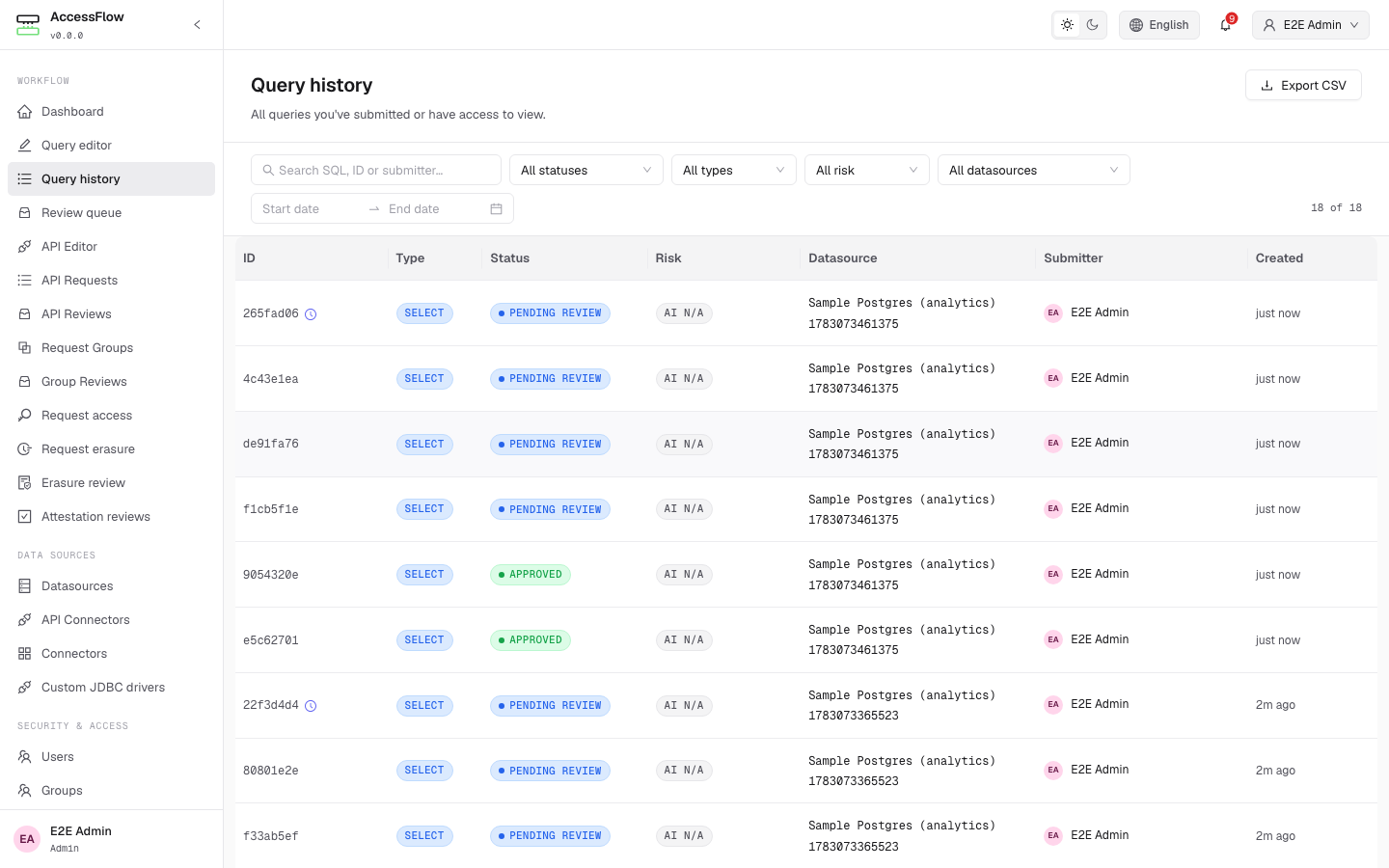
Searchable, filterable history of every query — by status, type, risk, datasource, submitter, or date range — with CSV export. Each row links to the full request, AI analysis, approval timeline, and result set.
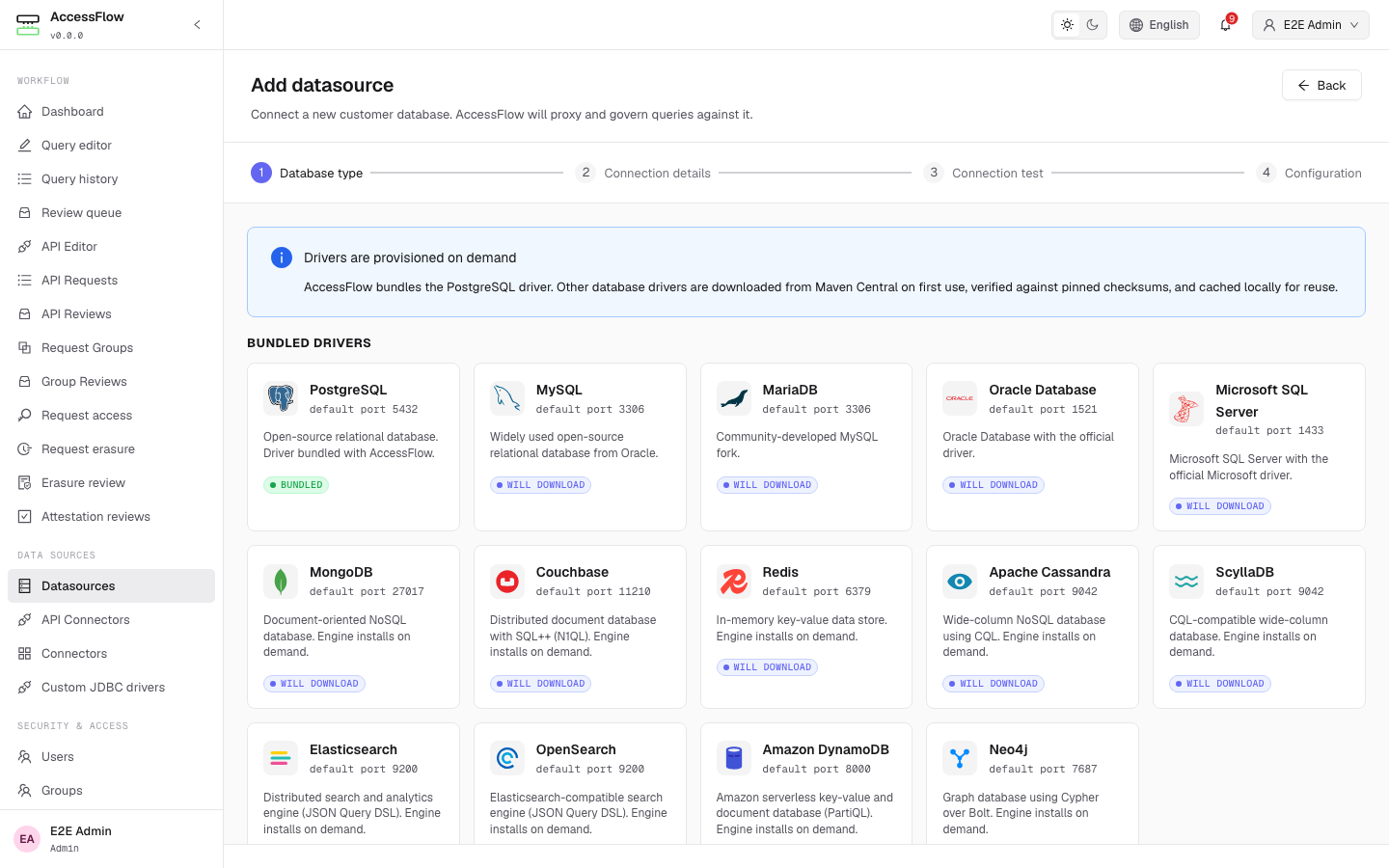
Connect a database in the admin UI — credentials are AES-256-GCM encrypted at rest, the proxy holds them, and end users never see them.
More walkthroughs — Review plans, AI provider configuration, notification channels (Email, Slack, Discord, Telegram, Teams, PagerDuty, webhooks), OAuth 2.0 / OIDC sign-in, SAML 2.0 SSO, users & invitations, and system SMTP all have step-by-step screenshots on the public documentation site.
- Proxy-first execution — no user ever holds production credentials; the proxy holds them encrypted and opens connections only after approval. Single SQL statements run with autocommit; multi-statement INSERT/UPDATE/DELETE batches wrapped in
BEGIN; … COMMIT;execute atomically inside one JDBC transaction (mixed SELECT/DML batches are rejected at parse time). Optional read-replica routing: attach a replica JDBC URL to a datasource and SELECT traffic is served from there, with automatic primary fall-back and an audit row on replica failure. - Configurable review workflows — per-datasource review plans, multi-stage sequential approval chains, optional auto-approve for reads, approval timeouts with auto-reject. Reviewers can be scoped per-datasource (directly or via groups) so different teams see only the queues that belong to them.
- Policy-as-code routing — ordered, attribute-based routing policies decide a query's path after AI analysis and before reviewers see it: auto-approve, auto-reject, require N approvals, or escalate. Conditions match on query type, referenced tables (glob), AI risk level / score, requester role or group, time-of-day / day-of-week, WHERE / LIMIT presence, the transactional flag, and the submission client context — source IP / CIDR, user-agent, time-since-last-approval, and CI/CD origin (API key or
X-AccessFlow-CIheader) — combined with AND / OR / NOT. Client-context conditions fail closed (missing context never auto-approves), so an off-network or stale-approval query escalates to stricter review instead. First match by priority wins; on no match the query falls through to the datasource's review plan. Every automated decision is recorded in the audit log. - Just-in-time (JIT) access requests — users self-request temporary, scoped datasource access (read/write/DDL for an ISO-8601 duration). Requests flow through the same approval engine, a time-boxed permission is granted on approval, and a clustered scheduler auto-revokes it on expiry (admins can also revoke early).
- Break-glass / emergency access — a gated emergency path for when production is on fire and approvers are asleep. A per-user/per-datasource
can_break_glasspermission (required for everyone, including admins; time-boxed) lets a query execute immediately, bypassing review — still through every proxy guard (allow-list, masking, row-level security, row caps). Compensating controls: a mandatory justification, instant fanout to all org admins (incl. PagerDuty), a prominently-tagged audit row, and a mandatory retro-review an admin (never the submitter) must acknowledge on the/admin/break-glasslog. - Dynamic data masking — per-column masking policies (full, partial last-N, stable hash, email-preserving, format-preserving) with role / group / user reveal conditions evaluated per requester. Masking is applied at result-read time before results are serialized or stored, so unmasked values never persist; applied policy ids are recorded in the audit log. Extends the static
restricted_columnsmasking. - Row-level security — per-table row predicates the proxy injects into the parsed SQL so a scoped user only sees (SELECT) or affects (UPDATE/DELETE) the rows they are authorised for. Admins author a structured
column operator valuepredicate where the value is a fixed literal or a:user.*variable (built-in id / email / role / groups, or an admin-set per-user attribute). Values are bound as JDBC parameters — never concatenated; predicates that can't be safely applied are rejected, never run unfiltered. Composes with column masking and the schema/table allow-list. - Data classification tagging — tag tables and columns as PII, PCI, PHI, GDPR, FINANCIAL, or SENSITIVE right in the schema explorer. Tagging a column auto-applies a masking policy, the AI analyzer raises a query's risk score when it touches a tagged object, and a derivation preview suggests a stricter review posture. Tags are audited and queryable org-wide as the evidence base for compliance reporting.
- User groups — bundle reviewers (and other users) into groups; groups can be assigned as datasource reviewers, granted data/API access (a whole team inherits a datasource or API-connector grant — read/write/DDL/break-glass — instead of a row per member; effective access is the most-permissive union of a user's direct and group grants), and auto-synced from SAML / OAuth2 IdP claims via per-IdP
group_mappings(admin-managed memberships are preserved across logins). - AI query analysis — pluggable adapters for OpenAI, Anthropic Claude, self-hosted Ollama, any OpenAI API–compatible backend (vLLM, LM Studio, Together, Groq, OpenRouter, …) via a custom endpoint, and Hugging Face (Inference Providers router or a local / self-hosted TGI server); risk scoring (0–100), missing-index detection, anti-pattern hints. Per-organization configuration via the admin UI, including an editable analyzer prompt per configuration (override the built-in template, or leave it blank to use the default); admin AI analyses dashboard charts average risk over time, top issue categories, and most active submitters. A per-organization rate limit (requests/minute, default 30) and optional monthly token budget cap AI usage so a runaway editor or compromised account can't drain the provider API key — enforced before every analysis call; exceedance returns HTTP 429 in the editor or records a sentinel
CRITICALanalysis row on the async path. - Multi-model orchestration, voting & guardrails — an AI configuration can run several models in parallel (the primary plus weighted
{provider, model, weight}members — e.g. a fast local Ollama pre-score alongside a deep Claude analysis) and combine their verdicts by a configurable voting strategy (weighted average, highest risk, or majority); issues are merged and risk aggregated. Guardrails block configured prompt patterns (case-insensitive regex) before any model is called, and the strict output-schema validation rejects malformed responses without failing the query. Per-model cost (tokens) and latency are recorded for every analysis and charted on the admin dashboard. - Query-optimization suggestions — alongside the risk verdict, the analyzer returns concrete, dialect-aware optimization suggestions: index recommendations (
CREATE INDEX …) and query rewrites. Each suggestion has a one-click "Apply as draft" that pre-fills the editor with the suggested statement and routes it through the normal review pipeline — nothing auto-executes, and the draft is audited as AI-suggested. - Query playground / dry-run sandbox — preview a query's impact before submitting it for review. A Dry run action returns the engine's execution plan (node type, estimated rows, cost, filters) and a best-effort estimated row impact without executing or mutating data, shown in the editor next to the AI panel. It runs through the same governance as a real execution (datasource access, table allow-list, row-level security) but creates no review. Dialect-aware across every engine with a plan concept — relational
EXPLAIN(PostgreSQL / MySQL / MariaDB / Oracle / SQL Server), MongoDBexplain, Couchbase / Neo4jEXPLAIN, Elasticsearch / OpenSearch query validation; engines without one degrade gracefully. SELECT dry-runs prefer the read replica when configured. - Text-to-query — opt-in per datasource. Users describe what they want in plain language ("order numbers for the last 5 days") and the AI drafts a schema-grounded query into the editor — in the datasource engine's native query language (SQL for relational engines, plus MongoDB shell/JSON, Cypher, CQL, Elasticsearch Query DSL, redis-cli, SQL++, and PartiQL for the NoSQL engines). Reuses the datasource's AI configuration and is grounded in its introspected schema (restricted columns are never referenced). The generated query is only a draft — it's still submitted through the normal pipeline, so AI risk analysis and human review always apply.
- RAG knowledge base — opt-in per AI configuration. Attach knowledge documents (data-governance policies, naming conventions, schema notes); AccessFlow embeds them with a dedicated embedding model and, at analysis / text-to-SQL time, retrieves the most relevant chunks and injects them into the prompt — so analysis reflects your house rules. Pluggable vector store: in-app pgvector (self-contained, auto-provisioned where the DB role permits — and optional: AccessFlow still starts if the extension is absent, with the in-app store disabled) or external Qdrant. Retrieval is best-effort and never blocks analysis.
- Langfuse integration — optional, per-organization. Send a trace of every AI analysis (input SQL, structured output, model, token usage, latency) to Langfuse for LLM observability, and/or fetch analyzer prompts from Langfuse by name at runtime (prompt management) so you can iterate on prompts without redeploying. Best-effort and non-blocking — a Langfuse outage never affects query workflow.
- Datasource health dashboard — admin-only
/admin/datasource-healthsurfaces per-datasource HikariCP pool utilisation plus a trailing 24h summary of query volume, p50/p95 execution latency, and error count, so operators can spot pool exhaustion, slow datasources, or volume spikes. Auto-refreshes every 30s. - Built-in SQL editor — CodeMirror 6 with dialect-aware highlighting, schema autocomplete from live introspection, SQL formatter, and inline AI hint markers.
- Schema exploration — a searchable object tree (filter across schemas, tables, and columns), an entity-relationship diagram, and on-demand sample-row previews for any table that are row-level-security- and masking-aware, so masked columns never reveal raw values in the preview.
- Query templates library — save frequently used queries (private or team-visible) with tags and
:placeholdersubstitution, then load them straight into the editor and share them across the team. Every save records an immutable version, so you can review how a query evolved with a side-by-side Git-style diff and restore any prior revision. - Real-time collaborative editing — co-author a query that's in review with the submitter and reviewers (VS Code Live Share / Google Docs style): live presence, remote cursors, conflict-free CRDT merge over the existing
/ws, and inline comment threads anchored to the SQL (persisted and audited). Edits re-enter the workflow through the normal submit path, so approval guarantees are never weakened. - Query result diffing — re-running the same query links the run to its previous execution and surfaces the delta in
rows_affected, row count, and execution time, so reviewers can spot drift between repeated runs. - Immutable query snapshots & replay — every executed query writes a sanitized, exact-replay-capable snapshot (SQL, schema fingerprint, AI verdict, approval decisions). A Replay in test environment action re-runs that exact SQL against a chosen test datasource through the full review workflow — validating engine + referenced-table compatibility, never skipping approval, and distinctly audited (
trigger=replay). - Access recertification campaigns — schedule recurring attestation campaigns (org- or datasource-scoped) that snapshot current standing datasource grants into per-grant items and notify the eligible reviewers. Reviewers certify or revoke each item from a worklist that reuses the review-queue patterns (self-review blocked, bulk-certify); a revoke routes through the normal permission-revoke path. Two clustered-safe scheduled jobs open campaigns on their cadence and close them at the due date, applying a configurable
KEEP/REVOKEdefault to anything still pending, and a completed campaign exports as CSV evidence (who reviewed what, decisions, timestamps) for SOC2 / ISO 27001 audits — every transition landing in the tamper-evident audit log. - Tamper-evident audit log — INSERT-only table chained with HMAC-SHA256; INSERT-only DB grants make after-the-fact rewrites detectable.
- Compliance reporting — pre-built reports over a period for audit evidence: a classified-data-access report (which executed queries touched PII/PCI/PHI/GDPR/FINANCIAL/SENSITIVE objects) and a regulatory audit trail of DDL/DELETE operations with approver names, computed from the immutable query snapshots. Reports export as digitally signed PDF/CSV (verifiable offline with the published public key) whose hash is chained into the tamper-evident audit log. A dedicated read-only Auditor role exposes the auditor dashboard.
- Behavioral anomaly detection (UBA) — a clustered-safe background job builds rolling per-
(user, datasource)behavioural baselines from the audit log alone (never query result data) and flags out-of-pattern activity — query volume, off-hours access, distinct/new tables, query types, rows returned, and error rate — using z-score detection with a robust IQR fallback. Each anomaly carries an optional AI natural-language explanation, escalates the flagged user's next query via a routing condition, fires a notification (incl. PagerDuty), and surfaces on an/admin/anomaliesdashboard where an admin can acknowledge or dismiss it. Auditors can review anomalies read-only. - Personalized dashboard — the default post-login home (
/dashboard) gives every user a self-scoped view of what's waiting on them: pending approvals as a reviewer, their recent queries with status/risk trend sparklines, an actionable AI optimization-suggestion backlog (dismissable, one-click "open in editor"), and their own behavioural-anomaly alerts. Widgets are customizable — show/hide, collapse, and drag-and-drop reorder, persisted across sessions. The week's summary is exportable on demand as a digitally signed PDF/CSV, and an opt-in weekly email digest delivers it on a schedule. - Observability — OpenTelemetry OTLP trace export of the full proxy pipeline (parse → AI analyze → pool acquire → execute) to Tempo / Jaeger / Honeycomb, Prometheus metrics at
/actuator/prometheus, and two pre-built Grafana dashboards (shipped via the Helm chart) covering query volume, approval SLAs, AI usage/cost, rejection rates, and connection-pool stats. Structured JSON logging (logstash / ECS / GELF) with atraceIdcorrelated across logs, error responses, and traces. - Real-time updates — single WebSocket at
/wsfans review-queue, status, and AI-analysis events to connected clients. - Notifications — Email (SMTP), Slack, Discord, Telegram, Microsoft Teams, PagerDuty, and HMAC-signed outbound webhooks with retry policy.
- Slack approve/reject — a configured Slack app adds Approve / Reject buttons to review-request messages; the decision runs through the same self-approval and RBAC guards as the REST API (HMAC-verified Interactive Components).
- Mobile approvals (PWA) with one-tap push — install AccessFlow as a Progressive Web App with an offline-capable review queue, and get Web Push notifications when a query needs your approval. Approve or reject in one tap — the decision only commits after a step-up re-verification (password, or TOTP when 2FA is on), and the self-approval guard is enforced server-side on every channel.
- Identity & SSO — JWT access tokens (15 min) + HttpOnly refresh cookies, optional SAML 2.0 SSO, OAuth 2.0 / OIDC sign-in with built-in templates for Google, GitHub, GitHub Enterprise Server, Microsoft, GitLab, and self-managed GitLab plus a generic
OIDCprovider for other IdPs (Keycloak, Auth0, Okta, Authentik, Zitadel), password reset and user-invitation flows. - Multi-tenant organization management — a single deployment hosts one or more fully-isolated organizations (every entity is scoped by org, always derived from the JWT). A super-admin (
platform_admin) manages tenants across the cluster — create, edit, disable / enable — with per-org quotas (max_datasources,max_users,max_queries_per_day; a breach returns409 QUOTA_EXCEEDED) and a disabled-org kill-switch that blocks login and requests immediately. - MCP server — built-in Spring AI MCP server exposes a stateless tool surface so external AI agents can submit queries through the same review pipeline, and also discover schemas, validate SQL without executing it, read masking- and row-security-aware sample data, monitor their queries, and review their own audit trail.
- Connector catalog — supported databases are described declaratively in a repo-root
connectors/folder (one manifest + logo per connector), not hardcoded. Each connector carries acategory(RELATIONALfor the SQL family;DOCUMENT,KEY_VALUE,WIDE_COLUMN,SEARCH, orGRAPHfor the NoSQL umbrella) and the marketplace groups them into SQL and NoSQL sections accordingly. Admins browse the Connectors marketplace and install a relational database's JDBC driver with one click (downloaded + SHA-256-verified + cached); engines beyond the built-in five (e.g. ClickHouse) install the same way. MongoDB, Couchbase, Redis, Apache Cassandra, ScyllaDB, Elasticsearch, OpenSearch, Amazon DynamoDB, and Neo4j are native (non-JDBC) engine-managed connectors whose engines ship as on-demand plugin JARs (engines/mongodb/,engines/couchbase/,engines/redis/,engines/cassandra/— the Cassandra plugin serves both Cassandra and ScyllaDB;engines/elasticsearch/— the Elasticsearch plugin serves both Elasticsearch and OpenSearch;engines/dynamodb/;engines/neo4j/), downloaded + verified through the same catalog pipeline. The catalog ships in the image and is also published as a release artifact. - MongoDB (NoSQL) — a first-class document connector. Users write MongoDB queries in either the familiar shell form (
db.users.find({ age: { $gt: 21 } })) or a JSON command document, selectable in the editor; results render in both a JSON document view and a flattened table view. The same governance applies — AI risk analysis, human approval, row-level security ($matchinjection), and field masking. - Couchbase (NoSQL) — a first-class document connector speaking SQL++ (N1QL), shipped as the second on-demand engine plugin (
engines/couchbase/). SQL++ statements get SQL-style highlighting and formatting in the editor, classify onto the same approval workflow, and run with row-level security ANDed into the WHERE clause (named parameters, fail-closed on unrewritable shapes) plus field masking; dangerous constructs (CURL(), JavaScript UDFs,system:*keyspaces) are rejected up front. - Redis (NoSQL key-value) — a first-class key-value connector, shipped as the third on-demand engine plugin (
engines/redis/, native Jedis driver). Users submit redis-cli commands (GET user:42,HGETALL session:abc,SCAN 0 MATCH orders:* COUNT 100) classified onto the same approval workflow; field masking applies to returned hash fields / values. Row-security policies on a Redis datasource fail closed (row predicates have no key-value meaning), and server-side scripting / blast-radius commands (EVAL,CONFIG,FLUSHALL,SHUTDOWN, …) are rejected at submission. - Cassandra & ScyllaDB (NoSQL wide-column) — first-class wide-column connectors speaking CQL, shipped as the fourth on-demand engine plugin (
engines/cassandra/, native DataStax Java driver); the same plugin JAR serves both Apache Cassandra and the CQL-compatible ScyllaDB. CQL statements classify onto the same approval workflow (SELECT / INSERT / UPDATE / DELETE plusCREATE/ALTER/DROPandTRUNCATE); row-level security is key-aware and fails closed — predicates splice into the WHERE clause only on partition/clustering key columns with CQL-filterable operators (=, IN, <, <=, >, >=), and a non-key column,!=/NOT IN, or INSERT into a policied table is rejected rather than injectingALLOW FILTERING, plus field masking on returned columns. Server-side code (BEGIN … BATCH,CREATE/DROP FUNCTION/AGGREGATE) is rejected up front. Each datasource sets its load-balancinglocal_datacenter. - Elasticsearch & OpenSearch (NoSQL search) — first-class search connectors, shipped as the fifth on-demand engine plugin (
engines/elasticsearch/, low-level REST client); the same plugin JAR serves both Elasticsearch and the wire-compatible OpenSearch. Users write a JSON query envelope ({"search":"logs-*","query":{…}}, pluscount,get/mget,index/bulk,update_by_query/delete_by_query, and index management) classified onto the same approval workflow; row-level security injectsbool.filterclauses on keyword fields (fail-closed on writes into a policied index), and field masking applies recursively to_sourcefields including nested dot-paths. Server-side scripting (script,runtime_mappings, Painless) and cluster/system-index APIs are rejected up front. Each datasource authenticates with basic auth or an API key. - Amazon DynamoDB (NoSQL key-value) — a first-class key-value connector speaking PartiQL, shipped as the sixth on-demand engine plugin (
engines/dynamodb/, AWS SDK for Java v2 over the url-connection HTTP client — no Netty). It is the first engine whose connection is cloud credentials + region rather than host/port: the region, access key id, secret access key, and an optional custom endpoint (DynamoDB Local / VPC) map onto the existing datasource fields. PartiQL SELECT / INSERT / UPDATE / DELETE classify onto the same approval workflow, and table management (CreateTable/DeleteTable/UpdateTable) arrives as a JSON command document; transaction/batch statements are rejected. Row-level security splices predicates into the PartiQL WHERE clause (positional parameters, any attribute), failing closed on INSERT-into-policied and deny-all, and field masking applies recursively by dot-path including nested maps/lists. - Neo4j (NoSQL graph) — a first-class graph connector speaking Cypher over Bolt, shipped as the seventh on-demand engine plugin (
engines/neo4j/, native Neo4j Java driver). Cypher is clause-based, so the query type is the strongest write clause present (DELETE/REMOVE → DELETE, CREATE/MERGE → INSERT, SET → UPDATE, else aMATCH … RETURN/SHOWread → SELECT), with index/constraint/database/role schema commands as DDL;LOAD CSV, procedure calls outside a read-only allow-list, and multi-statement input are rejected up front. Row-level security ANDs property predicates onto eachMATCH'sWHERE(Cypher named parameters, node-label policies), failing closed on anonymous / write-creates-policied-label shapes; field masking is label-aware and recursive. Connection is host/port + database with the SSL mode encoded in the Bolt scheme, or a fullbolt:///neo4j+s://URI (Neo4j Aura / clustered routing). - API Access Governance (AF-500) — govern outbound API calls (REST / SOAP / GraphQL / gRPC), not just databases. An admin registers an API connector (URL + auth + protocol + admin-defined default headers; secrets AES-256-GCM encrypted) — including OAuth2 with automatic token fetch, caching & refresh (client-credentials / refresh-token / resource-owner password), so no bearer token is pasted by hand — uploads its schema (OpenAPI / WSDL / GraphQL SDL / gRPC proto, by paste, file upload, or URL fetch) which is parsed into a normalized operation catalog with read/write classification, and shares governed connectivity with the team via per-user permissions. Users compose calls like Postman — query params, custom headers, raw / form-data / x-www-form-urlencoded / binary file bodies. Every call flows through the same machinery as a database query: AI risk scoring, attribute-based routing, multi-stage human approval (no self-approval), connector-level response masking (policies targeting a schema field, JSON path, XML/XPath, or regex — with a masking strategy and role / group / user reveal scoping) and data-classification tags (PII/PCI/PHI/GDPR/FINANCIAL/SENSITIVE that auto-derive a masking policy and raise the AI risk — AF-518), immutable response snapshots (downloadable in full), W3C trace-context propagation (filterable by trace/span id), break-glass, scheduled execution, and natural-language text-to-API. See
docs/17-api-governance.md. - Request chaining & grouping (AF-501) — bundle several steps into one grouped request reviewed and approved as a single element, then executed as an ordered sequence. Members can mix queries across different datasources and API calls against governed connectors; a builder lets you add steps, drag-reorder them, and author each one in a full-parity editing drawer — query steps get the complete Query Editor surface (schema autocomplete, AI analyze, dry-run, text-to-SQL, templates), API steps the complete API Editor surface (operation picker, request composer, AI analyze, text-to-API) — with an aggregate risk badge, and saved drafts re-open for editing without losing the composed request. Bundling never weakens a member's policy: each member is validated against your permission for its target (break-glass groups require
can_break_glasson every target), the required approvers are the union across all member plans, and the group is approved only when every member plan is satisfied — the submitter can never approve their own group. On execute, members run in order; on the first failure the run stops and the rest are skipped (continue-on-errorruns them all instead). There is no distributed rollback — an approved group is not atomic, already-applied members stay, and this is surfaced clearly. Each member records its own snapshot + audit row alongside group-level audit and live WebSocket progress. - Data Lifecycle Manager (AF-499, AF-519) — govern not just who reads data, but when it is retired. Admins define retention/erasure rules per datasource — target a table / column set / classification tag with a retention window plus arbitrary conditions (a structured, parameter-bound predicate builder and a JSqlParser-validated raw-
WHEREescape hatch) and an action (hard-delete, soft-delete, or pseudonymize) — with an optional cron schedule, a clustered scan job, a dry-run preview, and automatic execution through the proxy. Any user can file a GDPR/CCPA right-to-erasure request with the same rich configuration; it flows through AI-assisted scope detection and review-plan-based peer review (REVIEWER-eligible, multi-stage, no self-approval, auto-reject on timeout) before executing. Enforcement is transparent: soft-deleted rows vanish from reads,DELETEs become marker updates, and aged PII resolves to an irreversible salted hash at read time — so aggregates survive while the PII does not — all with tamper-evident proof-of-deletion audit records and a retention-adherence compliance report. - Deploy anywhere —
docker compose upfor local and small environments; Helm chart for Kubernetes production. - Infrastructure as Code — an official Terraform / OpenTofu provider (
bablsoft/accessflow) and reusable GitHub Actions + GitLab CI template manage datasources, review plans, routing / row-security / masking policies, AI configs, and notification channels declaratively over the REST API. Pipelines authenticate with a bootstrap-provisioned service-account API key. Seedocs/16-iac.md.
AccessFlow is a single Spring Boot 4 application organized as Spring Modulith modules — six logical subsystems share one process, one Postgres, and one Redis but communicate strictly through events and exposed API packages:
- Proxy — parses, validates, and executes queries against customer databases: SQL via per-datasource HikariCP pools, MongoDB / Couchbase / Redis / Cassandra / ScyllaDB / Elasticsearch / OpenSearch / DynamoDB / Neo4j via on-demand engine plugins (
engines/mongodb/,engines/couchbase/,engines/redis/,engines/cassandra/,engines/elasticsearch/,engines/dynamodb/,engines/neo4j/— per-datasource native clients behind thecore.api.QueryEngineSPI). - Workflow — review-plan state machine, approval chains, scheduled timeout auto-reject.
- AI Analyzer — Spring AI–backed adapters resolved per organization from the
ai_configrow. - Notifications — async dispatcher fanning events to Email, Slack, Discord, Telegram, Microsoft Teams, PagerDuty, and outbound webhooks.
- Audit — INSERT-only, HMAC-chained record of every domain event.
- Compliance — pre-built compliance reports and signed PDF/CSV exports over the immutable query snapshots, gated to the read-only Auditor role.
- Realtime — WebSocket fan-out for the React SPA.
For the full request flow, technology stack table, and component-level diagrams, see docs/02-architecture.md.
| Layer | Stack |
|---|---|
| Backend runtime | Java 25, virtual threads |
| Backend framework | Spring Boot 4, Spring Modulith 2, Spring Security, Spring Data JPA, Spring AI 2.0 |
| Internal database | PostgreSQL 18 |
| Migrations | Flyway |
| Target databases | SQL: PostgreSQL, MySQL, MariaDB, Oracle, Microsoft SQL Server, ClickHouse via the declarative connector catalog (one-click driver install) — plus any JDBC-compatible engine via an admin-uploaded custom driver JAR. NoSQL: MongoDB, Couchbase, Redis, Apache Cassandra, ScyllaDB, Elasticsearch, OpenSearch, Amazon DynamoDB, and Neo4j (native engine plugins, installed on demand) |
| Frontend | React 19, Vite 8, TypeScript 6, Ant Design 6, CodeMirror 6, Yjs (collaborative editing) |
| Server state | TanStack Query 5 |
| Client state | Zustand 5 |
| Cache & locks | Redis 8 (JWT refresh-token revocation, ShedLock locks for @Scheduled jobs) |
| AI backends | OpenAI, Anthropic, Ollama, any OpenAI-compatible endpoint, Hugging Face (Inference Providers router or local TGI) (admin-configurable per organization) |
| Auth | JWT RS256 + optional SAML 2.0 SSO and OAuth 2.0 / OIDC (Google, GitHub, GitHub Enterprise Server, Microsoft, GitLab, self-managed GitLab built in) |
| Observability | Micrometer Tracing + OpenTelemetry (OTLP export), Prometheus metrics (Actuator), pre-built Grafana dashboards, structured JSON logging |
| Deploy | Docker Compose, Helm 3 |
| Infrastructure as Code | Official Terraform / OpenTofu provider (Go, terraform-plugin-framework) + reusable GitHub Actions and a GitLab CI template |
Library versions in backend/pom.xml and frontend/package.json are pinned to the latest stable at the time of merge; see CLAUDE.md for the dependency-bump rule.
The only prerequisite is Docker Desktop. From a fresh clone:
git clone https://github.com/bablsoft/accessflow.git
cd accessflow
docker compose up -d # pulls Postgres + Redis + the released backend & frontend images
open http://localhost:5173 # the SPA detects the empty DB and walks you through /setupThe setup wizard creates the first organization and admin user — no .env, no key generation, no Maven, no npm.
⚠️ The rootdocker-compose.ymlembeds demo-only JWT and encryption keys so it works out of the box. Do not point it at real customer data; for anything beyond evaluation, follow the production-style configuration indocs/09-deployment.md.
For the hot-reload dev loop you'll also need:
- JDK 25 (e.g.
sdk install java 25-tem) - Node.js 20 LTS
The dev compose boots just the infrastructure (Postgres + Redis + a fake SMTP inbox at http://localhost:1080) so it can coexist with ./mvnw spring-boot:run and npm run dev:
docker compose -f backend/docker-compose-dev.yml up -d # Postgres + Redis + MailcrabThen in two more terminals:
cd backend && ./mvnw spring-boot:runcd frontend && npm install && npm run devThe API comes up on http://localhost:8080 and the SPA on http://localhost:5173. Required environment variables (DB_PASSWORD, ENCRYPTION_KEY, JWT_PRIVATE_KEY, …) are documented in docs/09-deployment.md and the env-var table in CLAUDE.md.
Tagged releases are published to GitHub Container Registry as multi-arch (linux/amd64, linux/arm64) images:
docker pull ghcr.io/bablsoft/accessflow-backend:1.2.3
docker pull ghcr.io/bablsoft/accessflow-frontend:1.2.3
# or :latestThe running backend exposes its version at GET /actuator/info (build.version); the frontend shows it under the brand mark in the sidebar. Maintainers cut a release by running the Release workflow from the Actions tab with a semver version input — see docs/09-deployment.md → Releases for what the pipeline does.
Each release also publishes a Helm chart to the repo at https://bablsoft.github.io/accessflow:
helm repo add accessflow https://bablsoft.github.io/accessflow
helm repo update
# Create the required secrets first — see charts/accessflow/README.md
helm install accessflow accessflow/accessflow \
--namespace accessflow --create-namespace \
--values my-values.yamlThe chart bundles optional bitnami/postgresql and bitnami/redis subcharts (toggle off
for production with postgresql.enabled=false / redis.enabled=false) and ships a single
Ingress that dispatches /api+/ws → backend, / → frontend.
For GitOps deployments, the chart can also seed the organization, first admin user, review
plans, AI configs, datasources, SAML, OAuth2 providers, notification channels, and system
SMTP from values.yaml (with sensitive fields routed through Kubernetes Secrets) — see
docs/09-deployment.md → Bootstrap configuration.
Full reference: charts/accessflow/README.md
and docs/09-deployment.md.
accessflow/
├── backend/ # Spring Boot 4 application (single Maven module, Spring Modulith)
│ ├── src/main/java/com/bablsoft/accessflow/
│ │ ├── core/ # Domain entities, repositories, shared service contracts
│ │ ├── proxy/ # SQL proxy engine, JDBC connection management
│ │ ├── workflow/ # Review state machine, approval chains, scheduled jobs
│ │ ├── access/ # JIT time-bound access requests + grant-expiry job
│ │ ├── ai/ # Spring AI adapters (OpenAI / Anthropic / Ollama / Hugging Face)
│ │ ├── security/ # JWT, Spring Security filters, SAML 2.0 SSO
│ │ ├── notifications/ # Email / Slack / Webhook / Discord / Telegram / MS Teams / PagerDuty dispatchers
│ │ ├── audit/ # INSERT-only, HMAC-chained audit log
│ │ ├── compliance/ # Compliance reports + signed PDF/CSV exports (AF-459)
│ │ └── mcp/ # Stateless MCP server for AI agents
│ └── pom.xml
├── engines/ # On-demand engine plugins — engines/mongodb/, engines/couchbase/, engines/redis/, engines/cassandra/, engines/elasticsearch/, engines/dynamodb/, engines/neo4j/ (shaded QueryEngine SPI jars)
├── terraform-provider/ # Terraform / OpenTofu provider (Go) — released to a dedicated terraform-provider-accessflow mirror repo
├── ci-templates/ # Reusable GitLab CI template + usage examples (GitHub Actions live in .github/actions/)
├── frontend/ # React 19 + Vite + TypeScript SPA (Ant Design 6, TanStack Query, Zustand)
├── connectors/ # Declarative connector catalog (one connector.json + logo per database)
├── e2e/ # Playwright end-to-end suite + docker-compose.e2e.yml (own npm project)
├── docs/ # Authoritative design documentation
├── website/ # Public marketing site (static HTML/CSS/JS, no build step)
├── docker-compose.yml # Local infrastructure (Postgres + Redis)
├── CLAUDE.md # Agent-facing rulebook (read before changing code)
└── README.md
| File | Description |
|---|---|
docs/01-overview.md |
Executive summary, problem statement, goals, non-goals |
docs/02-architecture.md |
System architecture, service descriptions, technology stack |
docs/03-data-model.md |
Entity schemas, columns, enums, indexes |
docs/04-api-spec.md |
REST endpoints, WebSocket events, payload examples |
docs/05-backend.md |
Modulith layout, proxy engine, workflow state machine, AI analyzer, scheduled jobs |
docs/06-frontend.md |
Frontend structure, routing, state management, SQL editor |
docs/07-security.md |
Auth, RBAC matrix, credential encryption, audit integrity |
docs/08-notifications.md |
Event types; Email, Slack, Webhook, Discord, Telegram, Microsoft Teams, and PagerDuty channel config; signed payload schema |
docs/09-deployment.md |
Docker Compose, Helm, environment-variable reference |
docs/11-development.md |
Local setup, testing strategy, coding standards, Git workflow |
docs/12-roadmap.md |
v1.0 → v2.x milestone scope |
docs/13-mcp.md |
MCP server, user API keys, exposed tools |
docs/14-connectors.md |
Declarative connector catalog — manifests, install lifecycle, release artifacts |
docs/15-engine-sdk.md |
Engine-plugin SDK — authoring guide for native (non-JDBC) engines |
docs/16-iac.md |
Infrastructure as Code — Terraform/OpenTofu provider, CI Actions, service-account API keys, registry publishing |
docs/17-api-governance.md |
API Access Governance — govern outbound REST/SOAP/GraphQL/gRPC calls (connectors, schema ingestion, permissions; review/AI pipeline planned) |
Both halves of the codebase ship with strict coverage gates enforced by CI.
Backend:
cd backend
./mvnw verify -Pcoverage # full build + tests + JaCoCo coverage
./mvnw test -Dtest=ApplicationModulesTest # Spring Modulith boundary checkJaCoCo enforces ≥ 90 % line coverage; the ApiPackageDependencyTest ArchUnit check refuses third-party imports inside any <module>/api/ package; ApplicationModulesTest refuses cross-module reaches into internal/ packages.
Frontend:
cd frontend
npm run lint
npm run typecheck
npm run test:coverage # Vitest, ≥ 90 % line / ≥ 80 % branch on included modules
npm run buildEnd-to-end:
cd e2e
npm ci
npx playwright install --with-deps chromium
npm run stack:up # builds backend + frontend, brings up Postgres + Redis, waits on healthchecks
npm test # Playwright auth-flow suite against http://localhost:5173
npm run stack:down
npm run test:setup # first-run setup-wizard spec against a no-admin variant stack (ports 5174 / 8081)See docs/11-development.md for the full testing strategy and CLAUDE.md for the per-class coverage-parity rule.
- Branches off
main:feature/AF-<n>-<kebab-summary>,fix/AF-<n>-<kebab-summary>,hotfix/AF-<n>-<kebab-summary>. Frontend-only work uses theFE-<n>prefix. - Commits use imperative mood, ≤ 72 characters, prefixed by issue:
feat(AF-58): auto-reject queries past approval_timeout_hours. - PRs require green CI (backend + frontend), at least one approval, and a description that links the issue.
- Before writing code, read
CLAUDE.mdend-to-end — it is the authoritative rulebook for module boundaries, validation parity, i18n, scheduled-job locking, and the coverage gates. The human-facing companion isdocs/11-development.md. - Update documentation in the same change —
docs/*.md, this README, and the env-var table inCLAUDE.mdmust stay in sync with what the code actually does.
Apache License 2.0.