Voice synthesis library for Text-to-Speech applications.
"jbonsai" converts sequence of full-context labels into audio waveform.
This project is a rewrite of HTS Engine in Rust language.
- Improve readability as much as possible.
- Without compromising readability,
- Improve speed.
- Keep memory consumption low.
- Can be compiled for WebAssembly.
Put the following in Cargo.toml.
[dependencies]
jbonsai = "0.4.2"This example produces a mono, 48,000 Hz (typically) PCM data saying 「盆栽」(ぼんさい; bonsai) in speech variable.
# fn main() -> Result<(), Box<dyn std::error::Error>> {
// 盆栽,名詞,一般,*,*,*,*,盆栽,ボンサイ,ボンサイ,0/4,C2
let lines = [
"xx^xx-sil+b=o/A:xx+xx+xx/B:xx-xx_xx/C:xx_xx+xx/D:xx+xx_xx/E:xx_xx!xx_xx-xx/F:xx_xx#xx_xx@xx_xx|xx_xx/G:4_4%0_xx_xx/H:xx_xx/I:xx-xx@xx+xx&xx-xx|xx+xx/J:1_4/K:1+1-4",
"xx^sil-b+o=N/A:-3+1+4/B:xx-xx_xx/C:02_xx+xx/D:xx+xx_xx/E:xx_xx!xx_xx-xx/F:4_4#0_xx@1_1|1_4/G:xx_xx%xx_xx_xx/H:xx_xx/I:1-4@1+1&1-1|1+4/J:xx_xx/K:1+1-4",
"sil^b-o+N=s/A:-3+1+4/B:xx-xx_xx/C:02_xx+xx/D:xx+xx_xx/E:xx_xx!xx_xx-xx/F:4_4#0_xx@1_1|1_4/G:xx_xx%xx_xx_xx/H:xx_xx/I:1-4@1+1&1-1|1+4/J:xx_xx/K:1+1-4",
"b^o-N+s=a/A:-2+2+3/B:xx-xx_xx/C:02_xx+xx/D:xx+xx_xx/E:xx_xx!xx_xx-xx/F:4_4#0_xx@1_1|1_4/G:xx_xx%xx_xx_xx/H:xx_xx/I:1-4@1+1&1-1|1+4/J:xx_xx/K:1+1-4",
"o^N-s+a=i/A:-1+3+2/B:xx-xx_xx/C:02_xx+xx/D:xx+xx_xx/E:xx_xx!xx_xx-xx/F:4_4#0_xx@1_1|1_4/G:xx_xx%xx_xx_xx/H:xx_xx/I:1-4@1+1&1-1|1+4/J:xx_xx/K:1+1-4",
"N^s-a+i=sil/A:-1+3+2/B:xx-xx_xx/C:02_xx+xx/D:xx+xx_xx/E:xx_xx!xx_xx-xx/F:4_4#0_xx@1_1|1_4/G:xx_xx%xx_xx_xx/H:xx_xx/I:1-4@1+1&1-1|1+4/J:xx_xx/K:1+1-4",
"s^a-i+sil=xx/A:0+4+1/B:xx-xx_xx/C:02_xx+xx/D:xx+xx_xx/E:xx_xx!xx_xx-xx/F:4_4#0_xx@1_1|1_4/G:xx_xx%xx_xx_xx/H:xx_xx/I:1-4@1+1&1-1|1+4/J:xx_xx/K:1+1-4",
"a^i-sil+xx=xx/A:xx+xx+xx/B:xx-xx_xx/C:xx_xx+xx/D:xx+xx_xx/E:4_4!0_xx-xx/F:xx_xx#xx_xx@xx_xx|xx_xx/G:xx_xx%xx_xx_xx/H:1_4/I:xx-xx@xx+xx&xx-xx|xx+xx/J:xx_xx/K:1+1-4",
];
let engine = jbonsai::Engine::load(&[
// The path to the `.htsvoice` model file.
// Currently only Japanese models are supported (due to the limitation of jlabel).
"models/hts_voice_nitech_jp_atr503_m001-1.05/nitech_jp_atr503_m001.htsvoice",
])?;
let speech = engine.synthesize(&lines)?;
println!(
"The synthesized voice has {} samples in total.",
speech.len()
);
# Ok(())
# }We compared the execution time of HTS Engine and jbonsai v0.4.1 using a very long sentence (the preamble of Japanese Constitution; about 128 sec). jbonsai performed 1.6–2.2× faster than HTS Engine. The synthesized audio was identical between HTS Engine and jbonsai.
It was also evident that in Intel x86_64, using -C target-cpu=native (and the equivalent option in C) greatly improves performance of both HTS Engine and jbonsai (See "Performance details").
Note 1: This benchmark was taken on jbonsai v0.4.1, on June 2026. If you are using newer jbonsai, rustc, LLVM etc., they can give you different result.
Note 2: This benchmark measured the time taken to synthesize the whole audio, but jbonsai can also synthesize audio in stream. If you're using this for applications where real-time performance is critical—such as reading text chat aloud in a voice chat—please try streaming synthesis as well.
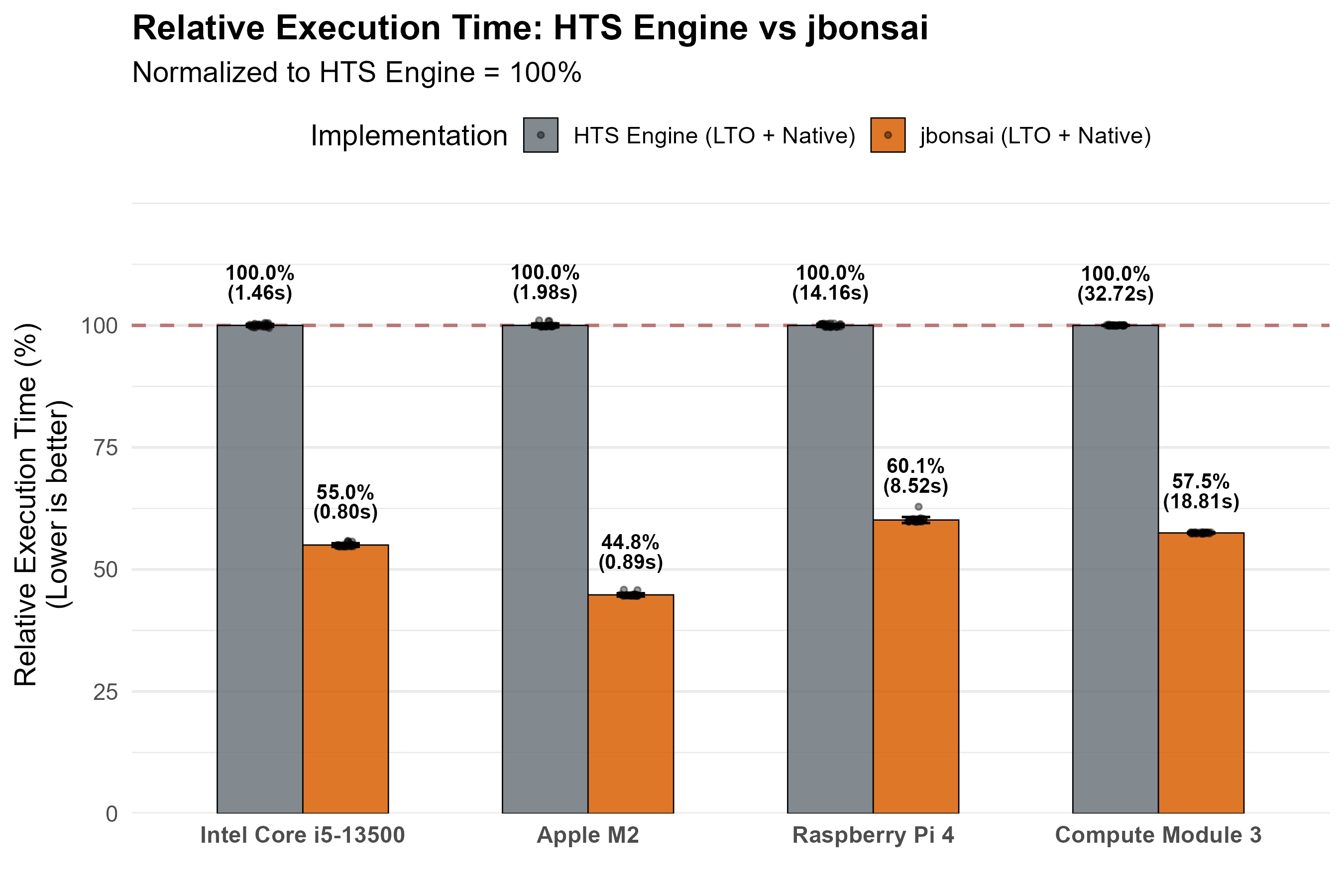
Performance Details
| Platform | Target | Mean execution time (s) |
|---|---|---|
| Intel Core i5-13500 | hts_engine_default | 1.8076678 |
| Intel Core i5-13500 | hts_engine_native | 1.4573735 |
| Intel Core i5-13500 | jbonsai_default | 0.9408125 |
| Intel Core i5-13500 | jbonsai_lto | 0.9374387 |
| Intel Core i5-13500 | jbonsai_native | 0.8016296 |
| Apple M2 | hts_engine_default | 2.0302433 |
| Apple M2 | hts_engine_native | 1.9764867 |
| Apple M2 | jbonsai_default | 0.9127072 |
| Apple M2 | jbonsai_lto | 0.8880196 |
| Apple M2 | jbonsai_native | 0.8853029 |
| Raspberry Pi 4 | hts_engine_default | 14.1488875 |
| Raspberry Pi 4 | hts_engine_native | 14.1636672 |
| Raspberry Pi 4 | jbonsai_default | 8.2963959 |
| Raspberry Pi 4 | jbonsai_lto | 8.3044165 |
| Raspberry Pi 4 | jbonsai_native | 8.5164151 |
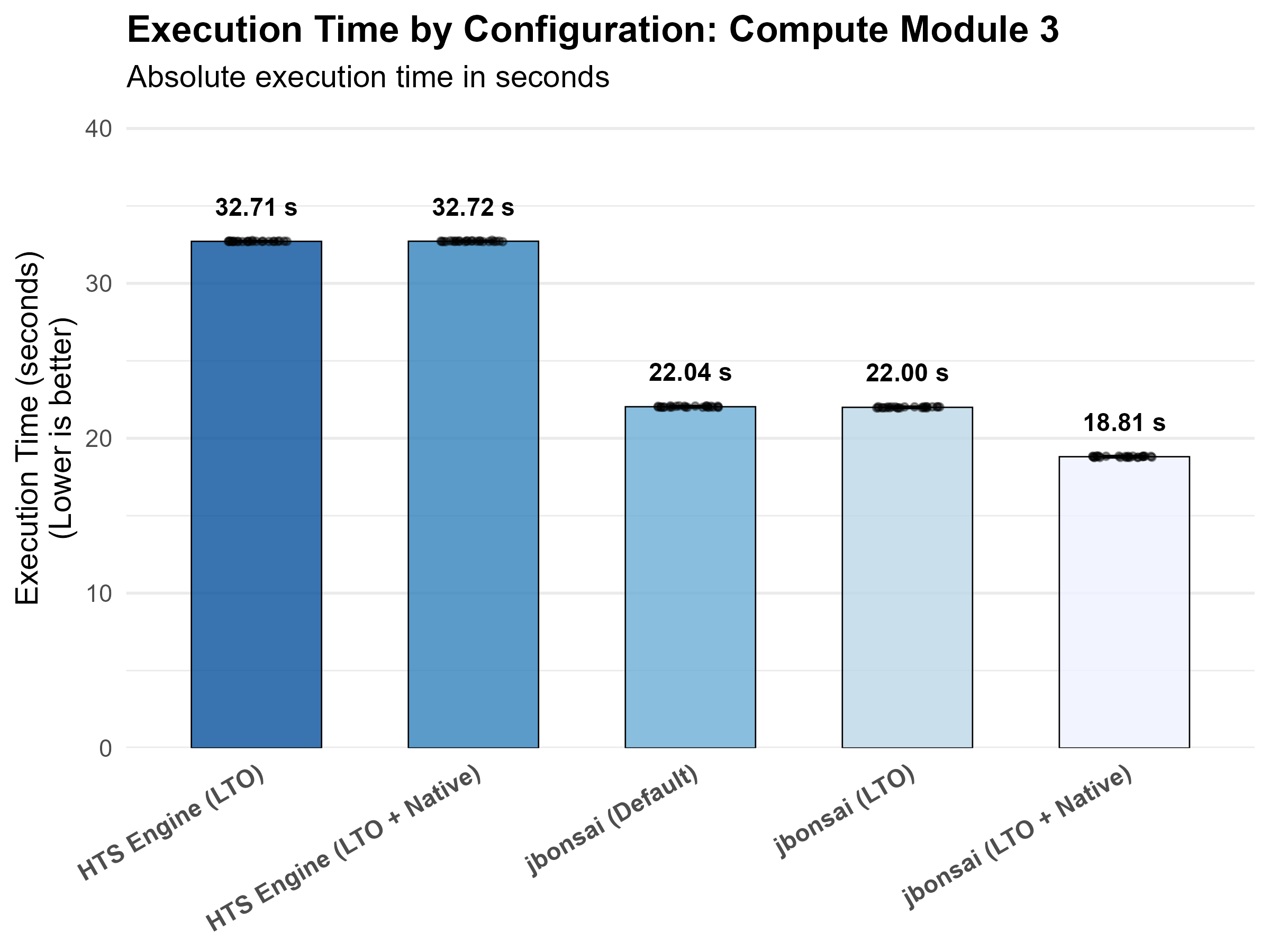
| Compute Module 3 | hts_engine_default | 32.7140591 |
| Compute Module 3 | hts_engine_native | 32.7214677 |
| Compute Module 3 | jbonsai_default | 22.0358614 |
| Compute Module 3 | jbonsai_lto | 21.9978278 |
| Compute Module 3 | jbonsai_native | 18.8089429 |
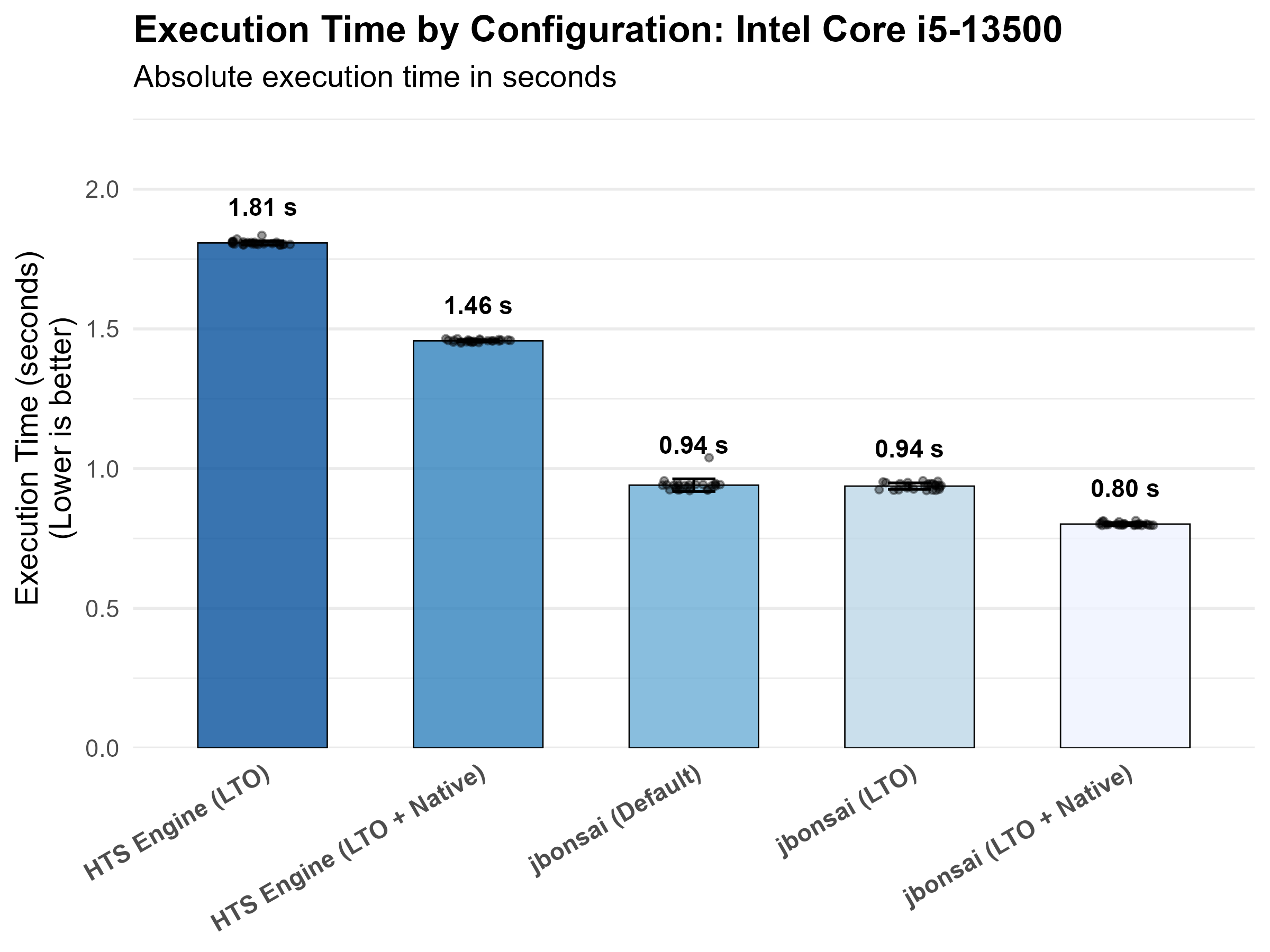
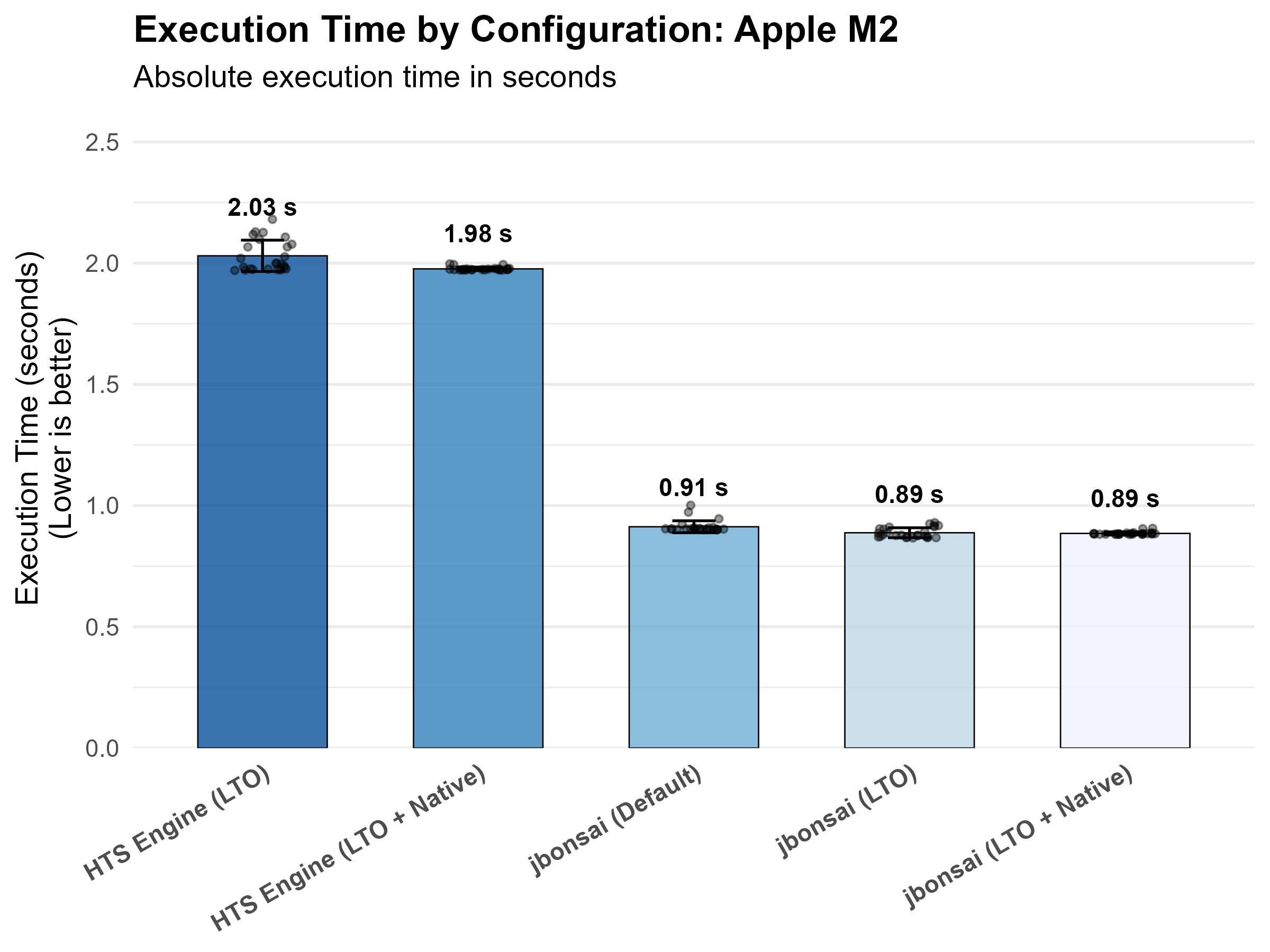
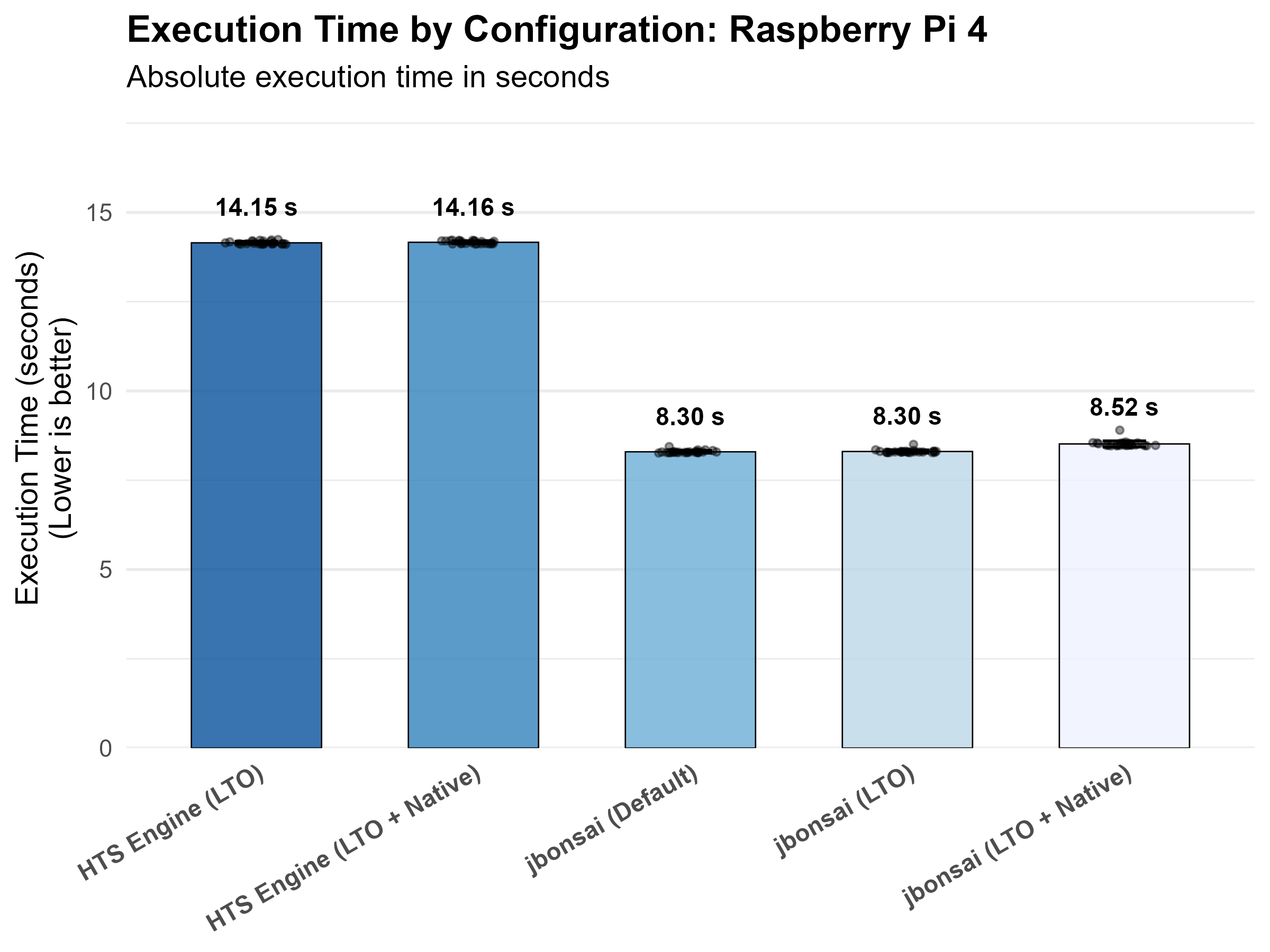
Methodology
The workload evaluates the execution efficiency of both engines by synthesizing the preamble of the Japanese Constitution using tohoku-f01-neutral, which generates an audio output of 128 seconds (6,130,960 samples, 48 kHz). To ensure functional correctness and parity before measuring performance, the raw audio outputs from the native builds of both engines were verified for bitwise identity using the cmp utility.
To capture the impact of modern toolchain optimization flags, five binary configurations were compiled and tested:
- HTS Engine (Default): Compiled using CMake with standard Release optimization flags (
-DCMAKE_BUILD_TYPE=Release -DCPU_NATIVE=OFF). - HTS Engine (Native): Compiled with hardware-specific optimizations enabled (
-DCPU_NATIVE=ON). - jbonsai (Default): Compiled using Cargo in release mode with standard compilation partitioning (
codegen-units=1) and Link-Time Optimization disabled (lto=off). - jbonsai (LTO): Compiled with Link-Time Optimization enabled (
lto=on) to facilitate cross-crate optimizations. - jbonsai (Native): Compiled with both Link-Time Optimization and native CPU targeting enabled (
-C target-cpu=native).
The benchmark suite was orchestrated via a standardized shell automation script (built upon commit 86441a40b74780afef9aa9901ac5602ffd8788fd, hts-bench/bench.sh). Performance metrics were collected using hyperfine (v1.19.0 / v1.20.0).
Each target binary was subjected to 5 warmup runs to eliminate disk-caching skew, followed by 25 timed execution runs.
Testing was conducted across four distinct hardware platforms to assess performance across different architectures (x86_64, aarch64, and Apple Silicon). Environmental adaptations were applied where necessary to accommodate platform-specific toolchains.
| Platform / Environment | CPU Architecture | Operating System | Compiler & Linker Details | Power & Governor Tuning |
|---|---|---|---|---|
| Intel Core i5-13500 (14 Cores / 20 Threads) |
x86_64 |
Manjaro Linux | Clang 22.1.5 Rustc 1.98.0-nightly (f428d123a 2026-06-19) LLD 22.1.5 |
PL2 power limit capped at 65W via sysfs;powersave scaling governor |
| Apple M2 (8 Physical Cores) |
arm64 |
macOS 26.4.1 | Homebrew Clang 22.1.7 Rustc 1.98.0-nightly (f428d123a 2026-06-19) Homebrew LLD 22.1.7 |
N/A (OS-managed) |
| Raspberry Pi 4 (Cortex-A72, 4 Cores) |
aarch64 |
Debian GNU/Linux 13 (trixie) | Clang 22.1.8 Rustc 1.98.0-nightly (1f087276b 2026-06-13) LLD 22 |
ondemand scaling governor |
| Compute Module 3 (Cortex-A53, 4 Cores) |
aarch64 |
Debian GNU/Linux 13 (trixie) | Clang 22.1.8 Rustc 1.98.0-nightly (1f087276b 2026-06-13) LLD 22 |
ondemand scaling governor |
Note on Platform-Specific Script Modifications
Intel Core i5-13500: Rust compilation configurations were adjusted to resolve the local system's default LLD linker alias via
-fuse-ld=lld. PL2 power constraints were explicitly written toconstraint_1_power_limit_uwto standardize thermal environments.Apple M2 (macOS): System metric calls were migrated from Linux-centric utilities to Darwin equivalents (
sysctl,vm_stat, andsw_vers). Cargo compilation profiles were configured using standard environment variables to enforce specific LTO behavior.
This software includes source code from:
- hts_engine API.
- Copyright (c) 2001-2014 Nagoya Institute of Technology Department of Computer Science
- Copyright (c) 2001-2008 Tokyo Institute of Technology Interdisciplinary Graduate School of Science and Engineering
BSD-3-Clause